DeepSeek V4 Pro vs Flash: 프로덕션에는 어떤 것을?
DeepSeek V4 Pro와 V4 Flash를 프로덕션 관점에서 비교: 성능 트레이드오프, 지연 시간, 비용, 그리고 워크로드에 맞는 버전 선택 가이드.

DeepSeek는 V4를 하나가 아닌 두 개의 모델로 출시했습니다: V4-Pro는 총 1.6조 파라미터에 49B가 활성화되고, V4-Flash는 총 284B에 13B가 활성화됩니다. 두 모델 모두 1M 토큰 컨텍스트 창을 공유합니다. 둘 다 MIT 라이선스로 오픈 웨이트입니다. 둘 다 동일한 API 인터페이스로 제공됩니다.
이는 결정이 더 이상 “DeepSeek를 사용할지 말지”가 아니기 때문에 중요합니다. 어느 엔드포인트 뒤에 어느 모델을 배치할지가 문제입니다. 그리고 정답은 “어디서나 Pro를 사용하라”인 경우가 거의 없습니다.
이 글은 워크로드를 올바르게 라우팅하려는 AI 제품 팀과 엔지니어링 리더를 위한 선택 가이드입니다. DeepSeek V4 API 개발자 기능에 관한 이전 글을 읽으셨다면, 그것은 단일 모델 시대의 이야기였습니다. 지금은 분리된 티어 버전입니다.
아래의 모든 수치는 게시일 기준입니다. 공식 문서로 검증할 수 없는 내용은 명시적으로 표시했습니다.
한눈에 보는 DeepSeek V4 Pro vs Flash
각 버전의 포지셔닝 (공식 프리뷰 기준)
DeepSeek의 Hugging Face V4-Pro 모델 카드에 따르면, 이 분리는 의도적입니다 — 크기만 다른 동일한 모델이 아닙니다. Flash는 Pro에서 증류된 것이 아니라 별도로 학습된 모델입니다.
DeepSeek의 자체 설명:
- V4-Pro — 오픈 모델을 능가하는 풍부한 세계 지식, 수학/STEM/코딩에서 세계 최고 수준의 추론, 에이전트 작업에서 가장 강력한 성능.
- V4-Flash — 추론 능력이 Pro에 “근접”하며, 단순한 에이전트 작업에서는 Pro와 동등하지만 복잡한 작업에서는 더 약합니다. 서빙 비용이 낮고 응답이 빠릅니다.
“단순 vs 복잡” 구분이 바로 핵심입니다. DeepSeek는 Flash가 어디서 성능이 떨어지는지 직접 알려주고 있습니다. 이를 무시하지 마세요.
공통 기능 (1M 컨텍스트, 사고 모드, API 호환성)
두 모델에서 동일한 기능:
- 두 변형 모두 1M 토큰 컨텍스트 창 — DeepSeek의 하이브리드 어텐션 아키텍처(CSA + HCA)로 구현됩니다. Hugging Face 카드에 따르면, Pro는 1M 컨텍스트에서 V3.2 대비 토큰당 FLOPs의 27%만 필요하고 KV 캐시는 10%만 사용합니다.
- 세 가지 추론 노력 모드 — 비사고, 사고(고), Think Max. 동일한 API 플래그, 동일한 동작 인터페이스.
- OpenAI 호환 Chat Completions API 및 Anthropic 프로토콜 지원. 동일한
base_url, 모델 ID만 교체하면 됩니다. - 두 모델 모두 가중치에 MIT 라이선스 — 공식 저장소 기준.
두 모델 간 마이그레이션 시 통합 인터페이스는 변경되지 않습니다. 모델 ID와 비용만 달라집니다.
능력 차이
두 모델이 갈리는 지점은 특정 평가 카테고리이며, 패턴이 일관되어 라우팅 규칙을 만들 수 있습니다.
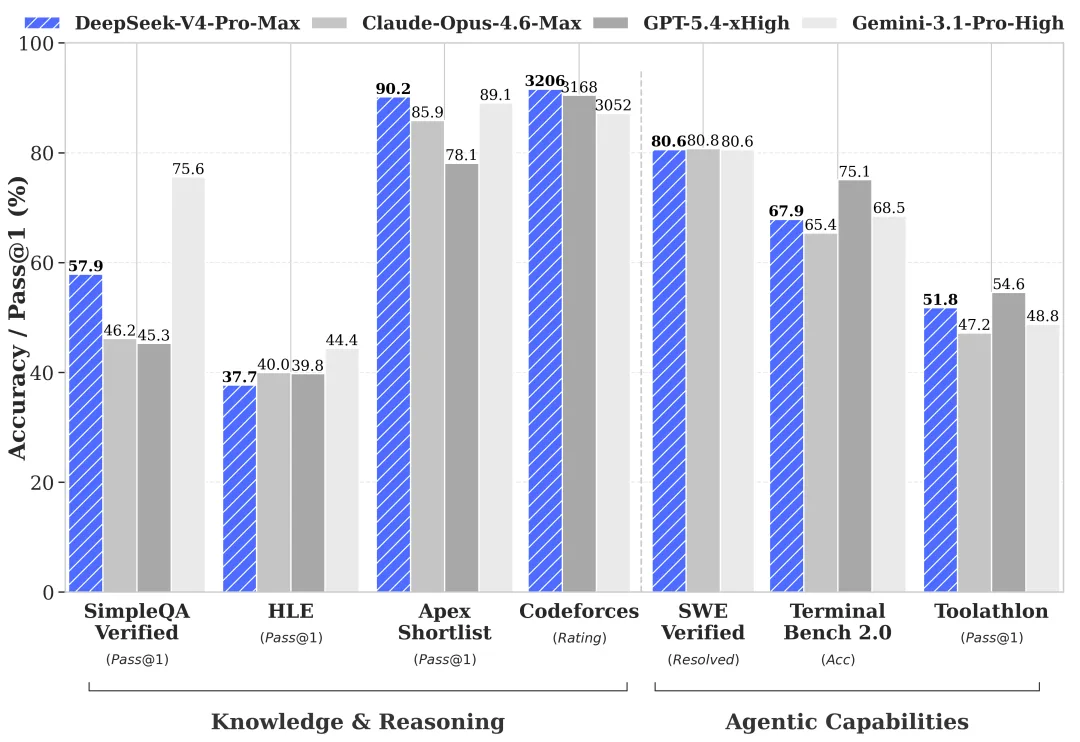
세계 지식: Pro가 앞서고, Flash가 뒤처짐 (공식 벤치마크 기준 — 검증 필요)
DeepSeek의 자체 프리뷰 벤치마크(HF 카드와 기술 보고서에서 요약)에 따르면, Pro/Flash 격차는 대부분의 평가 카테고리에서 좁지만 몇 가지 특정 부분에서는 큽니다:
| 벤치마크 | V4-Pro | V4-Flash | 격차 |
|---|---|---|---|
| MMLU-Pro | 87.5 | 86.2 | 1.3 |
| LiveCodeBench | 93.5 | 91.6 | 1.9 |
| SWE-Verified | 80.6 | 79 | 1.6 |
| Codeforces | 3206 | 3052 | ~150 Elo |
| SimpleQA-Verified | 57.9 | 34.1 | 23.8 |
| Terminal Bench 2.0 | 67.9 | 56.9 | 11 |
수치는 DeepSeek이 보고한 것입니다. 현재 시점에서 제3자 검증이 없습니다 — 프로덕션 도입 전 검증이 필요합니다. 하지만 신호는 정확한 수치가 아닌 격차의 형태입니다.
SimpleQA-Verified는 사실 기억입니다. Terminal Bench 2.0은 멀티스텝 도구 사용입니다. Flash는 두 부분에서 실질적인 타격을 받습니다. DeepSeek가 직접 말한 내용과 일치합니다: 단순한 작업은 괜찮지만, 복잡한 에이전트 워크로드에서는 더 약합니다.
단순 작업에서의 추론 동등성
코딩, 수학, 제한된 추론에서 격차는 1-3점으로 줄어듭니다. LiveCodeBench와 MMLU-Pro에서 Flash는 Pro에 근접합니다. 일반적인 제품의 대부분의 추론 호출 — 채팅 턴, 원샷 생성, 코드 완성, 요약 — 에서 Flash는 사용자가 알아챌 수 있는 방식으로 성능이 저하되지 않습니다.
이것이 Flash 가치 제안의 핵심입니다: 축소된 Pro가 아닙니다. 벤치마크 분포의 중간 범위에서 Pro에 근접하는 별도로 학습된 모델입니다.
고복잡도 워크로드에서의 에이전트 작업 격차
장기적인 멀티툴, 멀티홉 카테고리가 두 모델이 갈리는 지점입니다. Terminal Bench 2.0과 Toolathlon이 관련 평가입니다. Terminal Bench에서의 11점 격차는 평가 노이즈로 무시할 수 있는 수준이 아닙니다.
제품이 파일시스템과 셸 접근으로 30단계 루프를 실행하는 코딩 에이전트이거나, 쿼리당 5개 이상의 도구 호출을 조율하는 연구 에이전트라면, Flash는 디버깅하기 어려운 지점에서 더 자주 실패할 것입니다. Flash가 나쁜 것이 아니라 — 이것이 바로 DeepSeek가 Pro를 위해 구축한 워크로드이기 때문입니다.
프로덕션 의사결정 프레임워크
선택은 “어느 것이 더 좋은가”가 아닙니다. “어느 것이 이 워크로드 형태와 맞는가”입니다. 세 가지 기본 원칙이 잘 작동합니다.
Pro를 선택할 때 (에이전트 코딩, 장기 추론, 엔터프라이즈 평가)
다음 중 하나라도 해당하면 Pro가 적합합니다:
- 멀티스텝 에이전트 루프를 실행하는 경우 (Claude Code 스타일, OpenCode, 턴마다 도구 사용 + 계획 + 검증이 있는 모든 것).
- 긴 꼬리 엔티티에 대한 정확한 사실 기억이 필요한 경우 — 23점 SimpleQA 격차는 실제 환각 차이를 예측합니다.
- 잘못된 답변의 비즈니스 비용이 토큰당 비용을 크게 초과하는 엔터프라이즈 평가를 하는 경우.
- 진정한 1M 토큰 전체 컨텍스트에서 장기 추론이 필요한 경우 — 1M 컨텍스트에서 Pro의 효율성 수치가 아키텍처의 핵심입니다.
Flash를 선택할 때 (고QPS 분류, 요약, 채팅 UX)
Flash는 저예산 옵션이 아닙니다. 다음 경우에 올바른 선택입니다:
- 고QPS 분류, 태깅, 추출을 실행하는 경우 — 지연 시간과 호출당 비용이 품질 마진보다 중요합니다.
- 요약 및 번역 — Flash의 1-2점 벤치마크 차이가 사용자에게 보이지 않는 제한적인 단일 패스 작업.
- 인터랙티브 채팅 UX — 첫 번째 토큰 지연 시간이 답변 품질의 99번째 백분위수보다 중요하며, Flash가 의미 있게 빠릅니다.
- 임베딩 인접 작업: 쿼리 재작성, 의도 분류, 관련성 점수 매기기.
여기서 Pro를 선택하면 체감할 수 없는 이득을 위해 출력 토큰에 10배를 낭비하게 됩니다. 에이전트 루프에 Flash를 사용하는 것보다 더 나쁜 결정입니다.
하이브리드 라우팅: Flash 기본, Pro 폴백
대부분의 제품에서 올바른 아키텍처는 둘 중 하나가 아닌 — 라우터를 통해 둘 다 사용하는 것입니다:
- 모든 요청을 Flash로 기본 처리합니다.
- 하나 이상의 명시적 트리거에서 Pro로 에스컬레이션합니다: 도구 호출 실패, 신뢰 임계값 미달, 알려진 어려운 단계에 진입하는 멀티턴 에이전트, 사용자가 답변을 잘못된 것으로 표시.
- 에스컬레이션 비율을 로깅합니다. 요청의 5% 미만이 에스컬레이션되면 Flash가 워크로드를 커버하고 있습니다. 30% 초과이면 Pro 영역이고 라우터가 오버헤드입니다.
Pro와 Flash가 API 인터페이스와 추론 모드 플래그를 공유하기 때문에 이것이 가능합니다. 세션 중간에 교체하는 것은 대부분의 클라이언트에서 한 줄 변경입니다. 공식 DeepSeek 가격 문서에 따르면 모델 ID가 형제 관계이지 격리된 엔드포인트가 아닙니다.
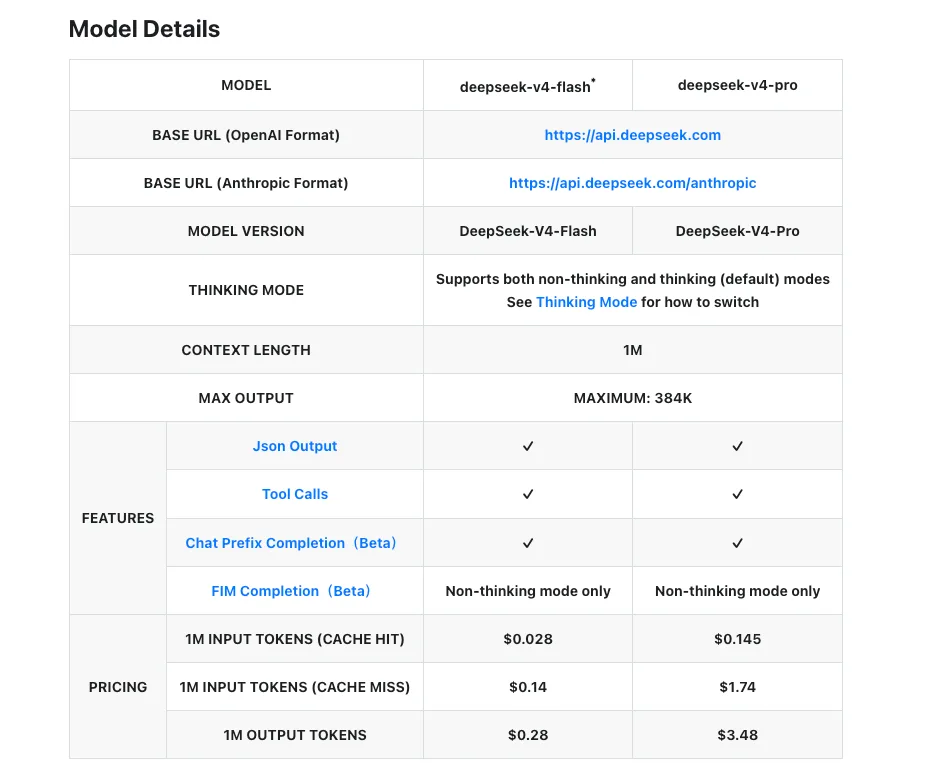
비용 및 지연 시간 트레이드오프 (게시일 기준)
아래 수치는 2026년 4월 24일 기준 DeepSeek 공식 가격 페이지에서 가져온 것입니다.
| V4-Flash | V4-Pro | |
|---|---|---|
| 입력 (캐시 미스) | $0.14 / M 토큰 | $1.74 / M 토큰 |
| 입력 (캐시 히트) | $0.028 / M 토큰 | $0.145 / M 토큰 |
| 출력 | $0.28 / M 토큰 | $3.48 / M 토큰 |
| 컨텍스트 창 | 1M 토큰 | 1M 토큰 |
| 최대 출력 | 384K 토큰 | 384K 토큰 |
두 티어 간의 입출력 비율은 캐시 미스 기준 입력과 출력 모두 약 12배입니다. 캐시 히트 경제학이 격차를 더 벌립니다 — 긴 안정적인 시스템 프롬프트(에이전트 도구 스키마, RAG 컨텍스트, 퓨샷 예시)가 있는 경우 입력 측에서 80-92% 할인을 받습니다. Simon Willison의 가격 비교에 따르면, V4-Flash는 현재 GPT-5.4 Nano보다 저렴하고, V4-Pro는 출력 비용 기준으로 모든 프론티어 클로즈드 모델보다 저렴합니다.
지연 시간 공개: DeepSeek는 작성 시점에 V4의 공식 티어별 지연 시간 수치를 발표하지 않았습니다. 제3자 보고에 따르면 Flash가 Pro보다 눈에 띄게 빠르지만, 공식 벤치마크를 제시할 수 없습니다 — 프리뷰가 안정화되면 검증이 필요합니다.
제한 사항 및 아직 검증이 필요한 사항
이것은 프리뷰 릴리스입니다. 프로덕션 트래픽을 커밋하기 전에 표시해야 할 사항:
- 벤치마크 검증. 위의 모든 수치는 DeepSeek의 자체 기술 보고서에서 가져온 것입니다. Arena 스타일 리더보드가 이제 막 V4 결과를 기록하기 시작했습니다. 아직 독립적인 SWE-Bench Pro 또는 Terminal Bench 실행이 없습니다.
- 멀티모달: 아직 없음. 두 V4 변형 모두 텍스트 전용입니다. DeepSeek는 멀티모달이 진행 중이라고 밝혔지만, 공식 타임라인은 없습니다.
- 상업적 맥락. Bloomberg의 릴리스 보도에 따르면 V4는 DeepSeek에 대한 지속적인 지정학적 검토 속에 출시되었으며, 일부 비중국 배포에는 제한이 있습니다. 공식 API를 통해 사용자 데이터를 라우팅하기 전에 컴플라이언스 상태를 확인하세요; 오픈 웨이트를 자체 호스팅하는 것이 우려가 있다면 깔끔한 경로입니다.
- 프리뷰 안정성. “프리뷰” 레이블은 V4-Flash 모델 카드에도 명시적으로 표시되어 있습니다. API 동작과 가격이 변경될 것을 예상하세요.
- 지원 중단 창.
deepseek-chat및deepseek-reasonerID는 2026년 7월 24일에 폐기됩니다. 현재 V4-Flash로 라우팅됩니다. 이 ID를 사용 중이라면 이미 모르는 사이에 Flash 품질을 사용하고 있는 것입니다 — 명시적으로 마이그레이션하세요.
여기까지가 제 데이터의 끝입니다. 계속 지켜보고 있습니다. 제3자 평가가 따라잡으면 업데이트하겠습니다.
FAQ

대화 중간에 Pro와 Flash를 전환할 수 있나요?
네. 두 모델 모두 동일한 API 인터페이스와 OpenAI 호환 형식을 공유합니다. 전환은 요청 본문의 모델 ID 변경입니다. 대화 기록(각 호출에서 전달하는 것)은 두 모델 간에 이식 가능합니다.
두 모델 모두 reasoning_effort를 지원하나요?
네. V4-Pro와 V4-Flash 모두 공식 모델 카드에 따라 동일한 세 가지 추론 노력 모드 — 비사고, 사고, Think Max — 를 지원합니다. 모드 간에 가격은 변경되지 않습니다; 생성된 토큰 기준으로 청구되며, Think Max는 더 많이 생성할 뿐입니다.
Claude Code 스타일 에이전트 루프에 어느 버전이 더 적합한가요?
Pro입니다. Terminal Bench 2.0 격차(67.9 vs 56.9)가 멀티스텝 셸/도구 루프에 대한 가장 직접적인 지표이며, 이는 11점 차이입니다. Flash는 단순한 에이전트 작업에서는 작동하지만, 10개 이상의 도구 호출을 연결하는 루프는 Flash가 가장 많이 퇴보하는 카테고리에 정확히 해당합니다. DeepSeek의 자체 포지셔닝 언어가 이를 명시적으로 말합니다 — “단순한 에이전트 작업에서는 Pro와 동등”하지만, 모든 에이전트 작업에서 그런 것은 아닙니다.
두 모델의 상업적 사용 조건은?
공식 Hugging Face 저장소에 따르면 두 모델 모두 상업적 사용, 수정, 재배포를 허용하는 MIT 라이선스로 출시되었습니다. 가중치는 자체 호스팅이 가능합니다. 호스팅된 API 사용의 경우, 그 위에 DeepSeek의 자체 서비스 약관이 적용됩니다 — 배포 지역에 맞게 확인하세요.
가격 구조가 동일한가요, 다른가요?
구조는 동일하지만 요율이 다릅니다. 둘 다 입력, 캐시 히트 입력, 출력 티어가 있습니다. 둘 다 반복되는 프리픽스에 대한 캐시 할인을 지원합니다. Pro와 Flash 요율 간의 비율은 일관됩니다 — Pro는 토큰당 출력 기준으로 약 12배 더 비쌉니다. 작성 시점의 공식 문서에는 플랜 티어 또는 커밋 기반 가격 책정이 없습니다.
이전 포스트:





