DeepSeek V4 Pro vs Flash : Lequel choisir pour la production ?
Comparez DeepSeek V4 Pro et V4 Flash pour la production : compromis de capacités, latence, coût et quelle version correspond à votre charge de travail.

DeepSeek a publié V4 sous la forme de deux modèles, pas un seul : V4-Pro avec 1,6T de paramètres totaux dont 49B activés, et V4-Flash avec 284B totaux dont 13B activés. Les deux partagent une fenêtre de contexte de 1M tokens. Les deux sont en open weights sous licence MIT. Les deux sont disponibles sur la même surface d’API.
C’est important car la décision n’est plus « utiliser DeepSeek ou non ». C’est lequel des deux placer derrière quel endpoint. Et la bonne réponse est rarement « utiliser Pro partout ».
Ceci est un guide de sélection pour les équipes produit IA et les responsables techniques cherchant à router correctement les charges de travail. Si vous avez lu mon article précédent sur les fonctionnalités de DeepSeek V4 pour les développeurs d’API, c’était l’ère du modèle unique. Voici la version à deux niveaux.
Tous les chiffres ci-dessous sont valables à la date de publication. Tout ce que je ne peux pas vérifier dans les documents officiels est explicitement signalé.
DeepSeek V4 Pro vs Flash en un coup d’œil
Positionnement de chaque version (selon la préversion officielle)
Selon la fiche modèle V4-Pro de DeepSeek sur Hugging Face, la séparation est intentionnelle — ce ne sont pas les mêmes modèles à des tailles différentes. Flash est entraîné séparément, pas distillé à partir de Pro.
Le cadrage de DeepSeek lui-même :
- V4-Pro — connaissance du monde riche surpassant les modèles open source, raisonnement de classe mondiale en mathématiques/STEM/programmation, le plus performant sur les tâches agentiques.
- V4-Flash — raisonnement « proche de » Pro, performances au niveau de Pro sur les tâches agentiques simples, plus faible sur les tâches complexes. Moins coûteux à servir, réponses plus rapides.
Cette distinction « simple vs complexe » est toute la décision. DeepSeek vous dit directement où Flash décroche. Ne l’ignorez pas.
Fonctionnalités partagées (contexte 1M, mode thinking, compatibilité API)
Les fonctionnalités identiques sur les deux variantes :
- Fenêtre de contexte de 1M tokens sur les deux variantes, permise par l’architecture d’attention hybride de DeepSeek (CSA + HCA). Selon la fiche Hugging Face, Pro n’a besoin que de 27% des FLOPs par token et 10% du cache KV par rapport à V3.2 à 1M de contexte.
- Trois modes d’effort de raisonnement — non-thinking, thinking (élevé), et Think Max. Même flag API, même surface de comportement.
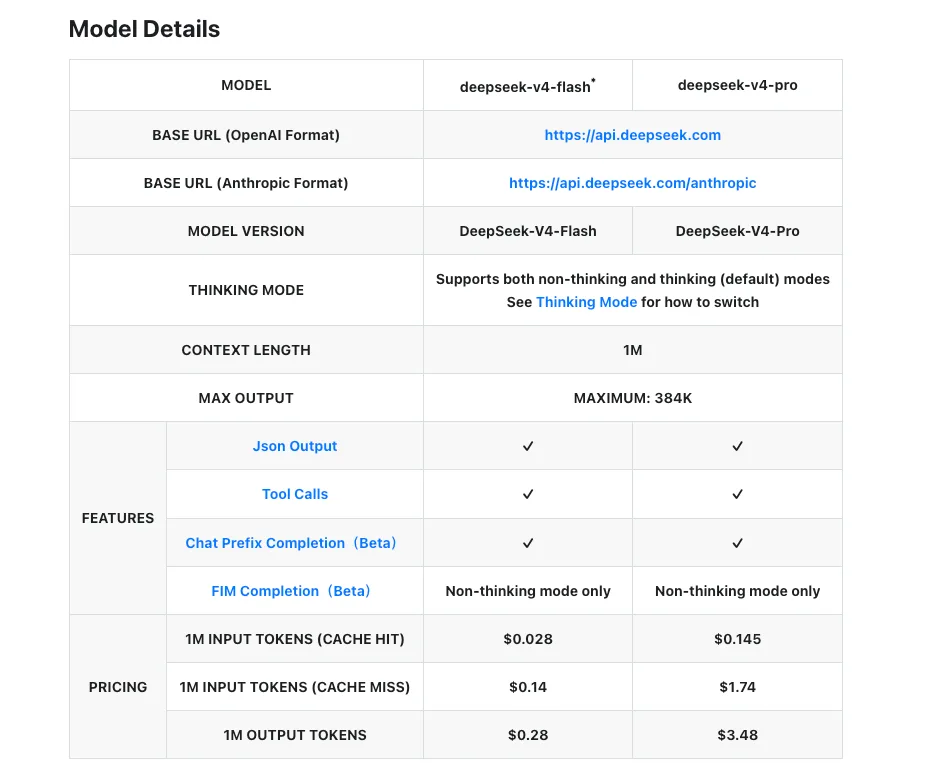
- API Chat Completions compatible OpenAI et support du protocole Anthropic. Même
base_url, il suffit de changer l’ID du modèle. - Licence MIT sur les poids pour les deux, selon les dépôts officiels.
Si vous migrez entre eux, la surface d’intégration ne change pas. Seuls l’ID du modèle et la facture changent.
Différences de capacités
Là où ils divergent, c’est sur des catégories d’évaluation spécifiques — et le schéma est suffisamment cohérent pour construire une règle de routage.
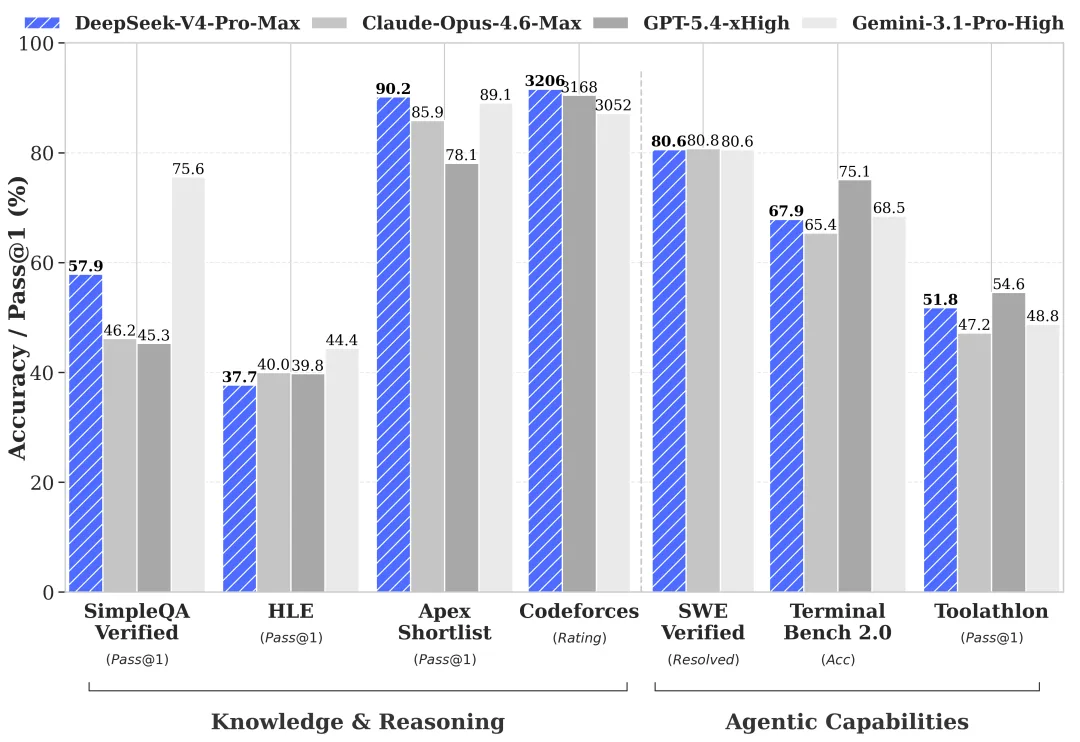
Connaissance du monde : Pro en tête, Flash en retrait (selon les benchmarks officiels — à vérifier)
Les propres benchmarks de préversion de DeepSeek, résumés dans leur fiche HF et leur rapport technique, montrent que l’écart Pro/Flash est étroit dans la plupart des catégories d’évaluation — mais large dans quelques endroits spécifiques :
| Benchmark | V4-Pro | V4-Flash | Écart |
|---|---|---|---|
| MMLU-Pro | 87,5 | 86,2 | 1,3 |
| LiveCodeBench | 93,5 | 91,6 | 1,9 |
| SWE-Verified | 80,6 | 79 | 1,6 |
| Codeforces | 3206 | 3052 | ~150 Elo |
| SimpleQA-Verified | 57,9 | 34,1 | 23,8 |
| Terminal Bench 2.0 | 67,9 | 56,9 | 11 |
Chiffres rapportés par DeepSeek. Aucune réplication tierce n’existe à ce jour — à vérifier avant adoption en production. Mais la forme de l’écart est le signal, pas les chiffres exacts.
SimpleQA-Verified teste le rappel factuel. Terminal Bench 2.0 teste l’utilisation d’outils en plusieurs étapes. Flash accuse un vrai recul sur les deux. C’est cohérent avec ce que DeepSeek a dit en termes clairs : tâches simples, c’est bien ; charges de travail agentiques complexes, c’est plus faible.
Parité de raisonnement sur les tâches simples
Sur la programmation, les mathématiques et le raisonnement borné, l’écart se réduit à 1-3 points. LiveCodeBench et MMLU-Pro placent Flash à portée de Pro. Pour la plupart des appels d’inférence dans un produit typique — tour de chat, génération one-shot, complétion de code, résumé — Flash n’est en aucun cas une régression que les utilisateurs remarqueront.
C’est le cœur de la proposition de valeur de Flash : ce n’est pas un Pro allégé. C’est un modèle entraîné séparément qui se retrouve proche de Pro sur la partie médiane de la distribution des benchmarks.
Divergence sur les tâches agentiques à haute complexité
La catégorie longue durée, multi-outils, multi-sauts est là où les deux se séparent. Terminal Bench 2.0 et Toolathlon sont les évaluations pertinentes ici. L’écart de 11 points sur Terminal Bench n’est pas une marge qu’on peut attribuer au bruit des benchmarks.
Si votre produit est un agent de programmation qui tourne une boucle de 30 étapes avec accès au système de fichiers et au shell, ou un agent de recherche orchestrant 5+ appels d’outils par requête, Flash échouera plus souvent dans des endroits coûteux à déboguer. Non pas parce que Flash est mauvais — mais parce que c’est exactement la charge de travail pour laquelle DeepSeek a conçu Pro.
Cadre de décision en production
La sélection n’est pas « lequel est meilleur ». C’est « lequel correspond à cette forme de charge de travail ». Trois règles par défaut fonctionnent bien.
Quand choisir Pro (programmation agentique, raisonnement longue durée, évaluation enterprise)
Pro est le bon choix quand l’une des conditions suivantes est vraie :
- Vous exécutez une boucle d’agent multi-étapes (style Claude Code, OpenCode, tout ce qui implique utilisation d’outils + planification + vérification par tour).
- Votre tâche nécessite un rappel factuel précis sur une longue traîne d’entités — l’écart de 23 points sur SimpleQA prédit de vraies différences d’hallucination ici.
- Vous faites de l’évaluation enterprise où le coût métier d’une mauvaise réponse dépasse le coût par token de plusieurs ordres de grandeur.
- Vous avez besoin d’un raisonnement longue durée sur un contexte de 1M tokens genuinement complet — les chiffres d’efficacité de Pro à 1M de contexte sont la clé architecturale ici.
Quand choisir Flash (classification à haut QPS, résumé, UX de chat)
Flash n’est pas l’option économique. C’est la bonne option quand :
- Vous exécutez de la classification, du balisage ou de l’extraction à haut QPS — la latence et le coût par appel dominent la marge de qualité.
- Résumé et traduction — tâches bornées en un seul passage où le delta de 1-2 points de benchmark de Flash est invisible pour les utilisateurs.
- UX de chat interactif — la latence du premier token importe plus que le 99e percentile de qualité des réponses, et Flash est significativement plus rapide.
- Travail adjacent à l’embedding : réécriture de requêtes, classification d’intention, scoring de pertinence.
Choisir Pro ici gaspille 10× sur les tokens de sortie sans gain perceptible. C’est une moins bonne décision qu’utiliser Flash pour une boucle d’agent.
Routage hybride : Flash par défaut, Pro en repli
Pour la plupart des produits, la bonne architecture n’est ni l’un ni l’autre — c’est les deux, avec un routeur :
- Diriger chaque requête vers Flash par défaut.
- Escalader vers Pro sur un ou plusieurs déclencheurs explicites : échec d’appel d’outil, seuil de confiance non atteint, agent multi-tours entrant dans une phase connue difficile, utilisateur signalant une réponse incorrecte.
- Journaliser le taux d’escalade. Si <5% des requêtes escaladent, Flash couvre votre charge de travail. Si >30%, vous êtes en territoire Pro et le routeur est du surcoût.
Cela fonctionne uniquement parce que Pro et Flash partagent la surface API et le flag de mode de raisonnement. Basculer entre eux en milieu de session est un changement d’une ligne dans la plupart des clients. La documentation officielle de tarification DeepSeek confirme que les IDs de modèles sont des variantes, pas des endpoints cloisonnés.
Compromis coût et latence (à la date de publication)
Les chiffres ci-dessous proviennent de la page de tarification officielle de DeepSeek au 24 avril 2026.
| V4-Flash | V4-Pro | |
|---|---|---|
| Entrée (cache miss) | 0,14 $ / M tok | 1,74 $ / M tok |
| Entrée (cache hit) | 0,028 $ / M tok | 0,145 $ / M tok |
| Sortie | 0,28 $ / M tok | 3,48 $ / M tok |
| Fenêtre de contexte | 1M tokens | 1M tokens |
| Sortie maximale | 384K tokens | 384K tokens |
Divulgation de latence : DeepSeek n’a pas publié de chiffres de latence officiels par niveau pour V4 au moment de la rédaction. Des rapports tiers suggèrent que Flash est nettement plus rapide que Pro, mais je ne peux pas pointer vers un benchmark officiel — à vérifier une fois la préversion stabilisée.
Limitations et ce qui reste à vérifier
Il s’agit d’une version préliminaire. Éléments à signaler avant de router du trafic de production :
- Réplication des benchmarks. Tous les chiffres ci-dessus proviennent du propre rapport technique de DeepSeek. Les classements de type Arena commencent tout juste à enregistrer les résultats V4. Aucun run indépendant SWE-Bench Pro ou Terminal Bench pour l’instant.
- Multimodal : pas encore. Les deux variantes V4 sont texte uniquement. DeepSeek a indiqué que le multimodal est en cours ; aucun calendrier officiel.
- Contexte commercial. La couverture de Bloomberg sur la sortie note que V4 arrive dans un contexte de surveillance géopolitique continue de DeepSeek, et certains déploiements hors Chine ont des restrictions. Vérifiez votre posture de conformité avant de router des données utilisateur via l’API officielle ; l’hébergement autonome des poids open source est la voie propre si c’est une préoccupation.
- Stabilité de la préversion. Le label « preview » est explicite sur la fiche modèle V4-Flash aussi. Attendez-vous à ce que le comportement de l’API et la tarification évoluent.
- Fenêtre de dépréciation. Les IDs
deepseek-chatetdeepseek-reasonersont retirés le 24 juillet 2026. Ils routent actuellement vers V4-Flash. Si vous utilisez ces IDs, vous êtes déjà sur la qualité Flash sans le savoir — migrez explicitement.
C’est là où mes données s’arrêtent. Je continue à surveiller. Je mettrai à jour une fois que les évaluations tierces auront rattrapé.
FAQ

Puis-je basculer entre Pro et Flash en milieu de conversation ?
Oui. Les deux partagent la même surface API et le même format compatible OpenAI. Le basculement est un changement d’ID de modèle dans le corps de la requête. L’historique de conversation (tel que vous le transmettez dans chaque appel) est portable entre les deux.
Les deux supportent-ils reasoning_effort ?
Oui. V4-Pro et V4-Flash supportent tous les deux les trois mêmes modes d’effort de raisonnement — non-thinking, thinking et Think Max — selon les fiches modèles officielles. La tarification ne change pas entre les modes ; vous êtes facturé sur les tokens générés, et Think Max en génère simplement plus.
Quelle version est la meilleure pour les boucles d’agent de style Claude Code ?
Pro. L’écart Terminal Bench 2.0 (67,9 vs 56,9) est le proxy le plus direct pour les boucles shell/outils multi-étapes, et c’est une différence de 11 points. Flash fonctionnera pour les tâches agentiques simples, mais une boucle qui enchaîne 10+ appels d’outils atteint exactement la catégorie où Flash régresse le plus. Le propre langage de positionnement de DeepSeek le dit explicitement — « au niveau de Pro pour les tâches Agent simples », pas toutes les tâches agentiques.
Conditions d’utilisation commerciale pour les deux ?
Les deux sont publiés sous la licence MIT selon les dépôts officiels Hugging Face, ce qui permet l’utilisation commerciale, la modification et la redistribution. Les poids sont hébergeables en autonomie. Pour l’utilisation de l’API hébergée, les conditions de service propres à DeepSeek s’appliquent en plus — vérifiez-les pour votre zone géographique de déploiement.
Les structures de tarification sont-elles identiques ou différentes ?
Même structure, taux différents. Les deux ont des niveaux d’entrée, d’entrée avec cache hit et de sortie. Les deux supportent les remises de cache sur les préfixes répétés. Le ratio entre les taux Pro et Flash est cohérent — Pro est environ 12× plus cher en sortie par token. Aucune tarification par palier ou par engagement sur les docs officiels au moment de la rédaction.
Articles précédents :
- DeepSeek V4 Coût par Million de Tokens : Détail complet de la tarification
- DeepSeek V4 Exigences GPU & VRAM pour l’hébergement autonome
- Claude Opus 4.7 : L’alternative la plus proche en modèle fermé
- Modèles de flux de travail agentiques : Câblage d’outils et modes de défaillance
- MCP en production : Comment le contexte de modèle fonctionne vraiment
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir