GLM-5V-Turbo : Ce que les développeurs doivent savoir en 2026
GLM-5V-Turbo est le modèle vision-coding de Z.ai. Voici ce que les développeurs doivent savoir sur son API, ses tarifs, ses limites et ses cas d'usage réels en 2026.

Un collègue m’a envoyé une capture d’écran la semaine dernière — une maquette de design à gauche, une reproduction HTML quasi pixel-perfect à droite. “GLM-5V-Turbo a fait ça en une seule passe”, indiquait la légende. Je l’ai mis de côté et j’ai continué. Puis je l’ai vu mentionné dans le même souffle que les outils de workflow agentique, et j’ai décidé de vraiment regarder ce que ce modèle est et n’est pas.
Voici ce que j’ai trouvé — écrit pour les développeurs qui évaluent des modèles multimodaux pour des cas d’usage de codage agentique, pas pour ceux qui cherchent une recommandation de produit.
Qu’est-ce que GLM-5V-Turbo ?
Z.ai (Zhipu AI) et la famille de modèles GLM
GLM-5V-Turbo est un modèle vision-langage publié le 1er avril 2026 par Zhipu AI, opérant à l’international sous la marque Z.ai. Zhipu est un laboratoire d’IA basé à Pékin — coté en bourse à la Bourse de Hong Kong depuis janvier 2026 — et l’un des producteurs de modèles de fondation les plus actifs en Chine. Leur série GLM a itéré rapidement : GLM-4.5 en juillet 2025, GLM-4.7 en décembre, GLM-5 en février 2026, et maintenant une variante multimodale en avril.
GLM-5V-Turbo est le premier modèle de la famille conçu comme un agent multimodal natif — ce qui signifie que la vision n’a pas été ajoutée après coup, elle faisait partie de l’architecture dès le départ. Cette distinction compte pour ce que le modèle est réellement capable de faire.
En quoi GLM-5V-Turbo diffère de GLM-4V et GLM-5
GLM-4V gérait l’entrée d’images. GLM-5 a amélioré le codage textuel et le raisonnement. GLM-5V-Turbo combine l’entrée multimodale (image, vidéo, texte) avec une sortie orientée agent : appel d’outils, décomposition de tâches et interaction avec les interfaces graphiques. Il est construit autour d’un nouvel encodeur visuel appelé CogViT, utilise l’apprentissage par renforcement sur plus de 30 types de tâches, et exécute une quantification INT8 pour une inférence plus rapide.
Le positionnement est délibérément étroit. Ce n’est pas une mise à niveau généraliste de GLM-5. C’est un modèle spécialisé pour les tâches qui commencent avec une entrée visuelle et se terminent par du code ou une action structurée.
Capacités principales
Design-to-Code et génération d’interface utilisateur
La capacité phare est la reproduction de designs d’interface sous forme de code frontend fonctionnel. Donnez au modèle une maquette — capture d’écran, export Figma, esquisse dessinée à la main — et il génère du HTML, du CSS et parfois du JavaScript. Dans les propres tests de Z.ai, GLM-5V-Turbo a obtenu un score de 94,8 sur le benchmark Design2Code contre 77,3 pour Claude Opus 4.6. C’est un écart significatif si le benchmark résiste à des tests indépendants (nous y reviendrons ci-dessous).
En pratique, c’est surtout utile pour l’échafaudage frontend : transformer des spécifications de design en code de composant initial, reproduire des mises en page d’interface existantes pour des projets de migration, ou générer des variations à partir d’une image de référence.
Agent GUI et support des workflows agentiques
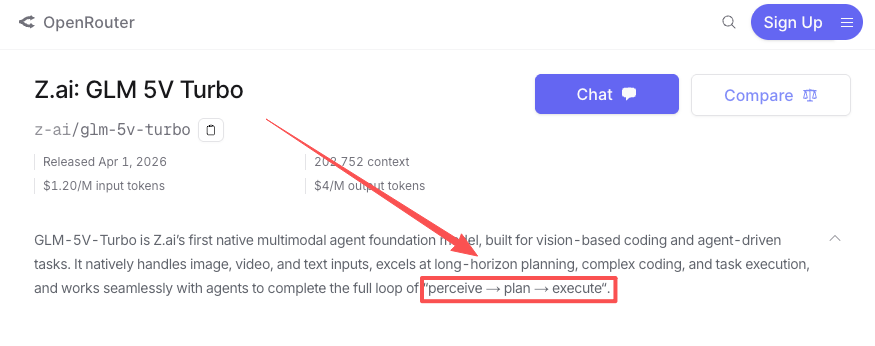
Au-delà de la reproduction de design statique, le modèle prend en charge les tâches d’agent GUI — navigation dans les interfaces de navigateur, extraction de données structurées à partir d’écrans et exécution de workflows multi-étapes impliquant un état visuel. La page du modèle sur OpenRouter le décrit comme conçu pour “compléter la boucle complète percevoir → planifier → exécuter”, et les résultats des benchmarks AndroidWorld et WebVoyager cités par Z.ai suggèrent qu’il peut gérer la navigation GUI dans le monde réel, pas seulement des tests synthétiques.
Pour les équipes qui construisent des workflows agentiques incluant une couche visuelle — automatisation de remplissage de formulaires, agents de test d’interface, pipelines écran-vers-action — c’est là que le modèle a une prétention pratique. Les améliorations de l’appel d’outils dans GLM-5V-Turbo (héritées et étendues depuis GLM-5-Turbo) sont explicitement conçues pour réduire les invocations échouées dans les boucles d’agents.
Gestion des entrées multimodales
Le modèle accepte des images, de courts clips vidéo et du texte dans le même contexte. L’entrée vidéo étend les cas d’usage aux enregistrements d’écran et aux démonstrations de produits — le modèle peut suivre visuellement et générer de la documentation ou des plans d’action à partir de ce qu’il voit. La fenêtre de contexte est de 202 752 tokens avec un maximum de sortie de 131 072 tokens, confirmé sur la page de tarification officielle de Z.ai.
Accès API et tarification
Comment accéder à GLM-5V-Turbo via l’API
Le modèle est disponible via l’API de Z.ai avec une interface compatible OpenAI. L’authentification suit les schémas standard de clé API — inscrivez-vous sur z.ai, générez une clé, configurez-la dans vos outils existants.
L’API prend en charge l’appel de fonctions, le streaming et la sortie structurée — la même surface de capacités que GLM-5-Turbo, étendue avec l’entrée visuelle.
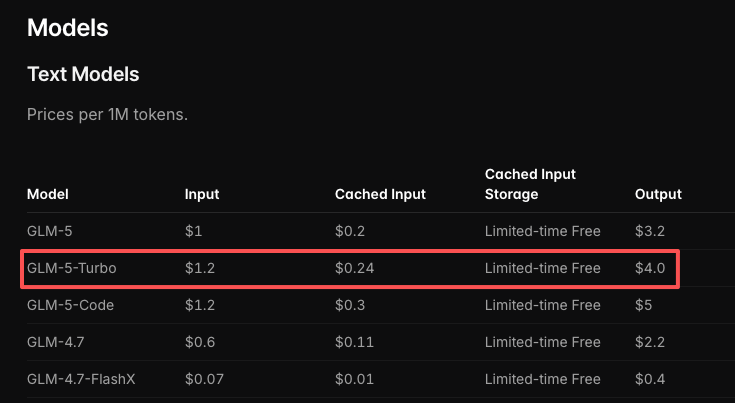
Tarification : coûts des tokens d’entrée et de sortie
| GLM-5V-Turbo | GLM-5-Turbo | GLM-5 | |
|---|---|---|---|
| Entrée (par 1M tokens) | $1,20 | $1,20 | $1,00 |
| Sortie (par 1M tokens) | $4,00 | $4,00 | $3,20 |
| Entrée en cache | $0,24 | $0,24 | $0,20 |
Chiffres tirés de la page de tarification officielle de Z.ai en avril 2026. Vérifiez directement avant de planifier des budgets de production — Z.ai a ajusté la tarification lors des lancements de modèles précédents.
Pour référence : Claude Opus 4.6 coûte $5/M en entrée et $25/M en sortie. GPT-4o est à $2,50/$10. À $1,20/$4, GLM-5V-Turbo est nettement moins cher pour les workloads à forte charge visuelle où le volume de sortie est modeste.
Fenêtre de contexte et limites de sortie
- Fenêtre de contexte : 202 752 tokens
- Sortie maximale : 131 072 tokens
Les deux sont généreux. Pour la plupart des tâches de design-to-code ou d’agent GUI, vous n’atteindrez pas ces limites. Les longues séquences vidéo ou les fichiers de design très volumineux pourraient y arriver, donc il vaut la peine de tester avec vos entrées réelles avant de vous engager.
Où il s’intègre (et où il ne s’intègre pas)
Points forts : codage visuel, reproduction de design
L’avantage pratique de GLM-5V-Turbo est spécifique : les tâches qui nécessitent de regarder quelque chose et d’en produire du code. Échafaudage frontend à partir d’assets de design, extraction de composants d’interface, capture d’écran vers HTML, analyse d’enregistrement d’écran. Si votre pipeline commence par un artefact visuel et se termine par du code, ce modèle vaut la peine d’être comparé à votre solution actuelle.
Le support des workflows agentiques est un vrai ajout. La stabilité des appels d’outils compte dans les boucles d’agents en production — les invocations échouées brisent les chaînes et nécessitent des nouvelles tentatives. L’accent mis par Z.ai sur ce point dans GLM-5V-Turbo est un signe qu’ils ont observé le même mode d’échec que tous ceux qui construisent des agents.
Limitations : codage backend en texte pur, raisonnement général
C’est la partie qui mérite d’être explicite. GLM-5V-Turbo n’est pas un concurrent direct de Claude ou GPT-4o pour le codage backend, l’exploration de dépôts ou les tâches de raisonnement général. Dans ces catégories, Claude Opus 4.6 est en tête selon les propres comparaisons de Z.ai — et c’est l’entreprise qui présente le cas favorable pour son modèle.
Si votre travail de codage est principalement texte en entrée, texte en sortie — débogage de logique, écriture d’intégrations API, refactorisation de code backend — un modèle texte uniquement comme GLM-5 ou GLM-5-Turbo vous servira mieux au même prix. Ajouter un encodeur visuel n’aide pas pour les problèmes qui n’impliquent pas d’entrée visuelle.
Qui devrait l’utiliser et qui devrait passer son chemin
Vaut la peine d’être évalué si vous :
- Construisez des outils frontend qui démarrent à partir d’assets de design
- Exécutez des workflows d’agent GUI avec état visuel
- Cherchez une alternative moins chère à GPT-4V ou Claude pour les tâches image-to-code
- Testez des entrées multimodales dans un pipeline d’agents
Probablement à éviter si vous :
- Travaillez sur du codage en texte pur — backend, outils CLI, développement d’API
- Avez besoin d’un raisonnement général solide en plus de la génération de code
- Opérez sous des contraintes de résidence des données (Z.ai est une entreprise chinoise ; vérifiez leur politique de confidentialité par rapport à vos exigences de conformité)
Affirmations sur les benchmarks — Ce qu’il faut prendre au sérieux
Performance Design2Code
Z.ai rapporte que GLM-5V-Turbo a obtenu 94,8 sur Design2Code contre 77,3 pour Claude Opus 4.6. Ce sont les propres mesures de Z.ai. Aucun laboratoire d’évaluation indépendant n’a publié de résultats corroborants au moment de la rédaction. Cela ne signifie pas que les chiffres sont faux — cela signifie qu’ils n’ont pas encore été soumis à des tests de stress.
Design2Code en tant que benchmark mesure à quel point le HTML/CSS généré reproduit une maquette de référence, en termes de pixels et de structure. C’est un proxy raisonnable pour la tâche spécifique de reproduction d’interface. Ce n’est pas un proxy pour la qualité générale du codage, le jugement architectural ou la préparation à la production dans le monde réel.
L’écart est suffisamment large pour être crédible comme signal directionnel. Traitez-le comme une raison de tester, pas comme une conclusion.
Mises en garde sur la comparaison du codage en texte pur
La documentation de Z.ai reconnaît que GLM-5V-Turbo est derrière Claude dans les benchmarks de codage en texte pur. Cette franchise est utile. Cela signifie que le positionnement du modèle est honnête : c’est un outil axé sur le visuel, pas une mise à niveau générale du codage. Toute comparaison qui présente GLM-5V-Turbo comme globalement compétitif avec les modèles de texte de pointe interprète mal ce que l’entreprise affirme réellement.
FAQ
Q : GLM-5V-Turbo est-il disponible via l’API ?
Oui. Via l’API native de Z.ai (compatible OpenAI) et via OpenRouter. Configuration standard de clé API, prend en charge l’appel de fonctions et le streaming.
Q : Quelle est la tarification de GLM-5V-Turbo ?
1,20 $ par million de tokens en entrée, 4,00 $ par million de tokens en sortie, en avril 2026. Vérifiez sur docs.z.ai/guides/overview/pricing avant utilisation en production.
Q : Comment GLM-5V-Turbo se compare-t-il à GPT-4o et Claude pour le codage ?
Pour les tâches de design-to-code et d’interface visuelle : les benchmarks de Z.ai (auto-rapportés) le montrent en avance sur les deux. Pour le codage en texte pur et le travail backend : Claude Opus 4.6 est en tête. La comparaison ne tient que dans le domaine visuel.
Q : GLM-5V-Turbo prend-il en charge l’entrée vidéo ?
Oui — de courts clips vidéo aux côtés d’images et de texte dans le même contexte. Utile pour les enregistrements d’écran et la génération de documentation basée sur des démonstrations.
Q : Quelles sont les limites de débit et la fenêtre de contexte ?
La fenêtre de contexte est de 202 752 tokens, la sortie maximale de 131 072 tokens. Les limites de débit ne sont pas publiées dans la documentation officielle — Z.ai a eu des problèmes de capacité lors des lancements de modèles précédents, donc testez le débit sous charge réelle avant de vous engager dans une architecture de production.
Le design-to-code est une catégorie de tâches véritablement utile, et avoir un modèle qui la traite comme un problème de première classe — plutôt que comme une capacité secondaire d’un modèle généraliste — est une décision d’ingénierie raisonnable. Que GLM-5V-Turbo tienne ses promesses dans votre pipeline spécifique est quelque chose que seules vos propres données de test pourront déterminer.
Les chiffres des benchmarks méritent un coup d’œil. La vérification indépendante est encore en attente.
Tarification et spécifications vérifiées par rapport à la documentation officielle de Z.ai au 2 avril 2026. Tous les chiffres de benchmark sont des données auto-rapportées par Z.ai sauf indication contraire — considérez-les comme préliminaires jusqu’à validation indépendante.
Articles précédents :
- Construire un pipeline créatif IA avec GLM-5 + WaveSpeed
- GLM-5 pour l’orchestration de prompts IA image & vidéo
- Démarrage rapide de l’API GLM-5 sur WaveSpeed (exemples de code)
- GLM-5 vs GLM-4.7 : Devriez-vous mettre à niveau ? (Benchmarks)
- GLM-5 vs DeepSeek V3 vs GPT-5 : Vitesse & coût pour les développeurs
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué

API GLM-5.2 : Tarification, contexte 1M et routage en production

Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie

API MAI-Image-2.5 : Ce que les développeurs doivent savoir
