Qwen3.5-Omni vs GPT-4o vs Gemini 2.5 Pro: Comparación de Modelos Omni
Qwen3.5-Omni vs GPT-4o y Gemini 2.5 Pro para desarrolladores: benchmarks de audio, voz multilingüe, acceso a API, autoalojamiento y precios comparados.
¡Hola a todos! Soy Dora, quien, como de costumbre, tenía sobre el escritorio la especificación de un proyecto de agente de voz que necesitaba una decisión: en qué familia de modelos construir. GPT-4o era el predeterminado que todos asumían. Gemini 2.5 Pro seguía apareciendo por su techo de contexto. Y luego, Qwen3.5-Omni llegó a finales de marzo, con afirmaciones que me detuvieron a mitad del scroll — 113 idiomas de reconocimiento, ruta de pesos abiertos, precios escalonados, contexto de 256K. No podía ignorarlo.
Así que profundicé. Esto no es un resumen de benchmarks sino una guía de decisión: qué ofrece realmente cada modelo, dónde se sostienen los números y cuál tiene sentido para tu construcción específica.
Cómo Se Posicionan Estos Modelos
Qwen3.5-Omni: Primero en Pesos Abiertos, Viable para Autoalojamiento, Voz Multilingüe
Qwen3.5-Omni es el modelo omni-modal nativo de Alibaba — texto, audio, imagen y video como entrada, texto o voz en tiempo real como salida, todo en una sola llamada de inferencia. Se distribuye en tres variantes: Plus (30B-A3B MoE), Flash (MoE más ligero, menor latencia) y Light (modelo denso más pequeño, pesos abiertos en HuggingFace). La arquitectura es Thinker-Talker — el componente de razonamiento y el componente de síntesis de voz funcionan como un sistema dividido, lo que permite la salida de voz en streaming antes de que se complete la respuesta completa.
La diferenciación más clara es el autoalojamiento. Plus y Flash son accesibles a través de la API de DashScope; la variante Light tiene pesos abiertos. Si la residencia de datos, el ajuste fino o el costo a escala son preocupaciones principales, Qwen3.5-Omni es actualmente la única opción en esta comparación con una ruta de autoalojamiento realista. El modelo admite el formato de API compatible con OpenAI a través de DashScope, lo que reduce la fricción de integración para equipos que ya usan el SDK de OpenAI.
GPT-4o: API Cerrada, Cadena de Herramientas Estrechamente Integrada, Ecosistema OpenAI
GPT-4o es el modelo multimodal insignia de OpenAI, disponible a través de la API estándar de Chat Completions y la API en tiempo real para cargas de trabajo de voz a voz. No existe una ruta de autoalojamiento — está completamente cerrado. Lo que GPT-4o sacrifica en flexibilidad, lo devuelve en madurez del ecosistema: llamadas a funciones, API de Assistants, ajuste fino, API por lotes, intérprete de código, búsqueda de archivos y una cadena de herramientas para desarrolladores que la mayoría de los equipos ya tienen integrada. Si tu stack ya funciona con OpenAI, los costos de cambio son reales.
El audio en GPT-4o se maneja a través de dos rutas distintas: la API de Chat Completions (gpt-4o-audio-preview, asíncrona) y la API en tiempo real (gpt-realtime, WebSocket de baja latencia). Son endpoints separados con precios significativamente diferentes, lo que importa para las decisiones de arquitectura de agentes de voz.
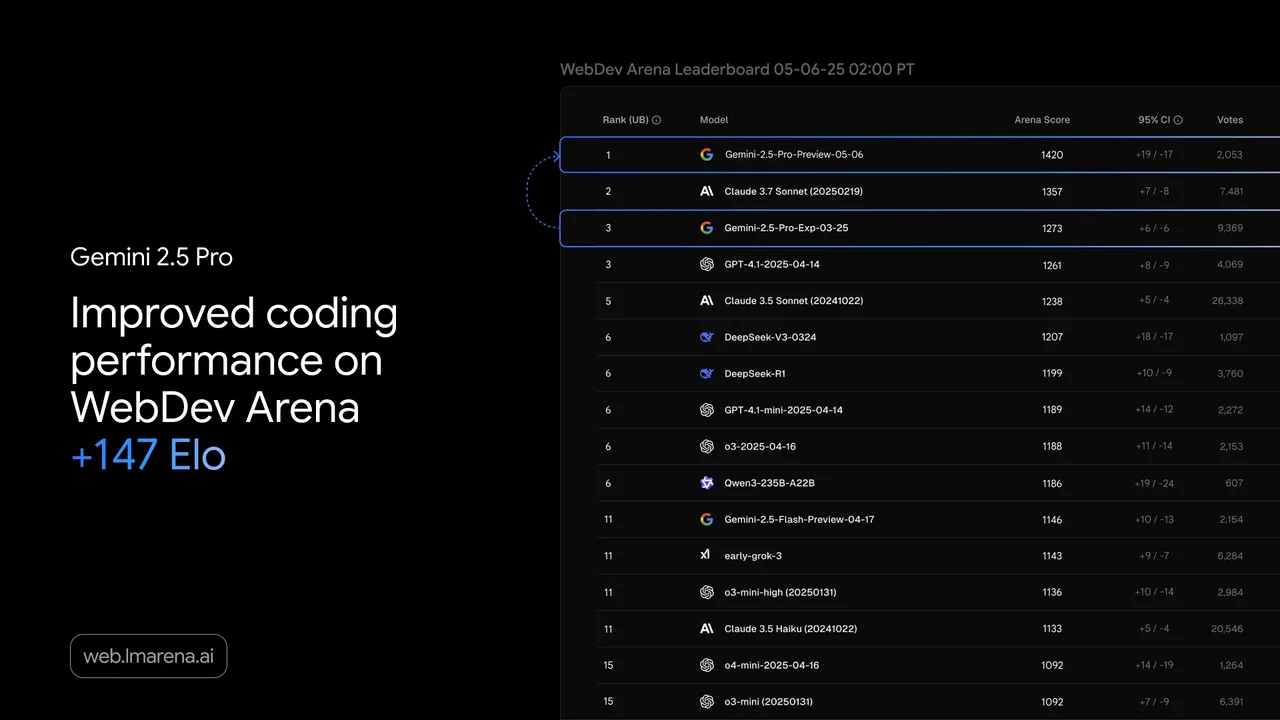
Gemini 2.5 Pro: Infraestructura de Google, Nativo Multimodal, Integración con Vertex AI
Gemini 2.5 Pro es el buque insignia de nivel medio de Google, diseñado para tareas que requieren razonamiento sólido y comprensión multimodal. Admite una ventana de contexto de 1 millón de tokens — la más grande en esta comparación por un factor de cuatro — y está disponible tanto a través de la API para Desarrolladores de Gemini como de Vertex AI. La ruta de Vertex es la empresarial: se integra con Google Cloud IAM, controles de residencia de datos y herramientas de Workspace, pero también introduce precios y consideraciones de bloqueo específicos de Vertex.
La entrada de audio es compatible; la salida de voz nativa en tiempo real se maneja a través de la Live API (conversacional de baja latencia) en lugar del endpoint estándar de completions. Para equipos ya en Google Cloud, la historia de integración es convincente. Para equipos que no están en Google Cloud, Vertex añade fricción de incorporación que la API para Desarrolladores de Gemini evita.
Tabla de Comparación Principal
| Dimensión | Qwen3.5-Omni (Plus) | GPT-4o | Gemini 2.5 Pro |
|---|---|---|---|
| Ventana de contexto | 256K tokens | 128K tokens | 1M tokens |
| Límite de entrada de audio | ~10 hrs continuas | Limitado por contexto de 128K | ~11 hrs con contexto de 1M |
| Idiomas de salida de voz | 36 | ~6 (voces predefinidas) | Limitado (Live API) |
| Idiomas de reconocimiento de voz | 113 | Basado en Whisper (~100) | Fuerte multilingüe |
| Autoalojamiento | ✅ Viable (pesos abiertos Light; Plus/Flash vía API) | ❌ No disponible | ❌ No disponible |
| Pesos abiertos | ✅ Variante Light (HuggingFace) | ❌ | ❌ |
| Modelo de precios | Escalonado por conteo de tokens de entrada por solicitud | Plano por token (audio con precio separado) | Escalonado por longitud de contexto (>200K tasa mayor) |
| Precio de entrada de texto (por 1M) | Varía por nivel; ver DashScope | $2.50 | $1.25 (≤200K tokens) |
| Precio de entrada de audio | Específico por modalidad; ver DashScope | ~$100/1M tokens (Realtime: $32/1M) | ~$1.00/1M (tasa de Gemini 2.5 Flash para audio) |
| Compatibilidad de API | Compatible con OpenAI (DashScope) | OpenAI nativo | Compatible con OpenAI (parcial) |
| Cuota gratuita | 1M tokens (Internacional, 90 días) | Ninguna (solo créditos de prueba) | Nivel gratuito generoso (Google AI Studio) |
| Integración Vertex / empresarial | Solo Alibaba Cloud | Azure OpenAI / acuerdos empresariales | Google Cloud / Vertex AI nativo |
| Estado de lanzamiento | 30 de marzo de 2026 (muy nuevo) | GA, estable en producción | GA, estable en producción |
Datos de precios: texto de GPT-4o de la página de precios de OpenAI; Gemini 2.5 Pro de los precios para Desarrolladores de Google AI; Qwen3.5-Omni de los precios de DashScope. Las tarifas de audio son aproximadas — siempre verifica antes de modelar costos.
Benchmarks de Audio y Voz: Lo Que Significan para los Desarrolladores
Donde Qwen3.5-Omni-Plus Lidera
Alibaba afirma que Qwen3.5-Omni-Plus logró resultados SOTA en 215 subtareas de audio y audio-visual, superando a Gemini 3.1 Pro en benchmarks generales de comprensión de audio, razonamiento, reconocimiento y traducción. En ASR multilingüe específicamente, el salto de 19 idiomas (generación anterior) a 113 es la métrica principal que más importa para equipos con idiomas distintos al inglés como primera prioridad.
En la comprensión de audio-video — tareas como resumir un video con sonido ambiental, responder preguntas sobre una reunión grabada o subtitular contenido de audio — el modelo tiene ventajas arquitectónicas dedicadas: el Thinker procesa todas las modalidades juntas de forma nativa, en lugar de enrutar a través de pilas de encoders separadas.
Donde GPT-4o y Gemini Mantienen Ventajas
La ventaja de GPT-4o no está en benchmarks de audio sin procesar — está en la madurez del ecosistema. Llamadas a funciones en la API en tiempo real, API de Assistants para hilos persistentes, ajuste fino en tus datos de dominio y una cadena de herramientas para desarrolladores que ha sido probada en producción a escala. Si estás construyendo un agente de voz que necesita llamar a APIs externas, gestionar el estado de la conversación o integrarse con flujos de trabajo existentes basados en OpenAI, la madurez de herramientas de GPT-4o es un diferenciador genuino.

Las ventajas de Gemini 2.5 Pro son el contexto y la integración con Google. Para tareas de análisis de audio o video donde deseas procesar horas de contenido en una sola solicitud sin fragmentación, 1M de tokens es el techo práctico de esta comparación. Para equipos en Google Cloud que ejecutan pipelines de Vertex AI, la integración es nativa y contractualmente familiar.
Advertencias sobre Benchmarks: Conteos SOTA vs. Brechas en Despliegue Real
La cifra de “215 resultados SOTA” merece escrutinio antes de que moldee tu decisión. Algunas cosas que debes saber sobre cómo se construye este número:
Primero, los conteos SOTA se agregan en muchas subtareas — pares de idiomas individuales, géneros de audio específicos, categorías de benchmark estrechas. Un modelo puede reclamar cientos de SOTAs mientras pierde en el benchmark específico que más importa para tu caso de uso (digamos, tu idioma, tu vocabulario de dominio, tu perfil de calidad de audio).
Segundo, Qwen3.5-Omni se lanzó a finales de marzo de este año. Las evaluaciones independientes de terceros no existen aún al momento de escribir esto. Las cifras de comparación citadas por Alibaba fueron generadas por el equipo lanzador, utilizando benchmarks que el equipo seleccionó. Eso no es una acusación de deshonestidad — es práctica estándar en los lanzamientos de modelos — pero es la postura epistémica apropiada para mantener hasta que aparezcan evaluaciones neutrales.
Tercero, el rendimiento en benchmarks ≠ rendimiento en producción. La cobertura de acentos, el vocabulario raro, el manejo del ruido de fondo, la terminología específica del dominio y la calidad de audio del mundo real afectan la calidad de ASR en producción de maneras que los benchmarks curados no capturan. Prueba con tus propias muestras de audio antes de comprometerte.

Soporte de Voz Multilingüe
113 Idiomas de Reconocimiento vs. el Enfoque Basado en Whisper de GPT-4o
El reconocimiento de audio de GPT-4o hereda de la arquitectura Whisper, que admite aproximadamente 100 idiomas con calidad variable en todo el rango. El modelo funciona bien en idiomas de alto recurso (inglés, español, francés, mandarín) y se degrada en idiomas y dialectos de menor recurso. OpenAI no publica un desglose de precisión por idioma, lo que hace difícil verificar por adelantado la calidad para idiomas menos comunes.
La afirmación de 113 idiomas de Qwen3.5-Omni es similar en alcance, pero incluye cobertura explícita de dialectos dentro de ese conteo — una distinción que importa para la cobertura de idiomas del sur de Asia, el sudeste asiático y africanos, donde “un idioma” y “sus dialectos” pueden tener una calidad de ASR significativamente diferente. Como con cualquier afirmación de conteo de idiomas, prueba con muestras reales de tus hablantes objetivo. Alibaba tiene historial de conteo generoso de dialectos; calibra en consecuencia.
36 Idiomas de Salida de Voz: ¿Práctico para Qué Mercados?
La salida de voz en 36 idiomas pone a Qwen3.5-Omni por delante de las opciones de voz predefinidas actuales de GPT-4o (principalmente inglés con un pequeño conjunto de idiomas adicionales) para TTS que no sea en inglés. Para equipos de producto que construyen agentes de voz dirigidos a América Latina, el sudeste asiático o mercados europeos multilingües, 36 idiomas de salida es una brecha de capacidad significativa si los idiomas están cubiertos y la calidad es adecuada para tu caso de uso.
La Live API de Gemini 2.5 Pro también admite salida de voz multilingüe, pero la documentación de cobertura de idiomas es menos explícita. Verifica la cobertura para tus idiomas objetivo específicamente antes de comprometer a Qwen o Gemini en un caso de uso de TTS multilingüe.
Interrupción Semántica y Clonación de Voz: ¿Diferenciadores o Características Básicas?
Qwen3.5-Omni introduce la interrupción semántica — el modelo intenta distinguir entre un usuario que genuinamente interrumpe versus el ruido de fondo ambiental. Esta es una mejora real de UX para despliegues de agentes de voz en entornos ruidosos, pero es cada vez más una línea de base esperada en lugar de un diferenciador. Prueba si funciona de manera confiable en tu entorno acústico antes de tratarlo como un factor de decisión.
La clonación de voz (cargar una muestra de voz, el modelo responde con esa voz) está disponible en Plus y Flash a través de la API. La API en tiempo real de GPT-4o admite voz personalizada mediante ajuste fino pero no expone la clonación de voz directa de la misma manera. Esta es una diferencia de capacidad genuina si la consistencia de la persona de voz a lo largo de conversaciones largas es un requisito del producto.
Acceso a API e Idoneidad de Infraestructura
DashScope vs. API de OpenAI vs. Google Vertex: Complejidad de Integración
Para equipos que ya usan el SDK de OpenAI, el endpoint compatible con OpenAI de DashScope es sencillo de apuntar:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_DASHSCOPE_API_KEY",
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
)
response = client.chat.completions.create(
model="qwen3-omni-flash", # or qwen3-omni-plus
messages=[{"role": "user", "content": "Your message here"}]
)Para entradas multimodales (audio, video), usarás el endpoint multimodal nativo de DashScope, que tiene una estructura de solicitud ligeramente diferente. La compatibilidad con OpenAI se aplica principalmente a las rutas de completions de texto. Verifica qué endpoints admiten qué modalidades antes de construir tu pipeline de audio.
La integración de Google Vertex AI es la más compleja de las tres — requiere configuración de proyecto en Google Cloud, configuración de IAM y utiliza el SDK de Vertex o la API para Desarrolladores de Gemini, que tienen flujos de autenticación diferentes y un comportamiento ligeramente distinto. La recompensa es controles de acceso de grado empresarial, documentación de cumplimiento y el marco de SLA de Google.
Autoalojamiento: Solo Qwen3.5-Omni Ofrece una Ruta Realista
Esta es la diferencia estructuralmente más significativa en esta comparación. GPT-4o y Gemini 2.5 Pro son modelos de pesos cerrados — no existe una ruta de autoalojamiento, punto final. Si tu caso de uso requiere que los datos nunca salgan de tu propia infraestructura (ciertos contextos de salud, financieros o de defensa), o si necesitas ajustar con datos de audio propietarios a nivel de modelo, solo Qwen3.5-Omni te da una ruta.
La variante Light tiene pesos abiertos en HuggingFace. Plus y Flash son solo API a partir del 31 de marzo de 2026 — los pesos abiertos para estas variantes no han sido confirmados como lanzados públicamente al momento de escribir esto. Si la calidad a nivel Plus con autoalojamiento completo es tu requisito, verifica el estado actual de pesos abiertos antes de planificar tu arquitectura en torno a ello.
Para requisitos de autoalojamiento, la documentación de despliegue de vLLM y el GitHub oficial del equipo Qwen son las referencias autorizadas para la configuración.
Residencia de Datos y Geografía de Endpoints
Para equipos fuera de China, el endpoint Internacional (Singapur) de DashScope es el predeterminado. El endpoint de Virginia (EE.UU.) está disponible pero no tiene cuota gratuita y, al momento de escribir esto, confirma el soporte multimodal (audio/video) para modelos Omni específicamente antes de enrutar tráfico de producción allí.
Comparación de Estructura de Precios
Niveles de Tokens de Entrada vs. Precios Planos por Llamada
La arquitectura fundamental de precios difiere entre los tres proveedores:
Qwen3.5-Omni (DashScope): Precios escalonados basados en el conteo de tokens de entrada de la solicitud actual. Cruzar un límite de nivel dentro de una sola solicitud eleva la tasa de entrada de toda la solicitud — no solo los tokens por encima del umbral. Esto significa que un clip de audio de 35K tokens y una consulta de texto de 5K tokens tienen precios a diferentes tarifas por token, incluso si tu volumen mensual es idéntico. Las solicitudes cortas son baratas; las solicitudes de audio de contexto largo se encarecen más rápido de lo que sugeriría un modelo de tarifa plana.
GPT-4o: Precios planos por token para texto ($2.50 entrada / $10.00 salida por 1M tokens). El audio es una partida separada completamente: la ruta de audio de Chat Completions ejecuta ~$100/1M tokens de entrada de audio; la API en tiempo real (gpt-realtime) ejecuta $32/1M de entrada de audio y $64/1M de salida de audio después de una reciente reducción de precio del 20%. Los tokens de texto en la API en tiempo real son $4.00 entrada / $16.00 salida — significativamente más altos que la tarifa estándar de Chat Completions.
Gemini 2.5 Pro: Escalonado por longitud de contexto, pero la estructura es más simple: tarifa estándar ($1.25 entrada / $10.00 salida por 1M tokens) para prompts ≤200K tokens; tarifa 2x para prompts >200K tokens. La entrada de audio tiene un precio premium sobre el texto — aproximadamente 3x para el nivel Flash; verifica las tarifas de audio Pro en la documentación de precios para Desarrolladores de Google AI. El modo por lotes reduce las tarifas en un 50% para cargas de trabajo asíncronas.
Costo a Escala: Cargas de Trabajo de Voz / Audio de Alto Volumen
Para una comparación concreta, considera una carga de trabajo de 100,000 minutos de entrada de audio por mes — aproximadamente una operación de transcripción o agente de voz de escala media:
- A ~427 tokens/minuto de audio (basado en las matemáticas de contexto publicadas por Qwen), eso es ~42.7M tokens de entrada de audio/mes
- GPT-4o Realtime a $32/1M de entrada de audio: ~$1,366/mes solo por entrada de audio, antes de los costos de entrada/salida de texto
- Audio de Gemini 2.5 Pro (a ~$1.00/1M para el nivel Flash más corto, Pro puede diferir): ~$427/mes si está dentro del rango de contexto estándar — verifica las tarifas de audio Pro
- Qwen3.5-Omni: El costo depende completamente de cómo se agrupa el audio en solicitudes; cada solicitud que cruza un límite de nivel paga la tasa más alta para toda la solicitud. No se puede dar un número fijo sin conocer la distribución del tamaño de tus solicitudes
A muy alto volumen con tamaños de solicitud predecibles, vale la pena calcular el autoalojamiento de la variante Flash o Light de Qwen3.5-Omni. Una sola H100 80GB ejecutando Flash en FP8 puede manejar la inferencia en producción a una tarifa horaria de GPU que supera los costos de API pasado cierto volumen mensual.
Marco de Decisión: Cuándo Usar Cuál
Elige Qwen3.5-Omni Si:
- El autoalojamiento es obligatorio — la residencia de datos, el ajuste fino o la independencia del proveedor son innegociables. Este es el único modelo en esta comparación con una ruta de pesos abiertos.
- La voz multilingüe es el caso de uso principal — 113 idiomas ASR y 36 idiomas TTS, combinados con arquitectura omni-modal nativa, es una ventaja de capacidad significativa para productos con idiomas distintos al inglés como primera prioridad. Verifica que tus idiomas específicos funcionen con calidad aceptable.
- La sensibilidad al costo a escala importa — a alto volumen, la variante Flash o Light autoalojada puede superar significativamente los precios de API. En uso puro de API, modela cuidadosamente los precios escalonados para la distribución de tamaño de tus solicitudes antes de asumir que es más barato.
- Necesitas clonación de voz o consistencia de persona de voz a lo largo de conversaciones largas — esto es actualmente más accesible en Qwen3.5-Omni que en GPT-4o o Gemini.

Elige GPT-4o Si:
- El ecosistema OpenAI ya está en tu stack — API de Assistants, ajuste fino, llamadas a funciones, API por lotes. Los costos de cambio son reales; la madurez de herramientas es genuina.
- La madurez de herramientas importa más que el costo — para agentes de voz que necesitan llamadas a herramientas complejas, gestión de estado multi-turno o integración con flujos de trabajo existentes de OpenAI, el historial de producción de GPT-4o es el más sólido de los tres.
- Estás construyendo principalmente en inglés o idiomas europeos occidentales de alto recurso — la calidad de ASR de GPT-4o para estos idiomas está bien probada y es confiable en producción.
Elige Gemini 2.5 Pro Si:
- Google Cloud es tu infraestructura — la integración nativa con Vertex AI, GCP IAM y los acuerdos empresariales son ventajas reales si ya estás en el ecosistema de Google.
- Necesitas contexto de 1M+ tokens — para procesar grabaciones muy largas, análisis de contenido de varias horas o mantener un historial de conversación muy largo sin fragmentación, el techo de contexto de Gemini es el claro ganador en esta comparación.
- La integración con Google Workspace importa — para casos de uso empresarial que involucran Docs, Drive, Meet u otros productos de Workspace, la ruta de integración Gemini-Workspace es más natural que las alternativas.
Limitaciones que Debes Conocer Antes de Comprometerte
Qwen3.5-Omni: Sobrecarga de Inferencia MoE, Estabilidad de API en Etapa Temprana
La arquitectura MoE de la variante Plus significa que el rendimiento de inferencia es menos predecible que un modelo denso de calidad equivalente. Bajo concurrencia variable, la sobrecarga de enrutamiento puede causar picos de latencia. vLLM mitiga esto significativamente sobre HuggingFace Transformers para despliegues autoalojados, pero no lo elimina — la latencia de enrutamiento MoE es inherente a la arquitectura.
La estabilidad de la API es una pregunta abierta. Los límites de velocidad no están documentados públicamente por ahora. El comportamiento del endpoint bajo carga, los compromisos de SLA y las garantías de fijación de versión son todos desconocidos en esta etapa. Para despliegues de producción con requisitos de tiempo de actividad, planifica una alternativa.
GPT-4o: Sin Autoalojamiento, Opacidad de Precios a Escala
Sin autoalojamiento, punto final. Si este es un requisito estricto, GPT-4o no es candidato.
El precio del audio a través de la API en tiempo real ($32/1M entrada, $64/1M salida) no es barato a escala, y la estructura de facturación — tarifas separadas para tokens de texto y audio en la misma conversación — puede producir sorpresas en la factura si los desarrolladores asumen que se aplican las tarifas estándar de Chat Completions. La gestión de ventana de contexto basada en sesiones de la API en tiempo real también añade complejidad de costos para conversaciones largas.
El historial de precios de OpenAI para modelos y características ha incluido tanto reducciones como reestructuraciones. Para un modelo de costos que necesite mantenerse por 12+ meses, los precios de OpenAI son menos predecibles que los de Google.
Gemini 2.5 Pro: Bloqueo en Vertex, Accesibilidad en China
La integración con Vertex AI es una ventaja genuina para equipos de Google Cloud y una restricción genuina para todos los demás. Las características empresariales, los controles de residencia de datos y las herramientas de cumplimiento son nativas de Vertex; la API para Desarrolladores de Gemini tiene menos controles empresariales. Los equipos que comienzan en la API para Desarrolladores y migran a Vertex para producción encontrarán un SDK diferente, autenticación diferente y facturación diferente.
Los modelos Gemini no son accesibles de manera confiable desde China continental. Si tu equipo o tus usuarios operan en China, la ruta de DashScope es la opción práctica.
El umbral de precios de 200K tokens de Gemini 2.5 Pro también merece atención: si tu solicitud promedio supera consistentemente los 200K tokens, estás pagando el doble de la tasa de entrada anunciada. Para que el contexto de 1M sea rentable, necesitas cargas de trabajo que realmente se beneficien de la ventana completa sin alcanzar el nivel 2x con demasiada frecuencia.
Preguntas Frecuentes
¿Es Qwen3.5-Omni mejor que GPT-4o para aplicaciones de voz multilingüe?
En papel y por benchmark, Qwen3.5-Omni-Plus lidera en conteo de idiomas (113 ASR, 36 TTS) y en benchmarks de comprensión de audio-video. En la práctica, la respuesta depende de tus idiomas específicos, tu calidad de audio y tu dominio. Qwen3.5-Omni se lanzó el 30 de marzo de 2026 — las evaluaciones de producción independientes aún no existen. Prueba con muestras reales de tus usuarios objetivo antes de decidir.
¿Puedo ejecutar Qwen3.5-Omni en producción sin usar DashScope?
La variante Light está disponible como pesos abiertos en HuggingFace, adecuada para despliegues de producción autoalojados en hardware apropiado. Plus y Flash son actualmente solo API a través de DashScope. Los pesos abiertos para Plus/Flash no han sido confirmados a partir del 31 de marzo de 2026 — verifica el estado actual antes de planificar un despliegue autoalojado de Plus.
¿Qwen3.5-Omni admite el formato de API de OpenAI?
Sí. DashScope expone un endpoint compatible con OpenAI en https://dashscope-intl.aliyuncs.com/compatible-mode/v1, que admite el formato de API de Chat Completions. Esto funciona para entradas de texto y texto+visión. Para entradas de audio y video, verifica si la modalidad específica que necesitas se maneja a través del endpoint compatible o requiere el endpoint multimodal nativo de DashScope — la capa de compatibilidad no cubre todas las modalidades por igual.
Publicaciones anteriores:
- GLM-5 vs DeepSeek V3 vs GPT-5: Velocidad y Costo para Desarrolladores
- ¿Qué es GLM-5? Arquitectura, Velocidad y Acceso a API
- Precios de DeepSeek V4: 20-50x Más Barato que OpenAI (Desglose de Costos)
- Contexto de 1M Tokens de DeepSeek V4: Cómo Hacer Prompt de Bases de Código Completas
- Velocidad de Inferencia de GLM-5 en WaveSpeed: Latencia y Rendimiento
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber