DeepSeek V4 Pro vs Flash: Mana yang Tepat untuk Produksi?
Bandingkan DeepSeek V4 Pro vs V4 Flash untuk produksi: trade-off kemampuan, latensi, biaya, dan versi mana yang sesuai dengan beban kerja Anda.

DeepSeek merilis V4 sebagai dua model, bukan satu: V4-Pro dengan total 1,6T parameter dan 49B yang diaktifkan, serta V4-Flash dengan total 284B dan 13B yang diaktifkan. Keduanya berbagi jendela konteks 1M token. Keduanya bersifat open weights di bawah lisensi MIT. Keduanya tersedia di permukaan API yang sama.
Hal ini penting karena keputusannya bukan lagi “gunakan DeepSeek atau tidak.” Pertanyaannya adalah mana dari keduanya yang ditempatkan di balik endpoint mana. Dan jawabannya jarang berupa “gunakan Pro di mana saja.”
Ini adalah panduan pemilihan untuk tim produk AI dan pemimpin teknik yang mencoba merutekan beban kerja dengan tepat. Jika Anda sudah membaca artikel saya sebelumnya tentang fitur DeepSeek V4 untuk pengembang API, itu adalah era model tunggal. Ini adalah versi dua tingkatan.
Semua angka di bawah ini adalah per tanggal publikasi. Apa pun yang tidak dapat saya verifikasi terhadap dokumen resmi akan ditandai secara eksplisit.
DeepSeek V4 Pro vs Flash Sekilas
Posisi masing-masing versi (per pratinjau resmi)
Menurut kartu model V4-Pro DeepSeek di Hugging Face, pemisahan ini disengaja — keduanya bukan model yang sama dalam ukuran berbeda. Flash dilatih secara terpisah, bukan didistilasi dari Pro.
Framing DeepSeek sendiri:
- V4-Pro — pengetahuan dunia yang kaya melampaui model terbuka, penalaran kelas dunia di bidang matematika/SAINS/pemrograman, terkuat pada tugas-tugas agentic.
- V4-Flash — penalaran “mendekati” Pro, berkinerja setara dengan Pro pada tugas agen sederhana, lebih lemah pada tugas yang kompleks. Lebih murah untuk dilayani, respons lebih cepat.
Perbedaan “sederhana vs kompleks” itulah inti keputusannya. DeepSeek secara langsung memberi tahu Anda di mana Flash menurun. Jangan abaikan hal ini.
Fitur bersama (konteks 1M, mode thinking, kompatibilitas API)
Fitur-fitur yang identik di kedua varian:
- Jendela konteks 1M token pada kedua varian, diaktifkan oleh arsitektur perhatian hibrida DeepSeek (CSA + HCA). Menurut kartu Hugging Face, Pro hanya membutuhkan 27% FLOPs per token dan 10% cache KV dibandingkan V3.2 pada konteks 1M.
- Tiga mode upaya penalaran — non-thinking, thinking (tinggi), dan Think Max. Flag API yang sama, permukaan perilaku yang sama.
- API Chat Completions yang kompatibel dengan OpenAI dan dukungan protokol Anthropic.
base_urlyang sama, cukup ganti ID model. - Lisensi MIT pada bobot untuk keduanya, per repositori resmi.
Jika Anda bermigrasi di antara keduanya, permukaan integrasi tidak berubah. Hanya ID model dan tagihannya.
Perbedaan Kemampuan
Perbedaan keduanya terletak pada kategori evaluasi tertentu — dan polanya cukup konsisten untuk membangun aturan perutean.
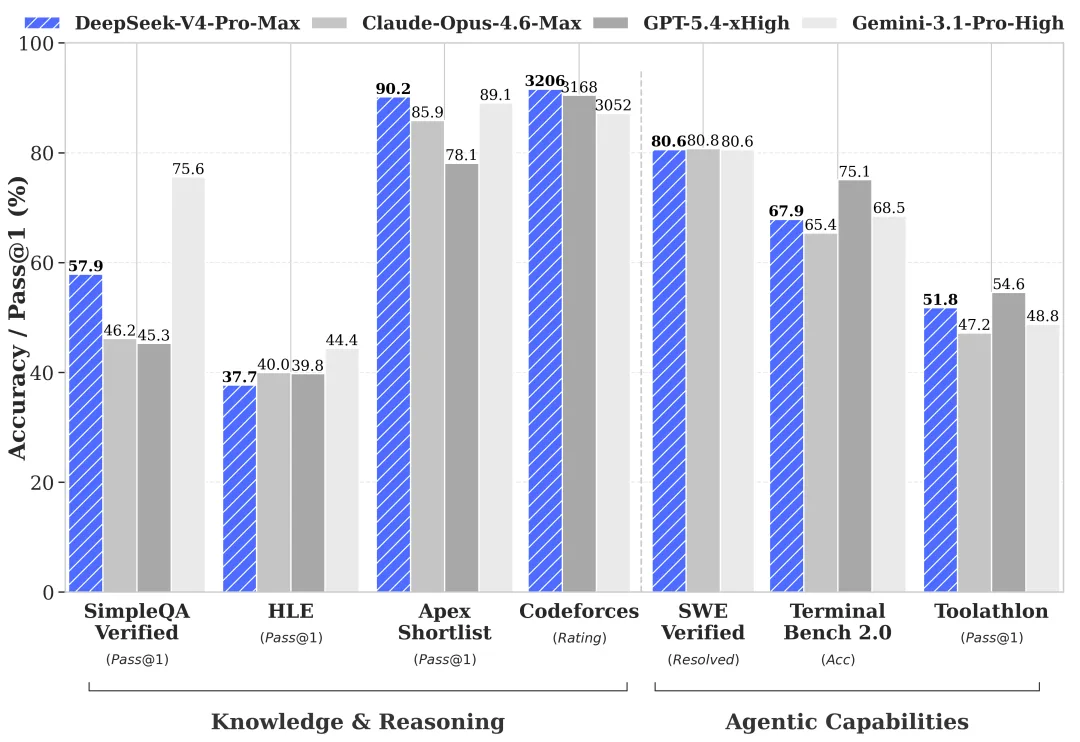
Pengetahuan dunia: Pro unggul, Flash tertinggal (per benchmark resmi — perlu verifikasi)
Benchmark pratinjau DeepSeek sendiri, yang dirangkum dari kartu HF dan laporan teknis mereka, menunjukkan bahwa kesenjangan Pro/Flash sempit pada sebagian besar kategori evaluasi — tetapi lebar di beberapa tempat tertentu:
| Benchmark | V4-Pro | V4-Flash | Selisih |
|---|---|---|---|
| MMLU-Pro | 87,5 | 86,2 | 1,3 |
| LiveCodeBench | 93,5 | 91,6 | 1,9 |
| SWE-Verified | 80,6 | 79 | 1,6 |
| Codeforces | 3206 | 3052 | ~150 Elo |
| SimpleQA-Verified | 57,9 | 34,1 | 23,8 |
| Terminal Bench 2.0 | 67,9 | 56,9 | 11 |
Angka yang dilaporkan oleh DeepSeek. Tidak ada replikasi pihak ketiga saat ini — perlu verifikasi sebelum adopsi produksi. Namun bentuk kesenjangan itulah sinyalnya, bukan angka pastinya.
SimpleQA-Verified adalah ingatan faktual. Terminal Bench 2.0 adalah penggunaan alat multi-langkah. Flash mengalami penurunan nyata pada keduanya. Hal ini konsisten dengan apa yang dikatakan DeepSeek secara langsung: tugas sederhana baik-baik saja, beban kerja agen yang kompleks lebih lemah.
Paritas penalaran pada tugas sederhana
Pada pemrograman, matematika, dan penalaran terbatas, kesenjangan menyempit menjadi 1-3 poin. LiveCodeBench dan MMLU-Pro menempatkan Flash dalam jangkauan Pro. Untuk sebagian besar panggilan inferensi dalam produk tipikal — giliran chat, pembuatan satu kali, penyelesaian kode, ringkasan — Flash bukan merupakan penurunan kualitas dengan cara apa pun yang akan diperhatikan pengguna.
Itulah inti proposisi nilai Flash: bukan Pro yang dipreteli. Ini adalah model yang dilatih secara terpisah yang kebetulan mendarat dekat dengan Pro di tengah distribusi benchmark.
Perbedaan tugas agen pada beban kerja berkompleksitas tinggi
Kategori jangka panjang, multi-alat, multi-hop adalah di mana keduanya berpisah. Terminal Bench 2.0 dan Toolathlon adalah evaluasi yang relevan di sini. Kesenjangan 11 poin pada Terminal Bench bukan margin yang bisa diabaikan sebagai kebisingan evaluasi.
Jika produk Anda adalah agen pemrograman yang menjalankan loop 30 langkah dengan akses filesystem dan shell, atau agen riset yang mengorkestrasikan 5+ panggilan alat per kueri, Flash akan lebih sering gagal di tempat yang mahal untuk di-debug. Bukan karena Flash buruk — tetapi karena inilah beban kerja yang dibangun Pro oleh DeepSeek.
Kerangka Keputusan Produksi
Pemilihan bukan tentang “mana yang lebih baik.” Ini tentang “mana yang cocok dengan bentuk beban kerja ini.” Tiga default berikut berfungsi dengan baik.
Kapan memilih Pro (pemrograman agentic, penalaran jangka panjang, evaluasi enterprise)
Pro adalah pilihan yang tepat ketika salah satu dari hal berikut ini benar:
- Anda menjalankan loop agen multi-langkah (gaya Claude Code, OpenCode, apa pun dengan penggunaan alat + perencanaan + verifikasi per giliran).
- Tugas Anda memerlukan ingatan faktual yang akurat pada ekor panjang entitas — kesenjangan SimpleQA 23 poin memprediksi perbedaan halusinasi nyata di sini.
- Anda melakukan evaluasi enterprise di mana biaya bisnis dari jawaban yang salah melebihi biaya per token dengan urutan besarnya.
- Anda memerlukan penalaran jangka panjang di seluruh konteks 1M token yang benar-benar penuh — angka efisiensi Pro pada konteks 1M adalah cerita arsitekturnya di sini.
Kapan memilih Flash (klasifikasi QPS tinggi, ringkasan, UX chat)
Flash bukan pilihan anggaran. Ini adalah pilihan yang tepat ketika:
- Anda menjalankan klasifikasi, penandaan, atau ekstraksi QPS tinggi — latensi dan biaya per panggilan mendominasi margin kualitas.
- Ringkasan dan terjemahan — tugas terbatas, satu kali yang delta benchmark 1-2 poin Flash tidak terlihat oleh pengguna.
- UX chat interaktif — latensi token pertama lebih penting daripada persentil ke-99 dari kualitas jawaban, dan Flash secara bermakna lebih cepat.
- Pekerjaan yang berdekatan dengan embedding: penulisan ulang kueri, klasifikasi niat, penilaian relevansi.
Memilih Pro di sini membuang 10× token output tanpa manfaat yang dirasakan. Itu keputusan yang lebih buruk daripada menggunakan Flash untuk loop agen.
Perutean hibrida: Flash sebagai default, Pro sebagai fallback
Untuk sebagian besar produk, arsitektur yang tepat bukanlah salah satu atau yang lain — melainkan keduanya, dengan router:
- Default setiap permintaan ke Flash.
- Eskalasi ke Pro pada satu atau lebih pemicu eksplisit: kegagalan panggilan alat, ambang kepercayaan tidak terpenuhi, agen multi-giliran memasuki fase yang diketahui sulit, pengguna menandai jawaban sebagai salah.
- Catat tingkat eskalasi. Jika <5% permintaan dieskalasi, Flash mencakup beban kerja Anda. Jika >30%, Anda berada di wilayah Pro dan routernya adalah overhead.
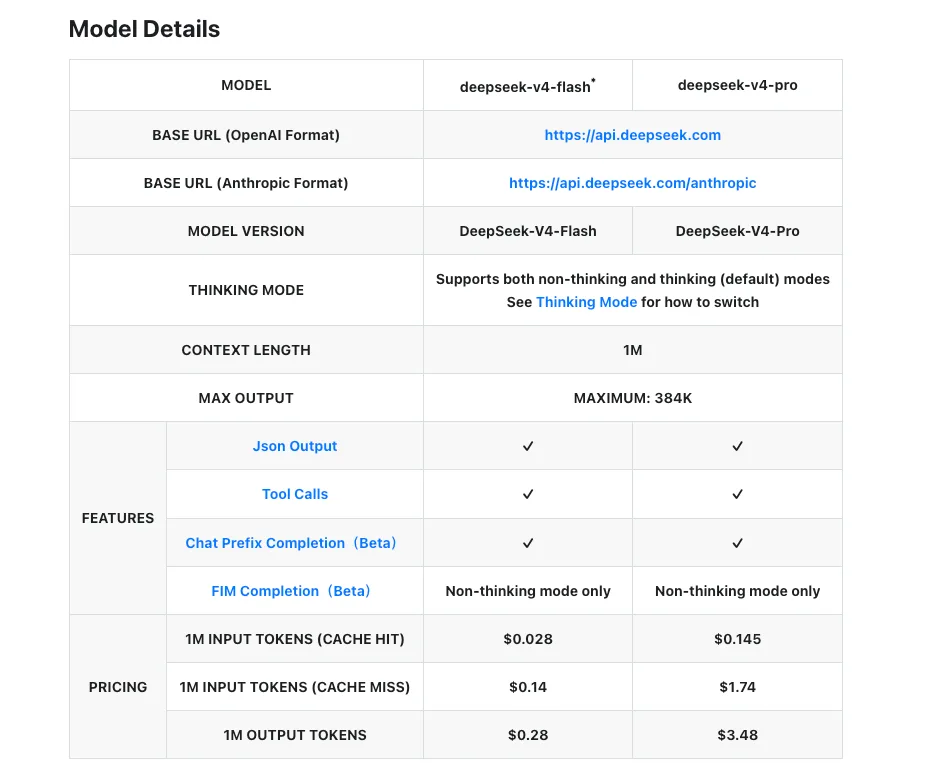
Ini hanya berfungsi karena Pro dan Flash berbagi permukaan API dan flag mode penalaran. Beralih di antara keduanya di tengah sesi adalah perubahan satu baris di sebagian besar klien. Dokumen harga resmi DeepSeek mengonfirmasi bahwa ID model adalah saudara, bukan endpoint yang terisolasi.
Pertimbangan Biaya dan Latensi (per tanggal publikasi)
Angka di bawah ini berasal dari halaman harga resmi DeepSeek per 24 April 2026.
| V4-Flash | V4-Pro | |
|---|---|---|
| Input (cache miss) | $0,14 / M tok | $1,74 / M tok |
| Input (cache hit) | $0,028 / M tok | $0,145 / M tok |
| Output | $0,28 / M tok | $3,48 / M tok |
| Jendela konteks | 1M token | 1M token |
| Output maksimum | 384K token | 384K token |
Pengungkapan latensi: DeepSeek belum mempublikasikan angka latensi resmi per tingkatan untuk V4 pada saat penulisan. Laporan pihak ketiga menunjukkan Flash melayani lebih cepat dari Pro, tetapi saya tidak dapat menunjuk pada benchmark resmi — perlu verifikasi setelah pratinjau stabil.
Keterbatasan dan Apa yang Masih Perlu Diverifikasi
Ini adalah rilis pratinjau. Hal-hal yang perlu ditandai sebelum Anda melakukan commit traffic produksi:
- Replikasi benchmark. Semua angka di atas berasal dari laporan teknis DeepSeek sendiri. Leaderboard gaya Arena baru mulai mencatat hasil V4. Belum ada penjalanan SWE-Bench Pro atau Terminal Bench yang independen.
- Multimodal: belum tersedia. Kedua varian V4 hanya berbasis teks. DeepSeek telah menyatakan multimodal sedang dalam proses; tidak ada jadwal yang tercatat.
- Konteks komersial. Liputan Bloomberg tentang rilis ini mencatat bahwa V4 hadir di tengah pengawasan geopolitik yang sedang berlangsung terhadap DeepSeek, dan beberapa penerapan non-Cina memiliki batasan. Periksa postur kepatuhan Anda sebelum merutekan data pengguna melalui API resmi; hosting mandiri bobot terbuka adalah jalur yang bersih jika itu menjadi perhatian.
- Stabilitas pratinjau. Label “pratinjau” juga eksplisit ada di kartu model V4-Flash. Harapkan perilaku API dan harga untuk berubah.
- Jendela penghentian. ID
deepseek-chatdandeepseek-reasonerakan dihentikan pada 24 Juli 2026. Saat ini keduanya merutekan ke V4-Flash. Jika Anda menggunakan ID tersebut, Anda sudah berada di kualitas Flash tanpa mengetahuinya — migrasi secara eksplisit.
Di situlah data saya berakhir. Masih mengamati. Saya akan memperbarui setelah evaluasi pihak ketiga menyusul.
FAQ

Bisakah saya beralih antara Pro dan Flash di tengah percakapan?
Ya. Keduanya berbagi permukaan API yang sama dan format yang kompatibel dengan OpenAI yang sama. Beralih adalah perubahan ID model dalam badan permintaan. Riwayat percakapan (saat Anda meneruskannya di setiap panggilan) dapat dipindahkan di antara keduanya.
Apakah keduanya mendukung reasoning_effort?
Ya. V4-Pro dan V4-Flash mendukung tiga mode upaya penalaran yang sama — non-thinking, thinking, dan Think Max — per kartu model resmi. Harga tidak berubah antar mode; Anda ditagih berdasarkan token yang dihasilkan, dan Think Max hanya menghasilkan lebih banyak.
Versi mana yang lebih baik untuk loop agen bergaya Claude Code?
Pro. Kesenjangan Terminal Bench 2.0 (67,9 vs 56,9) adalah proxy paling langsung untuk loop shell/alat multi-langkah, dan itu adalah perbedaan 11 poin. Flash akan bekerja untuk tugas agen sederhana, tetapi loop yang menghubungkan 10+ panggilan alat menghadapi tepat kategori di mana Flash paling banyak mengalami regresi. Bahasa penentuan posisi DeepSeek sendiri menyatakan ini secara eksplisit — “setara dengan Pro untuk tugas Agen sederhana,” bukan semua tugas agen.
Ketentuan penggunaan komersial untuk keduanya?
Keduanya dirilis di bawah Lisensi MIT per repositori Hugging Face resmi, yang mengizinkan penggunaan komersial, modifikasi, dan redistribusi. Bobot dapat di-hosting sendiri. Untuk penggunaan API yang dihosting, persyaratan layanan DeepSeek sendiri berlaku di atas — verifikasi untuk geografi penerapan Anda.
Apakah struktur harga identik atau berbeda?
Struktur yang sama, tarif yang berbeda. Keduanya memiliki tingkatan input, input cache-hit, dan output. Keduanya mendukung diskon cache pada prefiks yang berulang. Rasio antara tarif Pro dan Flash konsisten — Pro kira-kira 12× lebih mahal pada output per token. Tidak ada harga berbasis paket atau komitmen pada dokumen resmi pada saat penulisan.
Postingan Sebelumnya:
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8
API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi
Harga GPT-5.4 Mini: Biaya Input, Cache & Output
API MAI-Image-2.5: Yang Perlu Diketahui Para Developer