MaxClaw vs OpenClaw : Lequel devriez-vous vraiment utiliser ?
MaxClaw ou OpenClaw ? L'un est géré dans le cloud, l'autre est auto-hébergé. Nous analysons la configuration, le coût, le contrôle et les performances — pour que vous choisissiez celui qui correspond à vos besoins.

Bonjour, je m’appelle Dora. Pendant une semaine, j’ai testé MaxClaw et OpenClaw côte à côte sur deux tâches concrètes : un résumeur de support qui rédige des notes internes, et un petit assistant de recherche qui extrait des citations pour les compiler en synthèse. Rien de très élaboré, vous voyez. J’ai tenu un journal succinct : temps de configuration, accrocs, et les moments où j’ai enfin pu souffler. Voici comment je distingue MaxClaw vs OpenClaw en termes simples, sans battage médiatique.
La différence en une phrase

MaxClaw est un cloud géré qui s’occupe de la plomberie à votre place : OpenClaw repose sur la même idée, mais en auto-hébergement, où vous êtes responsable des tuyaux. C’est là que les chemins divergent vraiment : commodité et contraintes d’un côté, contrôle et corvées de l’autre.
MaxClaw — L’option cloud géré
Temps de configuration : moins de 20 secondes contre des heures
Je l’ai chronométré deux fois. De la création de compte au premier endpoint fonctionnel dans MaxClaw : 18 secondes au deuxième essai (28 au premier, le temps d’hésiter sur un champ de nommage). J’ai entré une clé API, choisi un modèle de démarrage pour le routage des messages, et c’était terminé. Si vous souhaitez voir le processus d’intégration étape par étape, ce guide sur comment configurer MaxClaw vous guide en moins de cinq minutes. Pas de ports. Pas de fichiers env. J’ai pointé mon petit résumeur de support dessus et ça a juste… fonctionné. Il y a un certain soulagement à ne pas avoir à toucher Docker un mardi.
Avec OpenClaw, ce même parcours m’a pris quelques heures, principalement parce que j’ai bidouillé des paramètres par défaut dont je n’avais pas encore vraiment besoin. C’est ma faute, mais c’est aussi la rançon de l’auto-hébergement : on bidouille même quand on n’en a pas besoin.

Coût : abonnement vs factures API imprévisibles
MaxClaw fonctionne sur abonnement. Vous connaissez le plafond avant de commencer. Pour les équipes, cette prévisibilité compte davantage que les économies théoriques de l’auto-hébergement. L’avantage caché n’était pas financier : c’était moins d’onglets ouverts et moins d’endroits à surveiller. La consolidation est une forme d’économie.
OpenClaw repose directement sur les API de modèles que vous apportez (ou les modèles locaux que vous faites tourner). Sur le papier, ça peut revenir moins cher à faible volume. En pratique, j’ai observé de petites fluctuations — quelques appels à long contexte sur GPT-4 ont coûté plus cher que prévu. Rien de dramatique, mais la classique énergie du « pourquoi cet endpoint est-il soudainement cher ? ». Avec de la discipline sur les limites de débit et la mise en cache, on peut maîtriser ça. Sinon, les coûts dérivent.
Ce à quoi vous renoncez (flexibilité des modèles, contrôle total)
MaxClaw m’a offert rapidité et moins de décisions. La contrepartie est évidente : il sélectionne les modèles et les fonctionnalités. Vous acceptez leur menu, leur couche d’observabilité et leur rythme de déploiement. Quand j’ai voulu passer le résumeur de GPT-4 à Claude en milieu de semaine, j’ai dû suivre le processus de MaxClaw pour ce changement. C’était correct, mais pas aussi ouvert que ma propre infrastructure.
Le contrôle importe quand on se soucie des comportements aux limites. Je ne pouvais pas corriger un cas limite bizarre de tokenisation comme je l’aurais fait dans mon propre code. En revanche, je n’avais pas à maintenir un gestionnaire de file d’attente ni une politique de tentatives. Moins de puissance, moins d’irritations. À chacun de choisir son poison.
OpenClaw — L’option auto-hébergée
Ce dont vous avez réellement besoin : Node.js, 1,5 Go de RAM, un serveur
Je l’ai installé sur une petite VM Ubuntu avec 2 vCPU et 2 Go de RAM. Vous aurez besoin de Node.js (j’ai utilisé la v20 : téléchargez-la depuis la page officielle Node.js downloads), d’environ 1,5 Go de mémoire libre pour être à l’aise, et d’un endroit pour le faire tourner (une instance cloud basique convient). Ajoutez les variables d’environnement, un reverse proxy si vous voulez TLS, et un gestionnaire de processus. J’ai utilisé PM2. Rien d’extravagant, juste du travail.
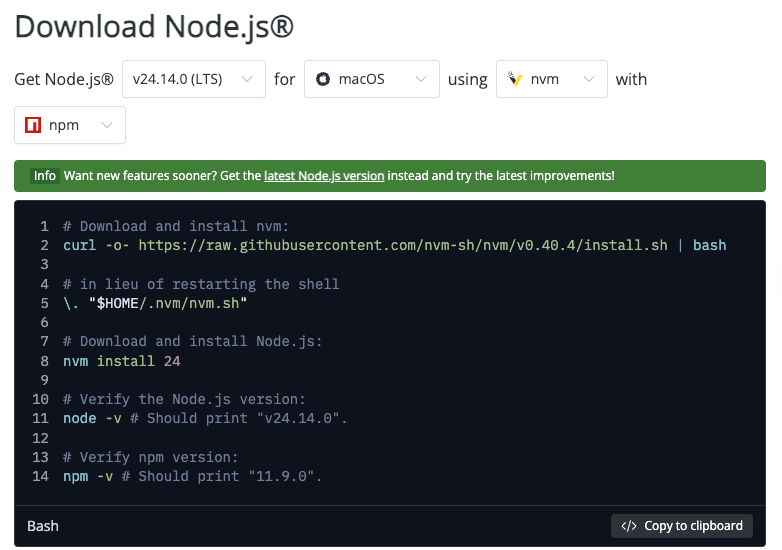
Deux accrocs notés dans mon journal : j’ai oublié d’ouvrir le chemin de healthcheck sur le pare-feu (5 minutes perdues), et j’ai confondu un nom de variable d’environnement (10 minutes à lire les logs). Pas rédhibitoire, mais bien réel.
Flexibilité totale des modèles (Claude, GPT-4, etc.)
Une fois en fonctionnement, OpenClaw m’a permis de brancher n’importe quel modèle adapté à la situation. Pour l’assistant de recherche, j’ai alterné entre Claude 3.5 Sonnet (réactif, excellent pour les citations) et GPT-4 Turbo (formatage plus régulier). Si vous évoluez dans plusieurs univers de modèles, cette liberté semble naturelle et nécessaire. Vous pointez simplement les clés vers le routeur et vous partez. Pour la documentation, la référence API d’Anthropic et la documentation API d’OpenAI ont couvert les cas limites que j’ai rencontrés.

Qui bénéficie vraiment de l’auto-hébergement
- Les développeurs qui veulent instrumenter chaque étape : leur propre journalisation, leurs propres tentatives, leur propre suppression des données sensibles.
- Les équipes avec des règles de conformité qui préfèrent simplement gérer leur propre infrastructure.
- Les personnes qui aiment peaufiner les pipelines de prompts et la mise en cache au niveau du routeur.
Si vous avez uniquement besoin d’« un endpoint qui se comporte correctement », l’auto-hébergement peut être excessif. Il brille quand vous continuerez à faire évoluer l’infrastructure et que vous voulez la liberté d’échanger des composants sans attendre la feuille de route d’un fournisseur.
Tableau comparatif
Voici la vue d’ensemble que j’aurais aimé avoir avant de commencer.
J’ai rédigé deux petits guides opérationnels pendant les tests : un pour les vérifications d’incidents (quoi regarder quand les résultats dérivent) et un pour la sanité des coûts (logs à échantillonner chaque semaine). Avec MaxClaw, ces guides se sont réduits à quelques clics dans le tableau de bord. Avec OpenClaw, ce sont des scripts et des alias shell. Ni l’un ni l’autre n’est mauvais. C’est juste là que va le temps.
Guide de décision concret
Choisissez MaxClaw si…
- Vous voulez des endpoints fonctionnels aujourd’hui, pas cet après-midi.
- Une facturation prévisible compte plus que d’optimiser chaque dollar d’API.
- Vous préférez sacrifier un peu de flexibilité des modèles pour moins de pièces mobiles.
- Votre cas d’usage est stable (résumés, routage, agents légers) et vous valorisez l’observabilité intégrée plutôt que les métriques personnalisées.
- Vous n’avez pas quelqu’un qui aime maintenir l’infrastructure, ou vous êtes cette personne et vous aimeriez récupérer vos week-ends.
Choisissez OpenClaw si…
- Vous avez besoin d’un contrôle total sur la sélection des modèles, les limites de tokens et les tentatives.
- La conformité ou la résidence des données vous pousse vers votre propre serveur.
- Vous itérez rapidement et voulez posséder le pipeline : mise en cache, garde-fous, évaluations, tout le lot.
- Vous avez le temps (et le tempérament) pour gérer les logs, mettre à jour les dépendances et surveiller les coûts.
- Vous prévoyez d’expérimenter avec plusieurs fournisseurs (Claude, GPT-4 et autres) et ne voulez pas que le menu d’un fournisseur dicte vos options.
L’approche hybride (le meilleur des deux mondes ?)
Ce qui a vraiment fonctionné pour moi, c’est un découpage. J’ai conservé MaxClaw pour le résumeur de support — prévisible et sans drama, les logs gérés m’ont aidé à repérer une dérive de prompt en moins de cinq minutes. J’ai migré l’assistant de recherche vers OpenClaw pour pouvoir passer d’un modèle à l’autre sans attendre personne. La frontière est simple : les tâches stables vont vers le géré, les expérimentales vivent sur ma machine.
Est-ce que ça ajoute un endroit de plus à vérifier ? Oui. Mais ça réduit aussi la pression. Si un côté a besoin de maintenance, l’autre continue de tourner. Je ne pense pas que l’hybride soit « le meilleur » — c’est juste serein. Et le calme a tendance à bien vieillir.
Dernière note de la semaine : les outils se sont effacés en arrière-plan une fois les routes établies. C’est mon test silencieux d’adéquation. Si j’oublie lequel j’utilise pendant que je travaille, c’est probablement le bon choix pour cette tâche.
Articles associés

Claude Fable 5 vient de sortir : 80,3 % sur SWE-Bench Pro, prix 2× Opus 4.8, gratuit jusqu'au 22 juin

Comment choisir une API de médias IA pour les applications Codex (2026)

API Hunyuan 3D : Ce que les développeurs doivent savoir

Hunyuan 3D vs Hyper3D vs Pixal3D

Créer des applications vidéo IA avec des agents de codage
