GLM-5V-Turbo:2026年に開発者が知っておくべきこと
GLM-5V-TurboはZ.aiのビジョンコーディングモデルです。2026年のAPI、料金、制限、実際のユースケースについて開発者が知っておくべきことをまとめました。

先週、同僚がスクリーンショットを送ってきた。左側にデザインモックアップ、右側にほぼピクセル単位で忠実に再現されたHTMLが並んでいた。「GLM-5V-Turbo がワンパスでこれをやった」とキャプションに書いてあった。私はそれを頭の片隅に置いて先に進んだ。ところが、エージェント型ワークフローツールと同じ文脈で繰り返し言及されるのを見かけるようになり、このモデルが何であり、何でないのかを実際に調べてみることにした。
これが私が見つけたことだ。製品推薦を求める人のためではなく、エージェント型コーディングのユースケースに向けたマルチモーダルモデルを評価している開発者向けに書かれたものである。
GLM-5V-Turboとは何か?
Z.ai(Zhipu AI)とGLMモデルファミリー
GLM-5V-Turboはビジョン言語モデルで、国際的にはZ.aiというブランドで展開しているZhipu AIが2026年4月1日にリリースした。Zhipuは北京を拠点とするAI研究所で、2026年1月から香港証券取引所に上場しており、中国で最も活発な基盤モデルメーカーの一つだ。彼らのGLMシリーズは急速に進化している:2025年7月のGLM-4.5、12月のGLM-4.7、2026年2月のGLM-5、そして4月のマルチモーダル版という流れだ。
GLM-5V-Turboは、このファミリーで初めてネイティブなマルチモーダルエージェントとして構築されたモデルだ。つまり、視覚機能が後付けで追加されたのではなく、最初からアーキテクチャに組み込まれていた。この違いが、モデルが実際に得意とすることに影響している。
GLM-5V-TurboがGLM-4VおよびGLM-5と異なる点
GLM-4Vは画像入力を処理した。GLM-5はテキストコーディングと推論を改善した。GLM-5V-Turboは、マルチモーダル入力(画像、動画、テキスト)をエージェント指向の出力——ツール呼び出し、タスク分解、GUI操作——と組み合わせる。CogViTという新しいビジュアルエンコーダを中心に構築され、30以上のタスクタイプにわたる強化学習を使用し、より高速な推論のためにINT8量子化を実行する。
この位置づけは意図的に絞り込まれている。これはGLM-5の汎用アップグレードではない。視覚入力から始まってコードまたは構造化されたアクションで終わるタスク向けの専門モデルだ。
コア機能
デザインからコードへ、UIの生成
主要機能は、UIデザインを動作するフロントエンドコードとして再現することだ。 モックアップ——スクリーンショット、Figmaエクスポート、手書きスケッチ——をモデルに与えると、HTML、CSS、場合によってはJavaScriptを生成する。Z.aiの自社テストでは、GLM-5V-TurboはDesign2Codeベンチマークで94.8を記録し、Claude Opus 4.6の77.3を上回った。独立したテストでこのベンチマークが検証されれば(詳細は後述)、これは意義深い差だ。
実際には、フロントエンドのスキャフォールディングに最も役立つ。デザイン仕様を初期コンポーネントコードに変換したり、移行プロジェクトで既存のUIレイアウトを再現したり、参照画像からバリエーションを生成したりする用途だ。
GUIエージェントとエージェント型ワークフローのサポート
静的なデザインの再現を超えて、このモデルはGUIエージェントタスクをサポートする——ブラウザインターフェースのナビゲーション、画面からの構造化データ抽出、視覚的な状態を含むマルチステップワークフローの実行だ。OpenRouterのモデルページでは、「perceive(知覚)→ plan(計画)→ execute(実行)の完全なループを完成させるために構築されている」と説明されており、Z.aiが引用するAndroidWorldとWebVoyagerのベンチマーク結果は、合成テストだけでなく実世界のGUIナビゲーションを処理できることを示唆している。
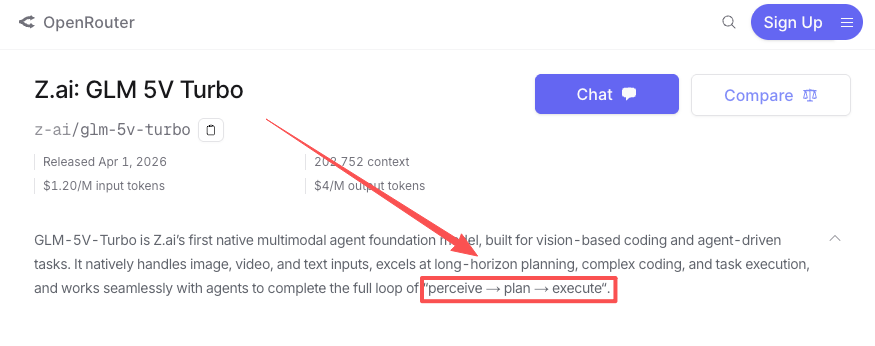
視覚レイヤーを含むエージェント型ワークフロー——フォーム入力自動化、UIテストエージェント、画面からアクションへのパイプライン——を構築しているチームにとって、このモデルは実用的な可能性を持っている。GLM-5V-Turboのツール呼び出し改善(GLM-5-Turboから継承・拡張)は、エージェントループでの呼び出し失敗を減らすために明示的に設計されている。
マルチモーダル入力処理
このモデルは画像、短い動画クリップ、テキストを同じコンテキストで受け付ける。動画入力により、画面録画や製品ウォークスルーへのユースケースが広がる——モデルは視覚的に追跡しながら、見たものからドキュメントやアクションプランを生成できる。コンテキストウィンドウは202,752トークンで、最大出力は131,072トークン。Z.aiの公式料金ページで確認済みだ。
APIアクセスと料金
APIを通じたGLM-5V-Turboへのアクセス方法
このモデルはOpenAI互換インターフェースを持つZ.aiのAPIを通じて利用できる。認証は標準的なAPIキーパターンに従う——z.aiで登録し、キーを生成し、既存のツールに設定する。
APIはファンクションコール、ストリーミング、構造化出力をサポートしており、GLM-5-Turboと同じ機能セットに視覚入力が追加されている。
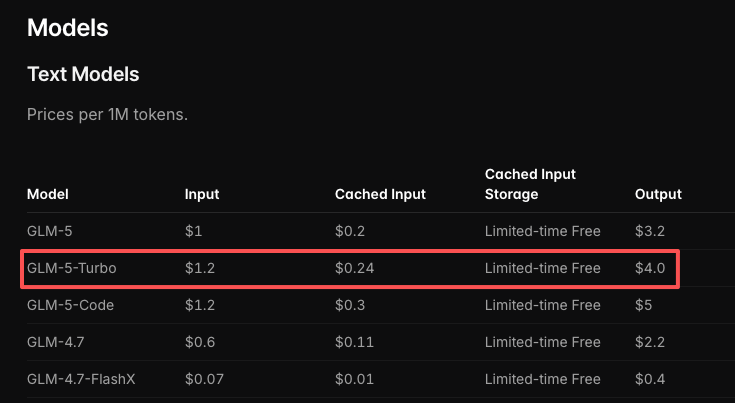
料金:入力・出力トークンコスト
| GLM-5V-Turbo | GLM-5-Turbo | GLM-5 | |
|---|---|---|---|
| 入力(100万トークンあたり) | $1.20 | $1.20 | $1.00 |
| 出力(100万トークンあたり) | $4.00 | $4.00 | $3.20 |
| キャッシュ済み入力 | $0.24 | $0.24 | $0.20 |
数値は2026年4月時点のZ.ai公式料金ページから引用。本番環境の予算計画前に直接確認すること——Z.aiは以前のモデルリリースで料金を調整したことがある。
参考として:Claude Opus 4.6は入力$5/M、出力$25/Mだ。GPT-4oは$2.50/$10。$1.20/$4のGLM-5V-Turboは、出力量が控えめな視覚処理ヘビーなワークロードにとって意味のあるコスト差がある。
コンテキストウィンドウと出力制限
- コンテキストウィンドウ: 202,752トークン
- 最大出力: 131,072トークン
どちらも十分な量だ。ほとんどのデザインからコードへのタスクやGUIエージェントタスクでは、この制限に達することはない。長い動画シーケンスや非常に大きなデザインファイルでは達する可能性があるので、コミットする前に実際の入力でテストする価値がある。
適している場面(そうでない場面)
強み:ビジュアルコーディング、デザイン再現
GLM-5V-Turboの実用的な優位性は特定の用途にある:何かを見てそこからコードを生成するタスクだ。デザインアセットからのフロントエンドスキャフォールディング、UIコンポーネントの抽出、スクリーンショットからHTML、画面録画の分析。パイプラインが視覚的なアーティファクトから始まってコードで終わるなら、現在のソリューションと比較してベンチマークする価値がある。
エージェント型ワークフローのサポートは本物の追加機能だ。ツール呼び出しの安定性は本番エージェントループで重要だ——呼び出し失敗はチェーンを壊してリトライを必要とする。Z.aiがGLM-5V-Turboでこの点に明示的に注力しているのは、エージェントを構築している誰もが見てきた同じ失敗パターンを彼らも経験したからだろう。
制限:純粋なテキストバックエンドコーディング、汎用推論
ここで明確にする価値がある部分だ。GLM-5V-Turboは、バックエンドコーディング、リポジトリ探索、汎用推論タスクにおけるClaudeやGPT-4oの直接の競合ではない。それらのカテゴリでは、Z.ai自身の比較によるとClaude Opus 4.6がすべてにおいてリードしている——そしてそれは自社モデルに有利な主張をしている会社が言っていることだ。
コーディング作業が主にテキスト入力・テキスト出力——ロジックのデバッグ、API統合の記述、バックエンドコードのリファクタリング——であれば、同じ価格でGLM-5やGLM-5-Turboのようなテキスト専用モデルの方が適している。視覚エンコーダの追加は、視覚入力を必要としない問題には役立たない。
使うべき人、スキップすべき人
評価する価値がある場合:
- デザインアセットから始まるフロントエンドツールを構築している
- 視覚的な状態を持つGUIエージェントワークフローを実行している
- 画像からコードへのタスクでGPT-4VやClaudeより安価な代替を探している
- エージェントパイプラインでマルチモーダル入力をテストしている
おそらくスキップすべき場合:
- 純粋なテキストコーディング——バックエンド、CLIツール、API開発——に取り組んでいる
- コード生成と並んで強力な汎用推論が必要
- データ居住制約の下で運用している(Z.aiは中国の企業であり、コンプライアンス要件に照らしてプライバシーポリシーを確認すること)
ベンチマークの主張——何を真剣に受け取るべきか
Design2Codeのパフォーマンス
Z.aiはGLM-5V-TurboがDesign2Codeで94.8を記録し、Claude Opus 4.6の77.3を上回ったと報告している。これらはZ.ai自身の測定値だ。本稿執筆時点では、独立した評価機関が裏付け結果を公表していない。それは数字が間違っているという意味ではない——まだストレステストされていないという意味だ。
Design2Codeはベンチマークとして、生成されたHTML/CSSが参照モックアップをピクセル単位・構造的にどの程度忠実に再現するかを測定する。UIの再現という特定のタスクに対する合理的な代理指標だ。一般的なコーディング品質、アーキテクチャの判断、実世界の本番環境への対応度の代理指標ではない。
差は方向性のシグナルとして信頼できるほど大きい。結論としてではなく、テストする理由として扱うべきだ。
純粋なテキストコーディング比較の注意点
Z.aiのドキュメントは、純粋なテキストコーディングベンチマークでGLM-5V-TurboがClaudeに劣ることを認めている。この率直さは有用だ。モデルの位置づけが正直であることを意味している:これは汎用コーディングのアップグレードではなく、視覚ファーストのツールだ。GLM-5V-Turboがフロンティアテキストモデルと広く競合すると主張する比較は、会社が実際に主張していることを誤読している。
FAQ
Q: GLM-5V-TurboはAPIで利用できますか?
はい。Z.aiのネイティブAPI(OpenAI互換)とOpenRouterを通じて利用できます。標準的なAPIキーの設定で、ファンクションコールとストリーミングをサポートしています。
Q: GLM-5V-Turboの料金はいくらですか?
2026年4月時点で、入力トークン100万件あたり$1.20、出力トークン100万件あたり$4.00です。本番環境での使用前にdocs.z.ai/guides/overview/pricingで確認してください。
Q: GLM-5V-TurboはGPT-4oやClaudeとコーディング面でどう比較されますか?
デザインからコードへの視覚的なUIタスクについて:Z.aiのベンチマーク(自己報告)では両者を上回るとされています。純粋なテキストコーディングとバックエンド作業については:Claude Opus 4.6がリードしています。この比較は視覚ドメインでのみ成立します。
Q: GLM-5V-Turboは動画入力をサポートしていますか?
はい——画像やテキストと同じコンテキストで短い動画クリップを受け付けます。画面録画やウォークスルーベースのドキュメント生成に役立ちます。
Q: レート制限とコンテキストウィンドウはどのくらいですか?
コンテキストウィンドウは202,752トークン、最大出力は131,072トークンです。レート制限は公式ドキュメントに公表されていません——Z.aiは以前のモデルリリースでキャパシティの問題が発生したことがあるため、本番アーキテクチャにコミットする前に実際の負荷でスループットをテストしてください。
デザインからコードへの変換は真に有用なタスクカテゴリであり、汎用モデルの付随機能としてではなく、一級の問題として扱うモデルを持つことは合理的なエンジニアリング上の判断だ。GLM-5V-Turboが特定のパイプラインでその期待に応えるかどうかは、自分自身のテストデータだけが答えを出せる。
ベンチマーク数値は見る価値がある。独立した検証はまだ待ちの状態だ。
料金と仕様は2026年4月2日時点のZ.ai公式ドキュメントに対して確認済み。特に断りのない限り、すべてのベンチマーク数値はZ.aiの自己報告データである——独立して検証されるまでは予備的なものとして扱うこと。
Previous Posts:




