GPT-5.5 API-Verfügbarkeit: Was Teams jetzt planen sollten
GPT-5.5 ist angekündigt, aber der API-Zugang ist noch nicht vollständig verfügbar. Hier ist, was Teams jetzt planen können und was noch überprüft werden muss.

Letzten Freitag habe ich einen Codex-Workflow auf GPT-5.5 umgeleitet und dann den Montag damit verbracht, zwei Kunden zu erklären, warum die Einführungsentscheidung komplizierter ist, als die Schlagzeilen zum Launch vermuten lassen. Mein Name taucht in vielen „Sollen wir migrieren?”-Dokumenten bei WaveSpeedAI auf — ich bin Dora, die Person, die Teams zwei Wochen warten lässt, bevor ein Modellwechsel abgezeichnet wird. Die API ist live. Das ist der Teil, den die meisten Berichte richtig wiedergeben und dabei stehen lassen. Ich möchte über die zehn Tage nach dem Launch schreiben, wenn aus „verfügbar” ein „tatsächlich integriert” wird — und wo die meisten Teams, mit denen ich arbeite, ins Stolpern geraten.
Das hier ist eine Planungsnotiz, kein Tutorial. Wer curl-Beispiele sucht, ist bei der offiziellen Dokumentation besser aufgehoben als bei mir.
Wo GPT-5.5 heute verfügbar ist
Rollout-Status in ChatGPT und Codex
GPT-5.5 ging am 23. April 2026 für Plus-, Pro-, Business- und Enterprise-Nutzer in ChatGPT und Codex live, wobei GPT-5.5 Pro auf Pro-, Business- und Enterprise-Tiers beschränkt ist. In Codex wird das Modell mit einem 400K-Kontextfenster und einem Fast-Modus ausgeliefert, der 1,5-mal schneller läuft und das 2,5-fache kostet — Details, die die offizielle GPT-5.5-Ankündigung auf OpenAI klar darlegt. Der Launch umfasste am ersten Tag nur Consumer-Oberflächen. Das möchte ich hervorheben, weil die Hälfte der Tickets, die ich letzte Woche gesehen habe, von Anfang an API-Parität annahm.
Was OpenAI zur API-Verfügbarkeit sagt
Was der frühe Presszyklus verpasst hat: Der API-Zugang folgte einen Tag später, am 24. April 2026. Sowohl gpt-5.5 als auch gpt-5.5-pro sind nun in den Responses- und Chat-Completions-APIs verfügbar, bestätigt in OpenAIs eigener GPT-5.5-Modelldokumentation. Das Kontextfenster beträgt auf der API-Oberfläche 1M Token, was sich von der 400K-Obergrenze in Codex unterscheidet. Zwei Oberflächen, zwei Limits — leicht zu verwechseln und es lohnt sich, das aufzuschreiben, bevor es die eigenen Entwickler tun. Die Frage lautet also nicht mehr „Wann kann mein Team es nutzen?” Sondern: „Sollten wir es — und was überprüfen wir zuerst?”
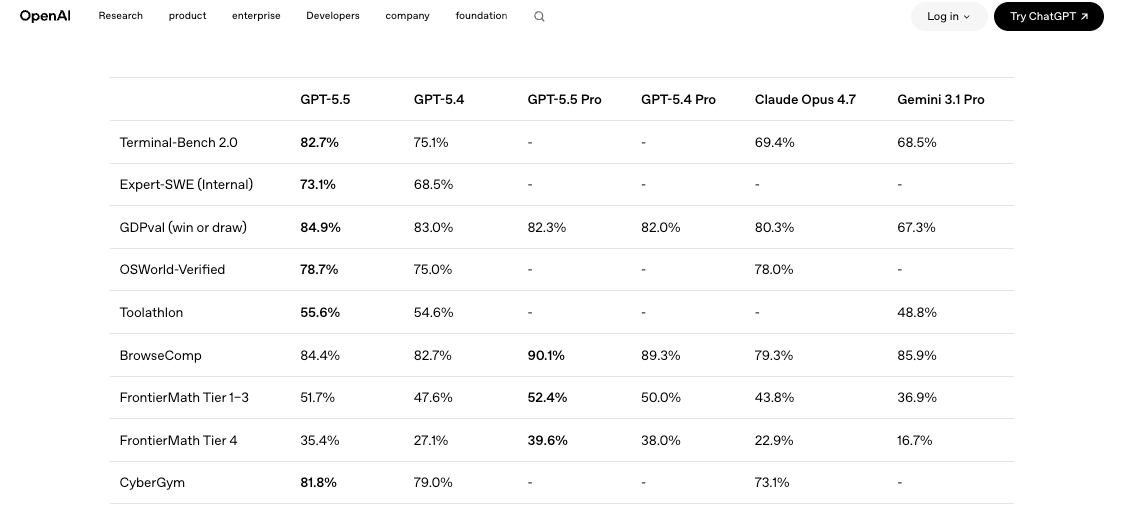
Was Teams vor der API-Integration sicher planen können
Bewertungskriterien und Migrationsvorbereitung
Eine Migration am selben Tag empfehle ich nicht. Folgendes würde ich zuerst festlegen.
Einen kleinen Eval-Rahmen gegen das aktuelle Modell aufbauen. Fünf bis zehn repräsentative Prompts aus der echten Arbeitslast, bewertet nach den Dimensionen, die tatsächlich relevant sind: Korrektheit, Token-Kosten, Latenz, Wiederholungsrate. GPT-5.4 und GPT-5.5 nebeneinander laufen lassen — gleiche Prompts, gleiche Temperatureinstellungen, gleiche Tool-Definitionen. Unabhängige Benchmarks wie der Vergleich auf LLM Stats zeigen, dass GPT-5.5 bei 9 von 10 gemeinsamen Benchmarks gewinnt, auf SWE-Bench Pro aber nur marginale Verbesserungen erzielt. Übersetzt: Das Upgrade ist real, aber nicht gleichmäßig besser. Die eigene Arbeitslast entscheidet.
Den Fallback-Pfad jetzt festlegen, nicht nach dem ersten 429. Neue Modell-Releases werden historisch gesehen in den ersten 30 Tagen mit engeren Rate-Limits ausgeliefert. GPT-5.4 als Fallback eingebunden haben, bevor eine einzige Produktionsanfrage umgestellt wird. Ich habe zwei Teams beobachtet, die diesen Schritt übersprungen haben und dafür bei einem Traffic-Spike am Launch-Tag bezahlt haben.
Fragen für Einkauf, Sicherheit und Engineering
Ein paar, die ich diese Woche beantworten musste:
- Die Preise haben sich verdoppelt. Der Standardpreis beträgt $5 pro 1M Input-Token und $30 pro 1M Output, laut der offiziellen OpenAI-Preisseite. Pro kostet $30 / $180. Token-Effizienzversprechen gleichen das bei Codex-Workloads teilweise aus, aber bei den meisten anderen Workloads sollte man mit einem deutlich steigenden Rechnungsbetrag rechnen.
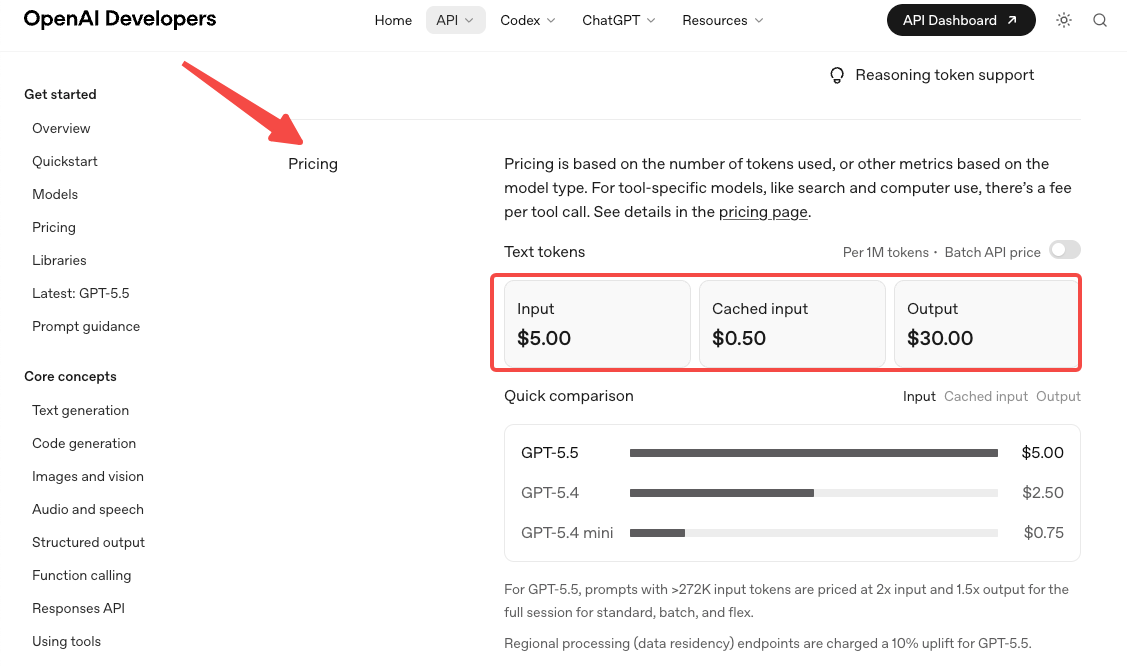
- Die Long-Context-Preisgestaltung ändert sich bei 272K. Oberhalb dieser Schwelle ist der Input 2x und der Output 1,5x für die gesamte Session. Wenn der Workflow regelmäßig 272K Token überschreitet, die Kosten zweimal modellieren — einmal unterhalb der Schwelle, einmal darüber. Das erfasst Teams, die auf der Tier-Struktur von GPT-5.4 aufgebaut haben und davon ausgingen, dass das neue Modell diese übernimmt.
- Security muss die System Card lesen. GPT-5.5 wird mit strengeren Cyber-Klassifikatoren ausgeliefert, dokumentiert in der GPT-5.5-System-Card. Einige legitime Workloads werden zunächst blockiert, während OpenAI die Abstimmung vornimmt. Es lohnt sich, dies an alle weiterzugeben, die Security-Tooling, Code-Analyse-Pipelines oder Red-Team-Workflows über die API betreiben.
Was vor dem Produktionseinsatz noch verifiziert werden muss
Modell-IDs, Rate-Limits, Preise und Tool-Unterstützung
Ich würde in dieser Reihenfolge verifizieren:
1.Modell-IDs und Snapshots. Auf einen Snapshot festlegen, nicht auf den Alias. Aliase ändern sich; Snapshots nicht. Die verfügbare Liste auf der GPT-5.5-Modellseite prüfen, bevor etwas im Client fest kodiert wird.
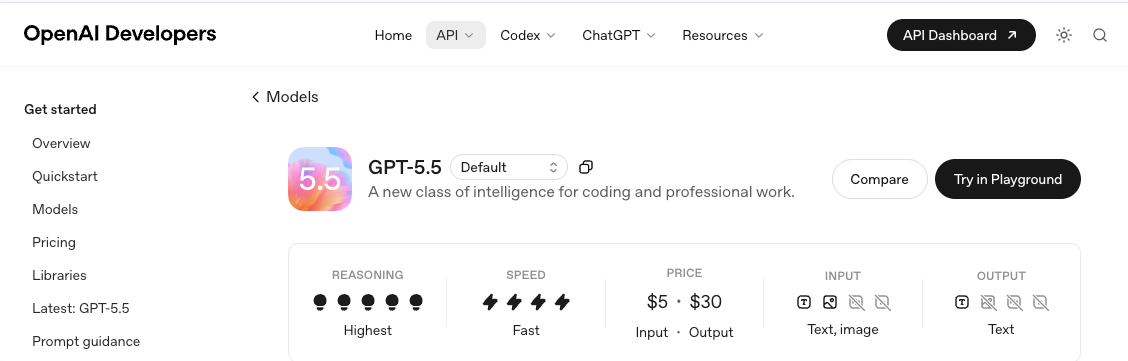
2.Die Rate-Limits des eigenen Tiers. OpenAIs Tier-System befördert automatisch basierend auf Ausgaben, aber Launch-Day-Limits können enger sein als das, was GPT-5.4 heute genießt. Die OpenAI-Rate-Limits-Dokumentation wäre mein Ausgangspunkt, und es lohnt sich, einen synthetischen Burst-Test gegen den aktuellen Tier durchzuführen, bevor davon ausgegangen wird, dass der Spielraum vorhanden ist.
3.Tool- und Structured-Output-Verhalten. Function Calling, Websuche und strukturierte Outputs funktionieren alle, aber die genauen Schemas und Reasoning-Mode-Interaktionen benötigen einen Smoke-Test gegen die eigentlichen Tool-Definitionen. Ich habe erlebt, dass Reasoning-Effort-Einstellungen das Wiederholungsverhalten auf eine Weise verändern, die erst sichtbar wird, wenn echter Produktions-Traffic auftritt.
Durchsatz und Details zum Enterprise-Rollout
Für alle, die ernsthaftes Volumen betreiben: Batch und Flex laufen zum halben Standardpreis, Priority zum 2,5-fachen. Übersetzt: Wenn die Arbeit asynchrone Verarbeitung toleriert, kostet Batch auf GPT-5.5 pro Token dasselbe wie GPT-5.4 auf Standard. Das ist die echte Arbitrage, die in diesem Release verborgen ist, und fast niemand, mit dem ich gesprochen habe, hat das einkalkuliert. Der GPT-5.5-Preisüberblick auf apidog geht die durchgerechneten Beispiele besser durch, als ich es hier tun würde.
Direkte Provider-Planung vs. plattformbasierte Bereitschaft
Ich arbeite bei einer Plattform, die den Modellzugang aggregiert, also liegt meine Neigung offen auf dem Tisch. Aber das strukturelle Argument ist dasselbe, unabhängig davon, welche Plattform verwendet wird: Wenn ein einzelner Provider am ersten Tag ein Modell zum doppelten Preis veröffentlicht, wird der Fall für Routing-Logik stärker, nicht schwächer.
Direkte Provider-Integration sieht so aus: Client neu schreiben, Prompts neu testen, Kostenmodell neu erstellen, pro Provider wiederholen. Multi-Modell-Plattformen — WaveSpeedAI eingeschlossen, aber auch andere — ermöglichen den Modellwechsel per Konfigurationsänderung. Der Kompromiss besteht darin, dass eine Schicht zwischen sich selbst und der Quelle eingefügt wird. Für Teams mit hoher Frequenz, die täglich deployen, ist diese Schicht die Abstraktion in der Regel wert. Für ein Team, das ein Modell auf einer Arbeitslast mit geringem Volumen betreibt, ist das nicht der Fall.
Ich würde in jedem Fall ein Routing-Setup planen. Premium-Anfragen an GPT-5.5, Routineverkehr an GPT-5.4 oder ein anderes Frontier-Modell — dieses Muster allein neigt dazu, die Rechnungen um 40–60 % gegenüber Single-Model-Defaults zu senken, unabhängig davon, auf welchen Provider man sich konzentriert.
FAQ
Ist GPT-5.5 bereits in der API gestartet?
Ja, seit dem 24. April 2026. Der Launch am 23. April umfasste nur ChatGPT und Codex; die API folgte einen Tag später. Sowohl gpt-5.5 als auch gpt-5.5-pro sind in den Responses- und Chat-Completions-Endpunkten mit einem 1M-Token-Kontextfenster zugänglich.
Was sollten Teams vor Beginn der Integrationsarbeit verifizieren?
Preisauswirkungen beim realen Token-Mix, Rate-Limit-Obergrenzen beim aktuellen Tier, Fallback auf GPT-5.4 eingebunden und getestet, sowie ein kurzer Eval-Rahmen, der beide Modelle auf der eigentlichen Arbeitslast vergleicht. Auf eine Snapshot-ID festlegen, nicht auf den Alias.
Lohnt es sich, zu warten, anstatt GPT-5.4 zu verwenden?
Hängt von der Arbeitslast ab. Für agentisches Coding und Computer-Use-Aufgaben zeigt GPT-5.5 bedeutende Verbesserungen, wie in der TechCrunch-Launch-Berichterstattung dokumentiert. Bei Workloads, bei denen GPT-5.4 bereits die Qualitätsanforderungen erfüllt, ist der verdoppelte Token-Preis ohne messbare Verbesserung schwer zu rechtfertigen.
Wie sollten sich Teams auf einen schnellen API-Rollout vorbereiten?
Den Eval-Rahmen jetzt aufbauen, über eine Abstraktionsschicht routen, falls nicht bereits vorhanden, und davon ausgehen, dass Rate-Limits sich verschärfen, bevor sie sich lockern. Keine großen Guthaben vorab aufladen — die Preisgestaltung dieser Generation ist noch in Bewegung.
Bedeutet der verdoppelte Preis tatsächlich verdoppelte Rechnungen?
Nein, aber nahe dran. Token-Effizienzgewinne bei Codex-Workloads bringen reale Rechnungen unter das 2-fache. Bei anderen Workloads ist eher mit dem Aufkleberpreis zu rechnen. Batch-Verarbeitung zum halben Preis ist der Hebel, den es zuerst zu ziehen gilt.
Fazit
Die API ist live. Die Preisgestaltung hat sich geändert. Die Rate-Limits sind noch nicht stabilisiert. Das alles bedeutet nicht, dass man sich beeilen sollte. Es bedeutet, dass das Planungsfenster, auf das die meisten Teams gehofft hatten, schneller geschlossen hat als erwartet, und die Arbeit jetzt in der Verifikation liegt und nicht im Warten.
Ich führe meine eigene Migration in den nächsten zwei Wochen durch. Ob GPT-5.5 danach in meinem Standard-Routing bleibt — das weiß ich noch nicht. Dafür ist das Eval da.
Mehr folgt.
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt

GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing

GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten

MAI-Image-2.5 API: Was Entwickler wissen sollten
