DeepSeek V4 Pro vs Flash: ¿Cuál elegir para producción?
Compara DeepSeek V4 Pro vs V4 Flash para producción: compensaciones de capacidad, latencia, costo y qué versión se adapta a tu carga de trabajo.

DeepSeek lanzó V4 como dos modelos, no uno: V4-Pro con 1,6 billones de parámetros totales y 49B activados, y V4-Flash con 284B totales y 13B activados. Ambos comparten una ventana de contexto de 1M de tokens. Ambos son de pesos abiertos bajo licencia MIT. Ambos se publican en la misma superficie de API.
Eso importa porque la decisión ya no es “usar DeepSeek o no.” Es cuál de los dos colocar detrás de qué endpoint. Y la respuesta correcta rara vez es “simplemente usar Pro en todas partes.”
Esta es una guía de selección para equipos de productos de IA y líderes de ingeniería que intentan enrutar cargas de trabajo correctamente. Si has leído mi artículo anterior sobre las características de DeepSeek V4 para desarrolladores de API, eso era la era de modelo único. Esta es la versión de dos niveles.
Todos los números a continuación son a la fecha de publicación. Cualquier cosa que no pueda verificar contra documentación oficial está marcada explícitamente.
DeepSeek V4 Pro vs Flash de un vistazo
Posicionamiento de cada versión (según vista previa oficial)
Según la tarjeta del modelo V4-Pro de DeepSeek en Hugging Face, la división es intencional — no son el mismo modelo en diferentes tamaños. Flash se entrena por separado, no se destila de Pro.
El propio encuadre de DeepSeek:
- V4-Pro — amplio conocimiento del mundo que supera a los modelos abiertos, razonamiento de clase mundial en matemáticas/STEM/programación, el más fuerte en tareas agénticas.
- V4-Flash — el razonamiento “se aproxima mucho” a Pro, rinde a la par de Pro en tareas agénticas simples, más débil en las complejas. Más económico de servir, respuestas más rápidas.
La distinción entre “simple y complejo” es toda la decisión. DeepSeek te está diciendo directamente dónde falla Flash. No lo ignores.
Características compartidas (contexto de 1M, modo de razonamiento, compatibilidad de API)
Las características que son idénticas en ambas variantes:
- Ventana de contexto de 1M de tokens en ambas variantes, habilitada por la arquitectura de atención híbrida de DeepSeek (CSA + HCA). Según la tarjeta de Hugging Face, Pro solo necesita el 27% de los FLOPs por token y el 10% del caché KV frente a V3.2 en contexto de 1M.
- Tres modos de esfuerzo de razonamiento — sin razonamiento, razonamiento (alto) y Think Max. Mismo indicador de API, misma superficie de comportamiento.
- API de Chat Completions compatible con OpenAI y soporte para el protocolo de Anthropic. El mismo
base_url, solo cambia el ID del modelo. - Licencia MIT sobre los pesos para ambos, según los repositorios oficiales.
Si estás migrando entre ellos, la superficie de integración no cambia. Solo el ID del modelo y la factura.
Diferencias de capacidad
Donde divergen es en categorías de evaluación específicas — y el patrón es lo suficientemente consistente como para construir una regla de enrutamiento.
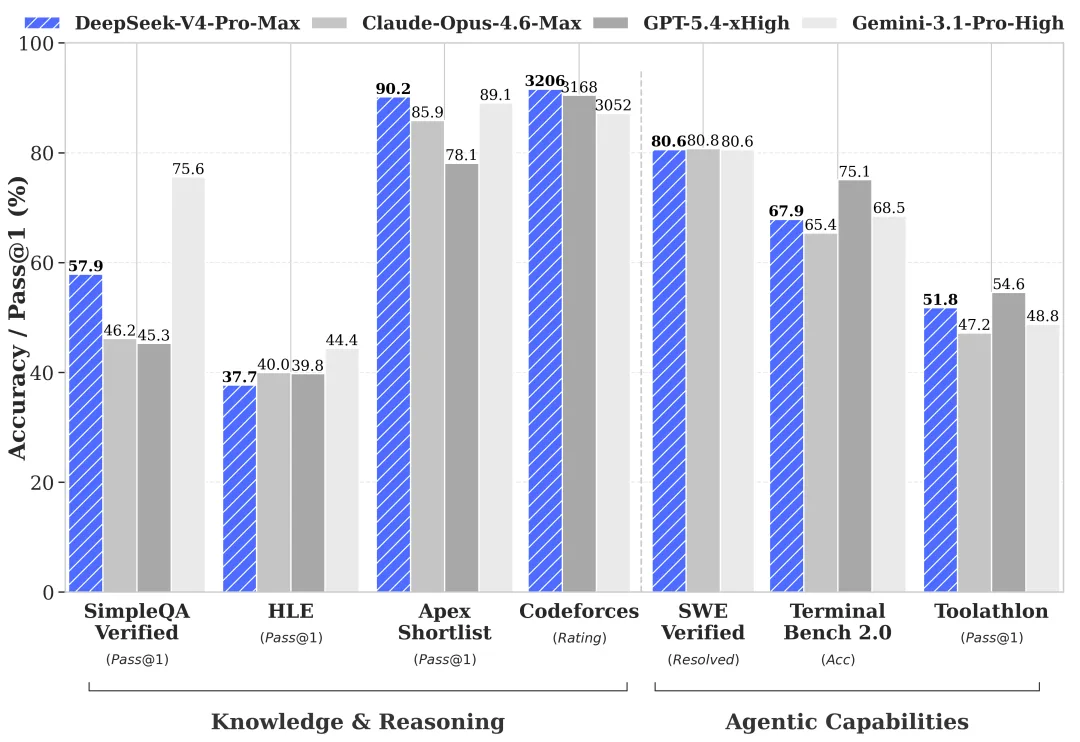
Conocimiento del mundo: Pro lidera, Flash queda atrás (según benchmarks oficiales — requiere verificación)
Los benchmarks de vista previa propios de DeepSeek, resumidos en su tarjeta HF e informe técnico, muestran que la brecha Pro/Flash es estrecha en la mayoría de las categorías de evaluación — pero amplia en algunos lugares específicos:
| Benchmark | V4-Pro | V4-Flash | Diferencia |
|---|---|---|---|
| MMLU-Pro | 87,5 | 86,2 | 1,3 |
| LiveCodeBench | 93,5 | 91,6 | 1,9 |
| SWE-Verified | 80,6 | 79 | 1,6 |
| Codeforces | 3206 | 3052 | ~150 Elo |
| SimpleQA-Verified | 57,9 | 34,1 | 23,8 |
| Terminal Bench 2.0 | 67,9 | 56,9 | 11 |
Números reportados por DeepSeek. No existe replicación por terceros en este momento — requiere verificación antes de su adopción en producción. Pero la forma de la brecha es la señal, no los dígitos exactos.
SimpleQA-Verified es recuperación de hechos. Terminal Bench 2.0 es uso de herramientas en múltiples pasos. Flash sufre un golpe real en ambos. Eso es consistente con lo que DeepSeek dijo en lenguaje claro: tareas simples bien, cargas de trabajo agénticas complejas más débiles.
Paridad de razonamiento en tareas simples
En programación, matemáticas y razonamiento acotado, la brecha se cierra a 1-3 puntos. LiveCodeBench y MMLU-Pro colocan a Flash a muy poca distancia de Pro. Para la mayoría de las llamadas de inferencia en un producto típico — turno de chat, generación de un solo disparo, una finalización de código, una resumención — Flash no es una degradación de ninguna forma que los usuarios noten.
Esa es la esencia de la propuesta de valor de Flash: no es un Pro recortado. Es un modelo entrenado por separado que resulta estar cerca de Pro en la parte media de la distribución de benchmarks.
Divergencia en tareas agénticas con cargas de trabajo de alta complejidad
La categoría de largo horizonte, múltiples herramientas y múltiples saltos es donde los dos se separan. Terminal Bench 2.0 y Toolathlon son las evaluaciones relevantes aquí. La brecha de 11 puntos en Terminal Bench no es un margen que puedas desestimar como ruido de evaluación.
Si tu producto es un agente de programación que ejecuta un bucle de 30 pasos con acceso al sistema de archivos y al shell, o un agente de investigación que orquesta más de 5 llamadas a herramientas por consulta, Flash fallará con más frecuencia en lugares que son costosos de depurar. No porque Flash sea malo — sino porque esta es exactamente la carga de trabajo para la que DeepSeek construyó Pro.
Marco de decisión para producción
La selección no es “cuál es mejor.” Es “cuál coincide con la forma de esta carga de trabajo.” Tres valores predeterminados funcionan bien.
Cuándo elegir Pro (programación agéntica, razonamiento de largo horizonte, evaluación empresarial)
Pro es la elección correcta cuando alguno de los siguientes es verdadero:
- Estás ejecutando un bucle de agente de múltiples pasos (estilo Claude Code, OpenCode, cualquier cosa con uso de herramientas + planificación + verificación por turno).
- Tu tarea requiere recuperación precisa de hechos sobre una larga cola de entidades — la brecha de 23 puntos de SimpleQA predice diferencias reales de alucinación aquí.
- Estás haciendo evaluación empresarial donde el costo de negocio de una respuesta incorrecta supera el costo por token en órdenes de magnitud.
- Necesitas razonamiento de largo horizonte en un contexto genuinamente completo de 1M de tokens — los números de eficiencia de Pro en contexto de 1M son la historia de la arquitectura aquí.
Cuándo elegir Flash (clasificación de alto QPS, resumención, UX de chat)
Flash no es la opción económica. Es la opción correcta cuando:
- Estás ejecutando clasificación, etiquetado o extracción de alto QPS — la latencia y el costo por llamada dominan el margen de calidad.
- Resumención y traducción — tareas acotadas de un solo paso donde el delta de 1-2 puntos en benchmark de Flash es invisible para los usuarios.
- UX de chat interactivo — la latencia del primer token importa más que el percentil 99 de calidad de respuesta, y Flash es significativamente más rápido.
- Trabajo adyacente a embeddings: reescritura de consultas, clasificación de intención, puntuación de relevancia.
Elegir Pro aquí desperdicia 10× en tokens de salida sin ganancia perceptible. Eso es una peor decisión que usar Flash para un bucle de agente.
Enrutamiento híbrido: Flash por defecto, Pro como respaldo
Para la mayoría de los productos, la arquitectura correcta no es ninguno/ninguno — es ambos, con un enrutador:
- Enruta cada solicitud a Flash por defecto.
- Escala a Pro en uno o más desencadenantes explícitos: fallo de llamada a herramienta, umbral de confianza no alcanzado, agente de múltiples turnos que entra en una fase conocida difícil, usuario marca una respuesta como incorrecta.
- Registra la tasa de escalada. Si <5% de las solicitudes escalan, Flash está cubriendo tu carga de trabajo. Si >30%, estás en territorio Pro y el enrutador es sobrecarga.
Esto solo funciona porque Pro y Flash comparten la superficie de API y el indicador de modo de razonamiento. Cambiar entre ellos a mitad de sesión es un cambio de una línea en la mayoría de los clientes. La documentación oficial de precios de DeepSeek confirma que los IDs de modelo son hermanos, no endpoints aislados.
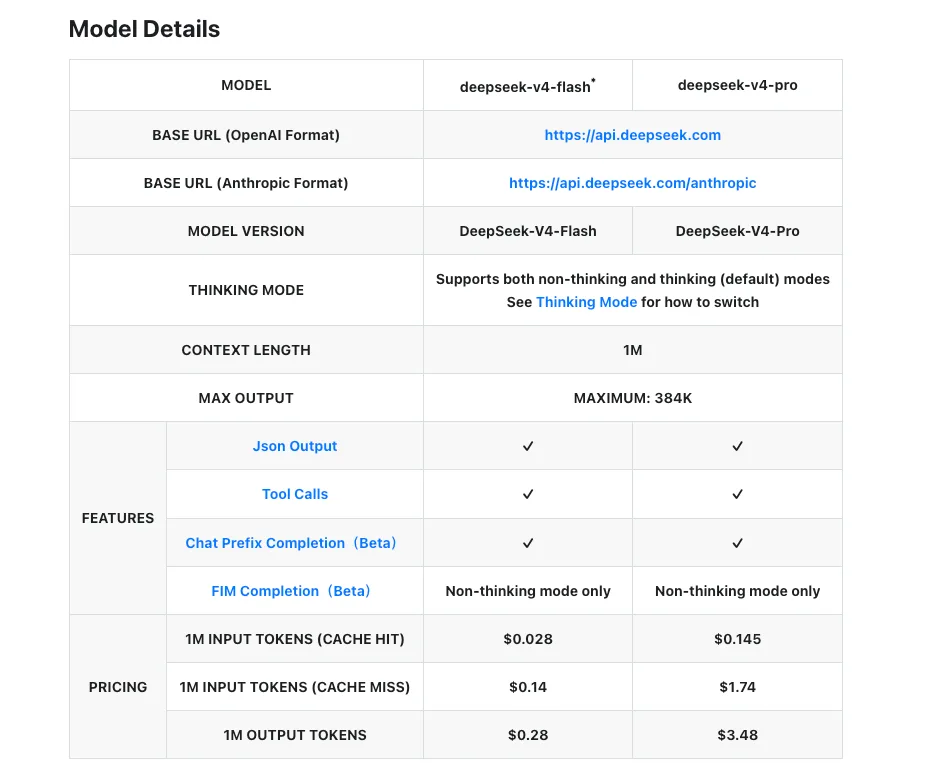
Compensaciones de costo y latencia (a la fecha de publicación)
Los números a continuación son de la página oficial de precios de DeepSeek a partir del 24 de abril de 2026.
| V4-Flash | V4-Pro | |
|---|---|---|
| Entrada (fallo de caché) | $0,14 / M tok | $1,74 / M tok |
| Entrada (acierto de caché) | $0,028 / M tok | $0,145 / M tok |
| Salida | $0,28 / M tok | $3,48 / M tok |
| Ventana de contexto | 1M tokens | 1M tokens |
| Salida máxima | 384K tokens | 384K tokens |
Divulgación de latencia: DeepSeek no ha publicado números oficiales de latencia por nivel para V4 al momento de escribir esto. Reportes de terceros sugieren que Flash sirve notablemente más rápido que Pro, pero no puedo señalar un benchmark oficial — requiere verificación una vez que la vista previa se estabilice.
Limitaciones y lo que aún requiere verificación
Esta es una versión preliminar. Cosas a marcar antes de comprometer tráfico de producción:
- Replicación de benchmarks. Todos los números anteriores provienen del propio informe técnico de DeepSeek. Los rankings estilo Arena apenas están comenzando a registrar resultados de V4. No hay ejecuciones independientes de SWE-Bench Pro o Terminal Bench aún.
- Multimodal: todavía no. Ambas variantes de V4 son solo texto. DeepSeek ha dicho que el multimodal está en progreso; no hay cronograma registrado.
- Contexto comercial. La cobertura de Bloomberg del lanzamiento señala que V4 llega en medio del escrutinio geopolítico continuo de DeepSeek, y algunos despliegues no chinos tienen restricciones. Verifica tu postura de cumplimiento antes de enrutar datos de usuarios a través de la API oficial; el autoalojamiento de los pesos abiertos es el camino limpio si eso es una preocupación.
- Estabilidad de la vista previa. La etiqueta “vista previa” también es explícita en la tarjeta del modelo V4-Flash. Espera que el comportamiento de la API y los precios cambien.
- Ventana de deprecación. Los IDs
deepseek-chatydeepseek-reasonerse retiran el 24 de julio de 2026. Actualmente enrutan a V4-Flash. Si estás en esos IDs, ya estás en la calidad de Flash sin saberlo — migra explícitamente.
Ahí es donde terminan mis datos. Sigo observando. Actualizaré una vez que las evaluaciones de terceros se pongan al día.
Preguntas frecuentes

¿Puedo cambiar entre Pro y Flash a mitad de conversación?
Sí. Ambos comparten la misma superficie de API y el mismo formato compatible con OpenAI. Cambiar es un cambio de ID de modelo en el cuerpo de la solicitud. El historial de conversación (tal como lo pasas en cada llamada) es portable entre los dos.
¿Ambos admiten reasoning_effort?
Sí. Tanto V4-Pro como V4-Flash admiten los mismos tres modos de esfuerzo de razonamiento — sin razonamiento, razonamiento y Think Max — según las tarjetas de modelo oficiales. El precio no cambia entre modos; se factura por tokens generados, y Think Max simplemente genera más.
¿Qué versión es mejor para bucles de agente estilo Claude Code?
Pro. La brecha de Terminal Bench 2.0 (67,9 vs 56,9) es el proxy más directo para bucles de shell/herramienta de múltiples pasos, y eso es una diferencia de 11 puntos. Flash funcionará para tareas agénticas simples, pero un bucle que encadena 10+ llamadas a herramientas alcanza exactamente la categoría donde Flash retrocede más. El propio lenguaje de posicionamiento de DeepSeek lo dice explícitamente — “a la par con Pro para tareas agénticas simples,” no todas las tareas agénticas.
¿Términos de uso comercial para ambos?
Ambos se publican bajo la Licencia MIT según los repositorios oficiales de Hugging Face, que permite uso comercial, modificación y redistribución. Los pesos son autoalojables. Para el uso de la API alojada, los propios términos de servicio de DeepSeek se aplican además — verifícalos para tu geografía de despliegue.
¿Las estructuras de precios son idénticas o diferentes?
Misma estructura, diferentes tarifas. Ambos tienen niveles de entrada, entrada con acierto de caché y salida. Ambos admiten descuentos de caché en prefijos repetidos. La relación entre las tarifas de Pro y Flash es consistente — Pro es aproximadamente 12× más caro en salida por token. No hay precios por nivel de plan o basados en compromisos en los documentos oficiales al momento de escribir esto.
Publicaciones anteriores:
- Costo de DeepSeek V4 por millón de tokens: desglose completo de precios
- Requisitos de GPU y VRAM de DeepSeek V4 para autoalojamiento
- Claude Opus 4.7: La alternativa de modelo cerrado más cercana
- Patrones de flujo de trabajo agéntico: cableado de herramientas y modos de fallo
- MCP en producción: cómo funciona realmente el contexto del modelo
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber