DeepSeek V4 Pro vs Flash: Qual Escolher para Produção?
Compare DeepSeek V4 Pro vs V4 Flash para produção: trade-offs de capacidade, latência, custo e qual versão se adapta ao seu workload.

A DeepSeek lançou o V4 como dois modelos, não um: V4-Pro com 1,6T de parâmetros totais e 49B ativados, e V4-Flash com 284B totais e 13B ativados. Ambos compartilham uma janela de contexto de 1M de tokens. Ambos são de pesos abertos sob a licença MIT. Ambos são entregues na mesma superfície de API.
Isso importa porque a decisão não é mais “usar DeepSeek ou não.” É qual dos dois colocar atrás de qual endpoint. E a resposta certa raramente é “usar o Pro em todo lugar.”
Este é um guia de seleção para equipes de produtos de IA e líderes de engenharia que tentam rotear cargas de trabalho corretamente. Se você leu meu artigo anterior sobre os recursos do DeepSeek V4 para desenvolvedores de API, aquele era da era de modelo único. Este é a versão com camadas divididas.
Todos os números abaixo estão atualizados até a data de publicação. Qualquer coisa que não consigo verificar contra documentação oficial está explicitamente sinalizada.
DeepSeek V4 Pro vs Flash em Resumo
Posicionamento de cada versão (por prévia oficial)
De acordo com o próprio cartão de modelo V4-Pro da DeepSeek no Hugging Face, a divisão é intencional — não são o mesmo modelo em tamanhos diferentes. O Flash é treinado separadamente, não destilado do Pro.
Enquadramento da própria DeepSeek:
- V4-Pro — rico conhecimento de mundo superando modelos abertos, raciocínio de classe mundial em matemática/STEM/programação, mais forte em tarefas agênticas.
- V4-Flash — raciocínio “se aproxima muito” do Pro, desempenho equivalente ao Pro em tarefas de agente simples, mais fraco nas complexas. Mais barato de servir, respostas mais rápidas.
A distinção “simples vs. complexo” é toda a decisão. A DeepSeek está dizendo diretamente onde o Flash fica aquém. Não ignore isso.
Recursos compartilhados (contexto de 1M, modo de raciocínio, compatibilidade de API)
Os recursos idênticos em ambos:
- Janela de contexto de 1M de tokens em ambas as variantes, habilitada pela arquitetura de atenção híbrida da DeepSeek (CSA + HCA). De acordo com o cartão do Hugging Face, o Pro precisa de apenas 27% dos FLOPs por token e 10% do cache KV em comparação com o V3.2 com contexto de 1M.
- Três modos de esforço de raciocínio — sem raciocínio, raciocínio (alto) e Think Max. Mesmo flag de API, mesmo comportamento de superfície.
- API de Chat Completions compatível com OpenAI e suporte ao protocolo Anthropic. Mesmo
base_url, basta trocar o ID do modelo. - Licença MIT nos pesos para ambos, de acordo com os repositórios oficiais.
Se você estiver migrando entre eles, a superfície de integração não muda. Apenas o ID do modelo e a conta.
Diferenças de Capacidade
Onde divergem é em categorias específicas de avaliação — e o padrão é consistente o suficiente para construir uma regra de roteamento.
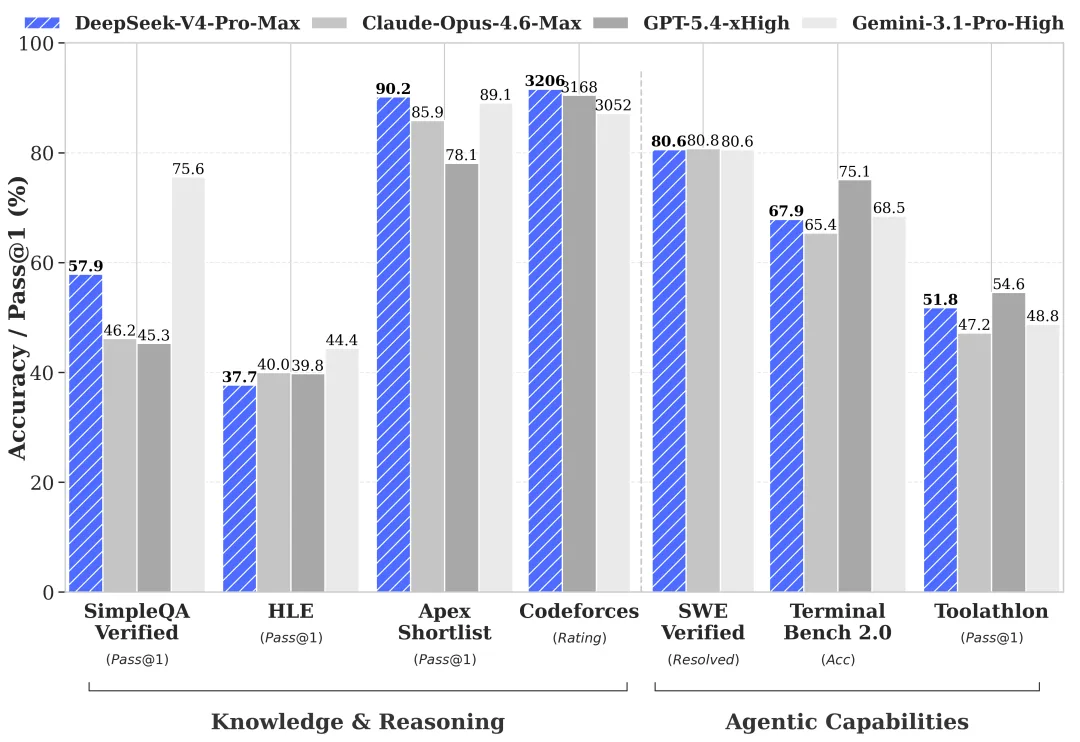
Conhecimento de mundo: Pro lidera, Flash fica atrás (por benchmarks oficiais — necessita verificação)
Os próprios benchmarks de prévia da DeepSeek, resumidos em seu cartão HF e relatório técnico, mostram que a diferença Pro/Flash é pequena na maioria das categorias de avaliação — mas ampla em alguns lugares específicos:
| Benchmark | V4-Pro | V4-Flash | Diferença |
|---|---|---|---|
| MMLU-Pro | 87,5 | 86,2 | 1,3 |
| LiveCodeBench | 93,5 | 91,6 | 1,9 |
| SWE-Verified | 80,6 | 79 | 1,6 |
| Codeforces | 3206 | 3052 | ~150 Elo |
| SimpleQA-Verified | 57,9 | 34,1 | 23,8 |
| Terminal Bench 2.0 | 67,9 | 56,9 | 11 |
Números reportados pela DeepSeek. Nenhuma replicação por terceiros existe no momento — necessita verificação antes da adoção em produção. Mas a forma da diferença é o sinal, não os dígitos exatos.
SimpleQA-Verified é recuperação factual. Terminal Bench 2.0 é uso de ferramentas em múltiplos passos. O Flash sofre uma queda real em ambos. Isso é consistente com o que a DeepSeek disse em linguagem simples: tarefas simples, tudo bem; cargas de trabalho de agente complexas, mais fraco.
Paridade de raciocínio em tarefas simples
Em programação, matemática e raciocínio delimitado, a diferença cai para 1-3 pontos. LiveCodeBench e MMLU-Pro colocam o Flash dentro da margem do Pro. Para a maioria das chamadas de inferência em um produto típico — turno de chat, geração única, uma conclusão de código, uma sumarização — o Flash não é um downgrade de qualquer forma que os usuários percebam.
Essa é a essência da proposta de valor do Flash: não é um Pro simplificado. É um modelo treinado separadamente que acaba ficando próximo do Pro no meio da distribuição de benchmarks.
Divergência em tarefas agênticas de alta complexidade
A categoria de longa duração, múltiplas ferramentas e múltiplos saltos é onde os dois se separam. Terminal Bench 2.0 e Toolathlon são as avaliações relevantes aqui. A diferença de 11 pontos no Terminal Bench não é uma margem que você pode ignorar como ruído de avaliação.
Se o seu produto é um agente de programação executando um loop de 30 passos com acesso a sistema de arquivos e shell, ou um agente de pesquisa orquestrando 5+ chamadas de ferramentas por consulta, o Flash falhará com mais frequência em lugares que são caros de depurar. Não porque o Flash seja ruim — mas porque essa é exatamente a carga de trabalho para a qual a DeepSeek construiu o Pro.
Framework de Decisão para Produção
A seleção não é “qual é melhor.” É “qual corresponde a este formato de carga de trabalho.” Três padrões funcionam bem.
Quando escolher o Pro (programação agêntica, raciocínio de longa duração, avaliação empresarial)
O Pro é a escolha certa quando qualquer um dos seguintes for verdadeiro:
- Você está executando um loop de agente de múltiplos passos (estilo Claude Code, OpenCode, qualquer coisa com uso de ferramentas + planejamento + verificação por turno).
- Sua tarefa requer recuperação factual precisa em uma longa cauda de entidades — a diferença de 23 pontos no SimpleQA prevê diferenças reais de alucinação aqui.
- Você está fazendo avaliação empresarial onde o custo de negócio de uma resposta errada excede o custo por token por ordens de magnitude.
- Você precisa de raciocínio de longa duração em um contexto genuinamente completo de 1M de tokens — os números de eficiência do Pro no contexto de 1M são a história da arquitetura aqui.
Quando escolher o Flash (classificação de alto QPS, sumarização, UX de chat)
O Flash não é a opção econômica. É a opção correta quando:
- Você está executando classificação, marcação ou extração de alto QPS — latência e custo por chamada dominam a margem de qualidade.
- Sumarização e tradução — tarefas delimitadas de passagem única onde o delta de 1-2 pontos de benchmark do Flash é invisível para os usuários.
- UX de chat interativo — a latência do primeiro token importa mais do que o percentil 99 da qualidade da resposta, e o Flash é significativamente mais rápido.
- Trabalho adjacente a embeddings: reescrita de consultas, classificação de intenção, pontuação de relevância.
Escolher o Pro aqui desperdiça 10× em tokens de saída sem ganho perceptível. Isso é uma decisão pior do que usar o Flash para um loop de agente.
Roteamento híbrido: Flash como padrão, Pro como fallback
Para a maioria dos produtos, a arquitetura certa não é nem um nem outro — são ambos, com um roteador:
- Envie cada requisição por padrão para o Flash.
- Escale para o Pro em um ou mais gatilhos explícitos: falha de chamada de ferramenta, limiar de confiança não atingido, agente de múltiplos turnos entrando em uma fase conhecidamente difícil, usuário sinaliza uma resposta como errada.
- Registre a taxa de escalada. Se <5% das requisições escalarem, o Flash está cobrindo sua carga de trabalho. Se >30%, você está em território Pro e o roteador é overhead.
Isso só funciona porque Pro e Flash compartilham a superfície de API e o flag de modo de raciocínio. Trocar entre eles no meio de uma sessão é uma mudança de uma linha na maioria dos clientes. A documentação oficial de preços da DeepSeek confirma que os IDs de modelo são irmãos, não endpoints isolados.
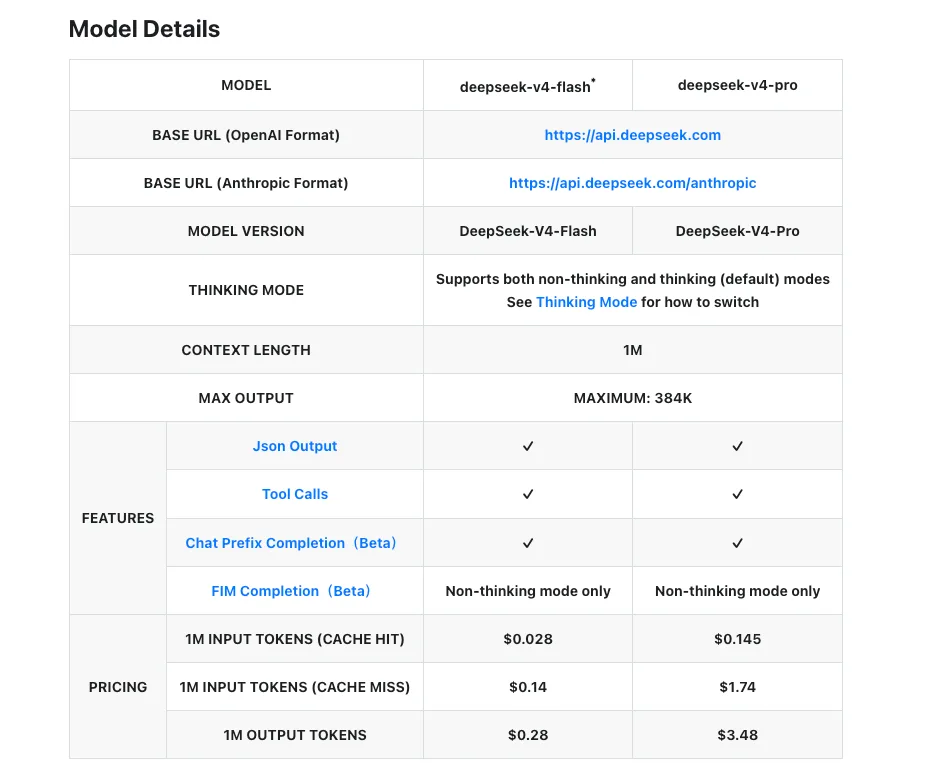
Trade-offs de Custo e Latência (na data de publicação)
Os números abaixo são da página oficial de preços da DeepSeek em 24 de abril de 2026.
| V4-Flash | V4-Pro | |
|---|---|---|
| Entrada (sem cache) | $0,14 / M tok | $1,74 / M tok |
| Entrada (com cache) | $0,028 / M tok | $0,145 / M tok |
| Saída | $0,28 / M tok | $3,48 / M tok |
| Janela de contexto | 1M tokens | 1M tokens |
| Saída máxima | 384K tokens | 384K tokens |
A proporção de entrada/saída entre as duas camadas é de aproximadamente 12× na entrada, 12× na saída nas taxas sem cache. A economia com cache compensa ainda mais — qualquer coisa com um prompt de sistema longo e estável (esquemas de ferramentas de agente, contexto RAG, exemplos few-shot) recebe 80-92% de desconto no lado da entrada. De acordo com a comparação de preços de Simon Willison, o V4-Flash atualmente está mais barato que o GPT-5.4 Nano, e o V4-Pro está mais barato que todo modelo fechado de fronteira no custo de saída.
Divulgação de latência: A DeepSeek não publicou números oficiais de latência por camada para o V4 no momento da escrita. Relatórios de terceiros sugerem que o Flash serve notavelmente mais rápido que o Pro, mas não consigo apontar para um benchmark oficial — necessita verificação assim que a prévia se estabilizar.
Limitações e o que Ainda Precisa de Verificação
Esta é uma versão de prévia. Coisas a sinalizar antes de comprometer tráfego de produção:
- Replicação de benchmarks. Todos os números acima vêm do próprio relatório técnico da DeepSeek. Leaderboards estilo Arena estão apenas começando a registrar resultados do V4. Ainda não há execuções independentes de SWE-Bench Pro ou Terminal Bench.
- Multimodal: ainda não. Ambas as variantes do V4 são apenas texto. A DeepSeek disse que o multimodal está em andamento; sem cronograma registrado.
- Contexto comercial. A cobertura da Bloomberg sobre o lançamento observa que o V4 chega em meio ao escrutínio geopolítico contínuo da DeepSeek, e algumas implantações não-chinesas têm restrições. Verifique sua postura de conformidade antes de rotear dados de usuários pela API oficial; auto-hospedar os pesos abertos é o caminho limpo se isso for uma preocupação.
- Estabilidade da prévia. O rótulo “prévia” é explícito também no cartão de modelo V4-Flash. Espere que o comportamento da API e os preços mudem.
- Janela de depreciação. Os IDs
deepseek-chatedeepseek-reasonerserão aposentados em 24 de julho de 2026. Eles atualmente roteiam para o V4-Flash. Se você está nesses IDs, já está na qualidade do Flash sem saber — migre explicitamente.
É onde meus dados terminam. Ainda acompanhando. Atualizarei quando as avaliações de terceiros alcançarem.
Perguntas Frequentes

Posso alternar entre Pro e Flash no meio de uma conversa?
Sim. Ambos compartilham a mesma superfície de API e o mesmo formato compatível com OpenAI. Alternar é uma mudança de ID de modelo no corpo da requisição. O histórico de conversa (conforme você o passa em cada chamada) é portável entre os dois.
Ambos suportam reasoning_effort?
Sim. Tanto V4-Pro quanto V4-Flash suportam os mesmos três modos de esforço de raciocínio — sem raciocínio, raciocínio e Think Max — de acordo com os cartões de modelo oficiais. O preço não muda entre os modos; você é cobrado pelos tokens gerados, e o Think Max simplesmente gera mais.
Qual versão é melhor para loops de agente estilo Claude Code?
Pro. A diferença no Terminal Bench 2.0 (67,9 vs 56,9) é o proxy mais direto para loops de shell/ferramentas em múltiplos passos, e essa é uma diferença de 11 pontos. O Flash funcionará para tarefas de agente simples, mas um loop que encadeia 10+ chamadas de ferramentas atinge exatamente a categoria onde o Flash mais regride. A própria linguagem de posicionamento da DeepSeek diz isso explicitamente — “equivalente ao Pro para tarefas de Agente simples,” não todas as tarefas de agente.
Termos de uso comercial para ambos?
Ambos são lançados sob a Licença MIT de acordo com os repositórios oficiais do Hugging Face, que permite uso comercial, modificação e redistribuição. Os pesos são auto-hospedáveis. Para uso de API hospedada, os próprios termos de serviço da DeepSeek se aplicam por cima — verifique-os para sua geografia de implantação.
As estruturas de preços são idênticas ou diferentes?
Mesma estrutura, taxas diferentes. Ambos têm camadas de entrada, entrada com cache e saída. Ambos suportam descontos de cache em prefixos repetidos. A proporção entre as taxas do Pro e do Flash é consistente — o Pro é aproximadamente 12× mais caro na saída por token. Sem preços baseados em planos ou compromissos na documentação oficial no momento da escrita.
Posts Anteriores:
- DeepSeek V4 Custo por Milhão de Tokens: Detalhamento Completo de Preços
- DeepSeek V4 Requisitos de GPU e VRAM para Auto-Hospedagem
- Claude Opus 4.7: A Alternativa de Modelo Fechado Mais Próxima
- Padrões de Fluxo de Trabalho Agêntico: Fiação de Ferramentas e Modos de Falha
- MCP em Produção: Como o Contexto de Modelo Realmente Funciona
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado
API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção
Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída
API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber