DeepSeek V4 Pro対Flash:本番環境ではどちらを選ぶべきか?
本番環境向けDeepSeek V4 ProとV4 Flashを比較:機能のトレードオフ、レイテンシ、コスト、そしてどちらのバージョンがワークロードに適しているかを解説します。

DeepSeekはV4を1つではなく2つのモデルとしてリリースしました:V4-Pro(総パラメータ数1.6T、アクティベーション49B)とV4-Flash(総パラメータ数284B、アクティベーション13B)。両モデルともコンテキストウィンドウは100万トークン。両モデルともMITライセンスのオープンウェイト。両モデルとも同一のAPIサーフェスで提供されます。
これが重要なのは、「DeepSeekを使うか使わないか」という判断ではなくなったからです。どちらのモデルをどのエンドポイントに配置するかという判断です。「Pro一択」が正解であることはほとんどありません。
これはAIプロダクトチームとエンジニアリングリードがワークロードを正しくルーティングするための選択ガイドです。以前のDeepSeek V4 APIデベロッパー向け機能の記事はシングルモデル時代のものでした。こちらは二層分割版です。
以下の数字はすべて公開日時点のものです。公式ドキュメントで確認できないものは明示的にフラグを立てています。
DeepSeek V4 Pro vs Flash:概要比較
各バージョンの位置づけ(公式プレビューより)
DeepSeekのHugging Face上のV4-Proモデルカードによると、この分割は意図的なものです。サイズが異なる同一モデルではありません。FlashはProから蒸留されたものではなく、別途学習されています。
DeepSeek自身の説明:
- V4-Pro — オープンモデルを凌ぐ豊富な世界知識、数学・STEM・コーディングにわたるワールドクラスの推論能力、エージェント型タスクで最強。
- V4-Flash — 推論能力はProに「ほぼ匹敵」、シンプルなエージェントタスクではProと同等のパフォーマンス、複雑なタスクでは劣る。提供コストが低く、レスポンスが速い。
「シンプルなタスクと複雑なタスク」という区別がすべての判断の核心です。DeepSeekはFlashがどこで限界を迎えるかを直接示しています。無視してはなりません。
共通機能(100万トークンコンテキスト、思考モード、API互換性)
両モデルで同一の機能:
- 100万トークンのコンテキストウィンドウ:DeepSeekのハイブリッドアテンションアーキテクチャ(CSA + HCA)により両バリアントで利用可能。Hugging Faceカードによると、Proは100万トークンのコンテキストでV3.2比でトークンあたりFLOPsの27%のみ、KVキャッシュの10%のみが必要。
- 3段階の推論努力モード — 非思考、思考(高)、Think Max。同一APIフラグ、同一動作サーフェス。
- OpenAI互換Chat Completions APIとAnthropicプロトコルのサポート。同じ
base_urlで、モデルIDを切り替えるだけ。 - 公式リポジトリによると、両モデルともウェイトにMITライセンス。
両モデル間の移行では、インテグレーションサーフェスは変わりません。変わるのはモデルIDと料金のみ。
性能の違い
両者が分岐するのは特定の評価カテゴリです。そのパターンはルーティングルールを構築できるほど一貫しています。
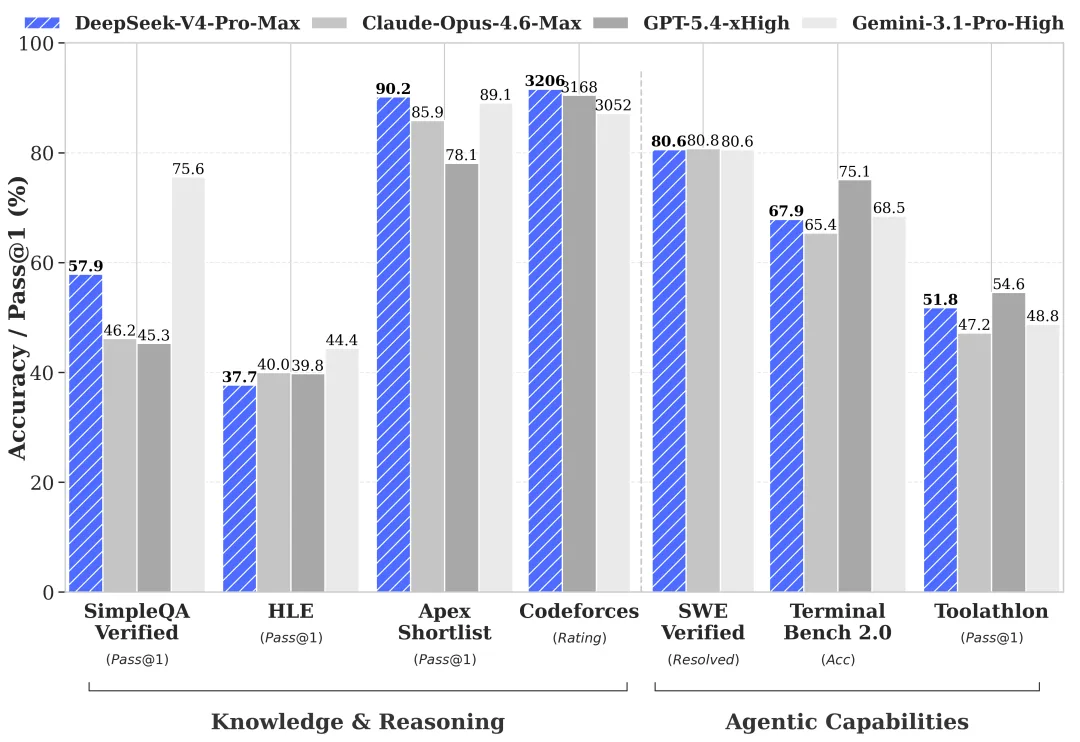
世界知識:Proがリード、Flashが遅れる(公式ベンチマークより — 要検証)
DeepSeekのHFカードと技術レポートにまとめられた独自プレビューベンチマークによると、Pro/Flashの差はほとんどの評価カテゴリで僅差ですが、特定の箇所では大きく開きます:
| ベンチマーク | V4-Pro | V4-Flash | 差 |
|---|---|---|---|
| MMLU-Pro | 87.5 | 86.2 | 1.3 |
| LiveCodeBench | 93.5 | 91.6 | 1.9 |
| SWE-Verified | 80.6 | 79 | 1.6 |
| Codeforces | 3206 | 3052 | 約150 Elo |
| SimpleQA-Verified | 57.9 | 34.1 | 23.8 |
| Terminal Bench 2.0 | 67.9 | 56.9 | 11 |
数字はDeepSeekが報告したもの。現時点でサードパーティによる再現は存在しません — 本番採用前に要検証。ただし、差の形状が正確な数字よりも重要なシグナルです。
SimpleQA-Verifiedは事実の想起能力です。Terminal Bench 2.0はマルチステップのツール使用です。Flashは両方で実際に大きなダメージを受けています。これはDeepSeekがわかりやすい言葉で述べたことと一致しています:シンプルなタスクは問題なし、複雑なエージェントワークロードは弱い。
シンプルなタスクでの推論の同等性
コーディング、数学、制約された推論では、差は1〜3ポイントに縮まります。LiveCodeBenchとMMLU-ProではFlashがProに肉薄しています。一般的なプロダクトにおける典型的な推論呼び出し — チャットターン、ワンショット生成、コード補完、要約 — ではFlashはユーザーが気づくような意味での格下ではありません。
これがFlashの価値提案の核心です:Proを機能削減したものではなく、ベンチマーク分布の中間域でProに近い結果を出す、別途学習されたモデルです。
高複雑度ワークロードでのエージェントタスクの分岐
長期間・マルチツール・マルチホップカテゴリが両者の分かれ目です。Terminal Bench 2.0とToolathlonがここで関連する評価です。Terminal Benchの11ポイント差は評価ノイズとして無視できるマージンではありません。
プロダクトがファイルシステムとシェルアクセスを持つ30ステップループで動作するコーディングエージェント、またはクエリごとに5つ以上のツール呼び出しを調整するリサーチエージェントであれば、Flashはデバッグにコストがかかる箇所でより多く失敗します。Flashが悪いからではなく — これはまさにDeepSeekがProのために構築したワークロードだからです。
本番環境での判断フレームワーク
選択は「どちらが優れているか」ではなく、「このワークロードの形状に合うのはどちらか」です。3つのデフォルトが有効です。
Proを選ぶ場合(エージェント型コーディング、長期間推論、エンタープライズ評価)
以下のいずれかに該当する場合、Proが正しい選択です:
- マルチステップのエージェントループを実行している(Claude Codeスタイル、OpenCode、ターンごとにツール使用 + 計画 + 検証がある任意のもの)。
- エンティティの長い末尾にわたる正確な事実の想起が必要 — 23ポイントのSimpleQAの差がここでの実際のハルシネーションの違いを予測します。
- エンタープライズ評価で、誤答のビジネスコストがトークンあたりのコストを桁違いに上回る場合。
- 真に100万トークン全体にわたる長期間推論が必要 — 100万トークンコンテキストでのProの効率数値がここでのアーキテクチャの話です。
Flashを選ぶ場合(高QPSの分類、要約、チャットUX)
Flashは予算オプションではありません。以下の場合に正しい選択です:
- 高QPSの分類、タグ付け、または抽出を実行している — レイテンシとコール単価が品質マージンを上回る。
- 要約と翻訳 — 制約された単一パスのタスクで、Flashの1〜2ポイントのベンチマーク差はユーザーには見えない。
- インタラクティブなチャットUX — 最初のトークンのレイテンシが回答品質の99パーセンタイルより重要で、Flashは意味のある速さがある。
- 埋め込みに隣接した作業:クエリの書き換え、インテント分類、関連性スコアリング。
ここでProを選ぶと、認識できる利益なしに出力トークンで10倍を無駄にします。エージェントループでFlashを使うよりも悪い判断です。
ハイブリッドルーティング:Flashをデフォルト、Proをフォールバックに
ほとんどのプロダクトにとって、正しいアーキテクチャはどちらか一方ではなく、ルーターを伴う両方の組み合わせです:
- すべてのリクエストをデフォルトでFlashに振り向ける。
- 一つ以上の明示的なトリガーでProにエスカレート:ツール呼び出し失敗、信頼度しきい値を下回った、マルチターンエージェントが既知の難易度の高いフェーズに入った、ユーザーが回答を誤りとフラグした。
- エスカレーション率をログに記録する。 リクエストの5%未満がエスカレートする場合、Flashがワークロードをカバーしています。30%以上の場合、Pro領域にあり、ルーターはオーバーヘッドです。
これが機能するのは、ProとFlashがAPIサーフェスと推論モードフラグを共有しているからです。セッション途中での切り替えは、ほとんどのクライアントで1行の変更です。DeepSeekの公式料金ドキュメントでは、モデルIDは兄弟であり、サイロ化されたエンドポイントではないことを確認しています。
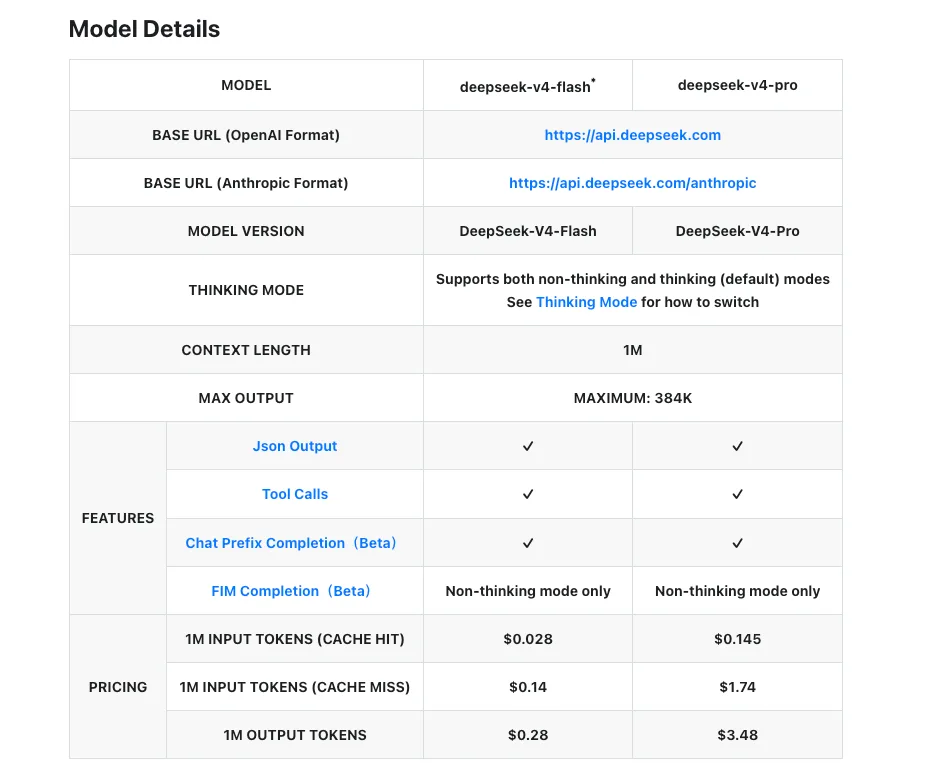
コストとレイテンシのトレードオフ(公開日時点)
以下の数字は2026年4月24日時点のDeepSeekの公式料金ページからのものです。
| V4-Flash | V4-Pro | |
|---|---|---|
| 入力(キャッシュミス) | $0.14 / M tok | $1.74 / M tok |
| 入力(キャッシュヒット) | $0.028 / M tok | $0.145 / M tok |
| 出力 | $0.28 / M tok | $3.48 / M tok |
| コンテキストウィンドウ | 100万トークン | 100万トークン |
| 最大出力 | 384Kトークン | 384Kトークン |
2つのティア間の入出力比率は、キャッシュミスレートで入力約12倍、出力約12倍です。キャッシュヒットの経済性はそのギャップをさらに広げます — 安定した長いシステムプロンプト(エージェントツールスキーマ、RAGコンテキスト、数ショットの例)があれば、入力側で80〜92%オフになります。Simon WillisonのDeepSeek V4料金比較によると、V4-FlashはGPT-5.4 Nanoより安く、V4-Proは出力コストでフロンティアのクローズドモデルすべてを下回っています。
レイテンシの開示:DeepSeekは執筆時点でV4の層ごとの公式レイテンシ数値を公開していません。サードパーティの報告ではFlashはProより明らかに速いとされていますが、公式ベンチマークを指摘できません — プレビューが安定次第、要検証。
制限事項と今後の検証が必要なこと
これはプレビューリリースです。本番トラフィックをコミットする前にフラグを立てるべき点:
- ベンチマークの再現。 上記の数字はすべてDeepSeek独自の技術レポートからのものです。ArenaスタイルのリーダーボードでのレギュレーションV4の結果ログが始まったばかりです。独立したSWE-Bench ProまたはTerminal Benchの実行はまだありません。
- マルチモーダル:未対応。 両V4バリアントはテキストのみです。DeepSeekはマルチモーダルが進行中だと述べていますが、記録上のタイムラインはありません。
- 商業的な背景。 リリースのBloomberg報道では、V4はDeepSeekに対する継続的な地政学的監視の中でリリースされ、一部の中国外の展開には制限があると記されています。公式APIを通じてユーザーデータをルーティングする前にコンプライアンス状況を確認してください。懸念がある場合は、オープンウェイトをセルフホストするのがクリーンな方法です。
- プレビューの安定性。 「プレビュー」のラベルはV4-Flashモデルカードにも明示されています。APIの動作と料金が変わることを想定してください。
- 廃止ウィンドウ。
deepseek-chatとdeepseek-reasonerのIDは2026年7月24日に廃止されます。現在これらはV4-Flashにルーティングされています。これらのIDを使用している場合、気づかぬうちにすでにFlash品質を利用しています — 明示的に移行してください。
データはここまでです。引き続き観察を続けます。サードパーティの評価が追いつき次第、更新します。
よくある質問

会話の途中でProとFlashを切り替えることはできますか?
はい。両モデルは同じAPIサーフェスと同じOpenAI互換フォーマットを共有しています。切り替えはリクエストボディのモデルID変更のみです。会話履歴(各呼び出しで渡すもの)は両モデル間で移植可能です。
両モデルともreasoning_effortをサポートしていますか?
はい。V4-ProとV4-Flashはどちらも、公式モデルカードによると、同じ3段階の推論努力モード(非思考、思考、Think Max)をサポートしています。モード間で料金は変わりません。生成されたトークンに対して課金され、Think Maxはより多くのトークンを生成するだけです。
Claude Codeスタイルのエージェントループにはどちらが適していますか?
Proです。Terminal Bench 2.0の差(67.9 vs 56.9)がマルチステップのシェル/ツールループの最も直接的な指標であり、11ポイントの差があります。Flashはシンプルなエージェントタスクには機能しますが、10以上のツール呼び出しをチェーンするループは、Flashが最も回帰するカテゴリにちょうど当てはまります。DeepSeek自身のポジショニング言語もこれを明示しています — 「シンプルなエージェントタスクではProと同等」であり、すべてのエージェントタスクではないと。
両モデルの商用利用条件は?
両モデルとも公式Hugging Faceリポジトリによるとゥ MITライセンスの下でリリースされており、商用利用、改変、再配布が許可されています。ウェイトはセルフホスト可能です。ホスティングされたAPI利用の場合、DeepSeek独自の利用規約が上に適用されます — デプロイの地域についても確認してください。
料金体系は同一ですか、それとも異なりますか?
構造は同じで、レートが異なります。両モデルとも入力、キャッシュヒット入力、出力のティアがあります。両モデルとも繰り返しのプレフィックスにキャッシュ割引をサポートしています。ProとFlashのレート間の比率は一貫しており、Proは出力トークンあたり約12倍高価です。執筆時点の公式ドキュメントには、プランティアまたはコミットベースの料金設定はありません。
過去の記事:





