Claude Mythos Cybersicherheitsfähigkeiten: Was Entwickler- und Sicherheitsteams wissen müssen
Claude Mythos hat ernsthafte Cybersicherheitsbedenken aufgeworfen. Hier erfahren Sie, was die geleakten Behauptungen für Entwickler- und Sicherheitsteams bedeuten, die dieses Modell evaluieren.

„Sollten wir uns darüber Sorgen machen?” Die Nachricht vom Sicherheitsteam des Kunden landete in Slack, während ich interne KI-Tool-Optionen prüfte und die Anthropic-Leak-Story in meinem Feed auftauchte.
Auf WaveSpeedAI verfügbar — Pro-Token-Abrechnung, OpenAI-kompatibler Endpunkt. Claude Opus 4.7 API → · Playground öffnen →
Diese Frage tauchte in den nächsten 48 Stunden immer wieder auf. Nicht von KI-Enthusiasten, sondern von CISOs, Sicherheitsverantwortlichen und Entwicklern, die auf KI-Infrastruktur aufbauen und sich plötzlich in einem Gespräch wiederfanden, auf das sie nicht vorbereitet waren.
Die Mythos-Geschichte ist nicht nur eine KI-Produktankündigung. Sie ist ein Signal dafür, wohin sich die Bedrohungslandschaft entwickelt, und das Verstehen dessen, was tatsächlich bestätigt ist im Vergleich zu Spekulation, ist wichtiger als sonst, wenn ein neues Modell erscheint. In diesem Artikel werden wir gemeinsam der Antwort auf diese Frage auf den Grund gehen.
Was der durchgesickerte Entwurf über Mythos-Cybersecurity-Fähigkeiten enthüllte
Der durchgesickerte Entwurf eines Blogbeitrags — Teil von fast 3.000 exponierten internen Assets — enthielt zwei auffällige Behauptungen über Cybersicherheit, die weithin zitiert wurden. Anthropics eigene Worte, intern verfasst vor jeder öffentlichen Ankündigung, beschrieben das unveröffentlichte Modell (intern mit der „Capybara“-Stufe verknüpft und als Claude Mythos bezeichnet) als „derzeit weit vor jedem anderen KI-Modell in Cyber-Fähigkeiten”. Es warnte weiterhin, dass das Modell „eine bevorstehende Welle von Modellen ankündigt, die Schwachstellen auf eine Weise ausnutzen können, die die Bemühungen der Verteidiger bei weitem übertrifft.”
Eine zweite wichtige Passage zeigte ungewöhnliche Vorsicht: „Bei der Vorbereitung zur Veröffentlichung von Claude Mythos wollen wir mit besonderer Vorsicht vorgehen und die Risiken verstehen, die es birgt — sogar über das hinaus, was wir bei unseren eigenen Tests erfahren. Insbesondere wollen wir die kurzfristigen potenziellen Risiken des Modells im Bereich Cybersicherheit verstehen — und die Ergebnisse teilen, um Cyber-Verteidiger bei der Vorbereitung zu unterstützen.”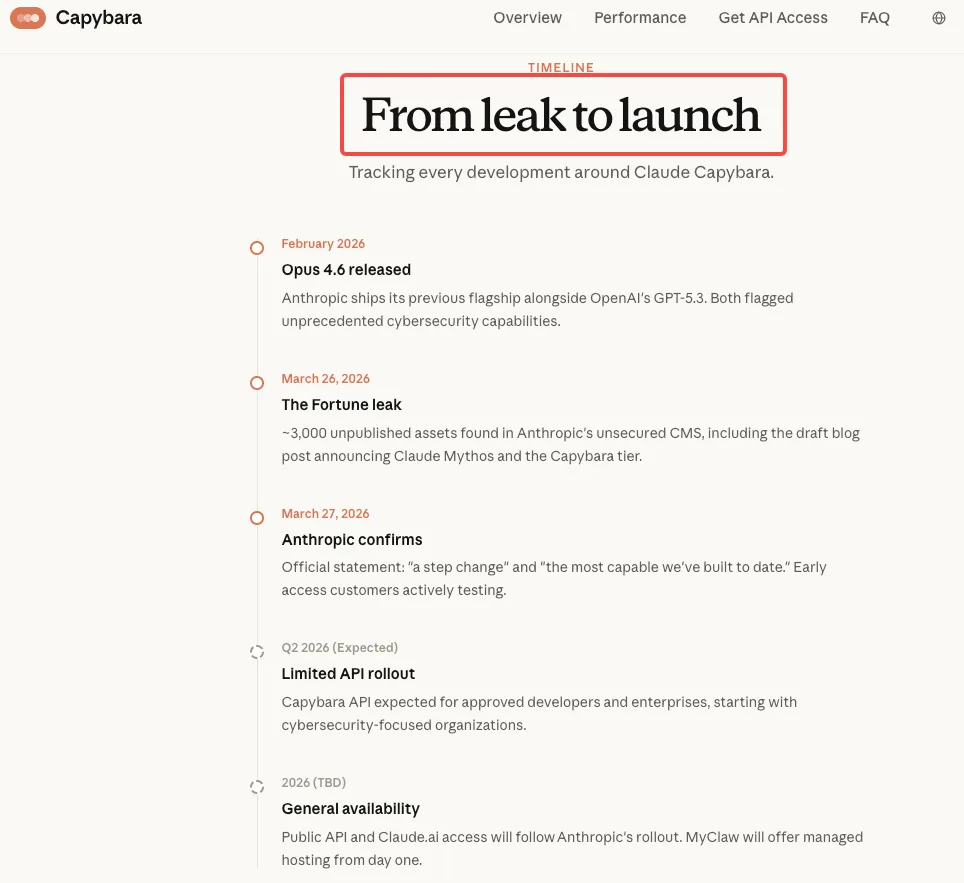
Diese Rahmung behandelt Cybersicherheitsrisiken nicht als handhabbare Einschränkung, sondern als erhebliche externe Wirkung, die eine proaktive Weitergabe an Verteidiger erfordert. Das ist eine merklich andere Haltung als bei Anthropics bisherigen Veröffentlichungen.
Was fehlt im Leak? Spezifische Benchmark-Zahlen, Exploit-Kategorien oder detaillierte Methodik. Behauptungen über „deutlich höhere Punktzahlen bei Tests der Cybersicherheit” stellen das vollständige Ausmaß der offengelegten Fähigkeiten dar. Alles Spezifischere, das online kursiert, ist Extrapolation.
Warum Anthropic dies als beispielloses Risiko behandelt
Was „Weit vor jedem anderen KI-Modell in Cyber-Fähigkeiten” tatsächlich bedeutet
Diese Behauptung trifft anders, wenn man versteht, wozu Opus 4.6 — die aktuelle Baseline — bereits fähig ist. Mythos übertrifft damit keine niedrige Messlatte.
Mithilfe von Claude Opus 4.6 fand und validierte Anthropics Frontier Red Team mehr als 500 hochgradige Schwachstellen in produktiven Open-Source-Codebasen — Fehler, die jahrzehntelang unentdeckt geblieben waren, trotz jahrelanger Expertenbegutachtung. Das Team verwendete keine spezialisierten Anweisungen oder einen benutzerdefinierten Rahmen und verließ sich ausschließlich auf die Out-of-the-box-Fähigkeiten des Modells.
Ein bemerkenswerter Fall: Opus 4.6 identifizierte eine blinde SQL-Injection in Ghost CMS (eine Plattform mit 50.000+ GitHub-Stars und einer zuvor makellosen Sicherheitsbilanz) in etwa 90 Minuten.
Der strukturelle Unterschied zwischen KI-gestützter Schwachstellenerkennung und traditionellem Fuzzing ist hier wichtiger Kontext. Fuzzer speisen Eingaben in Code ein, bis etwas abbricht. Claude denkt über Code nach: verfolgt Logik über Komponenten hinweg, liest Commit-Historien, um ungepatchte Varianten behobener Fehler zu finden, und bewertet, welche Code-Pfade inhärent riskant sind, anstatt jede mögliche Eingabe zu untersuchen. Mythos, laut Anthropics eigener interner Bewertung, macht dies besser als alles andere, was derzeit verfügbar ist — mit erheblichem Abstand.
Das Verteidiger-Lücken-Problem: Warum Angriff die Verteidigung überholen könnte
Die wichtigste Erkenntnis des Entwurfs war nicht die Katalogisierung neuer Angriffstypen. Es war die Erklärung, warum die Angreifer-Verteidiger-Asymmetrie überhaupt existiert. Angreifer müssen eine Schwäche finden. Verteidiger müssen alles abdecken. Ein KI-Modell, das über Code nachdenken, potenzielle Schwachstellenmuster identifizieren und bei der Exploit-Verfeinerung helfen kann, verkürzt die Zeit von der „Idee” zum „funktionierenden Angriff”.
Anthropic soll leitende Regierungsbeamte gewarnt haben, dass Mythos großangelegte Cyberangriffe im Jahr 2026 wahrscheinlicher machen könnte, indem es hochsophistizierte autonome Agenten ermöglicht. Eine Dark-Reading-Umfrage aus Anfang 2026 ergab, dass 48 % der Cybersicherheitsfachleute agentische KI nun als den wichtigsten Angriffsvektor des Jahres einordnen — noch vor Deepfakes und Social Engineering.
Das ist kein Problem, das Mythos von Grund auf schafft; es ist ein Beschleuniger. Gegner nutzen KI bereits ohne Zögern oder Compliance-Reibung. Verteidiger, die sich den Zugang zu frontier-Modellen selbst einschränken, riskieren, entscheidendes Terrain aufzugeben.
Defensive vs. offensive Anwendungen: Wo die Grenze liegt
Legitime Anwendungsfälle: Schwachstellen-Scanning, Red Teaming, Code-Härtung
Die defensiven Anwendungen von Mythos’ Fähigkeiten sind tatsächlich bedeutsam — und sie sind der Hauptgrund, warum Anthropic dies überhaupt entwickelt und veröffentlicht.
**Claude Code Security**, eine neue Fähigkeit, die in Claude Code eingebaut ist, scannt Codebasen auf Sicherheitsschwachstellen und schlägt gezielte Software-Patches zur menschlichen Überprüfung vor, was Teams ermöglicht, Sicherheitsprobleme zu finden und zu beheben, die traditionelle Methoden oft übersehen. Nichts wird ohne menschliche Genehmigung angewendet: Claude Code Security identifiziert Probleme und schlägt Lösungen vor, aber Entwickler treffen immer die Entscheidung.
Mythos-Tier-Fähigkeiten, auf diesen Workflow angewendet, würden bedeuten, Schwachstellenklassen zu finden, die selbst Opus 4.6 übersieht — kontextabhängige Fehler in der Geschäftslogik, Multi-Komponenten-Interaktionsmuster, Authentifizierungs-Bypässe, die das Verständnis der Systemarchitektur statt Code-Muster erfordern. Für Sicherheitsteams, die derzeit vierteljährlich für manuelle Penetrationstests bezahlen, stellt KI-gesteuertes kontinuierliches Scanning auf Mythos-Niveau eine bedeutende Verschiebung in dem dar, was operativ erreichbar ist.
Für Red Teams erfordert dieselbe Kraft strikte Umgrenzung und Autorisierung. Das Modell selbst unterscheidet nicht zwischen autorisiertem Testen und böswilliger Nutzung — diese Verantwortung bleibt bei Ihren Prozessen und Leitplanken.
Was Anthropic tut, um Missbrauch einzuschränken
Parallel zu Opus 4.6 setzte Anthropic Aktivierungs-Level-Proben ein, um Cyber-Missbrauch in Echtzeit zu erkennen und zu blockieren, und erkannte dabei potenzielle Reibung für legitime Sicherheitsforschung an. „Dies wird Reibung für legitime Forschung und einige defensive Arbeit erzeugen, und wir möchten mit der Sicherheitsforschungsgemeinschaft zusammenarbeiten, um Wege zu finden, dies bei Entstehung anzugehen”, warnte das Unternehmen.
Für Mythos speziell sind die Kontrollen strukturell und nicht nur technischer Natur. Basierend auf den durchgesickerten Dokumenten und Anthropics öffentlichen Aussagen ist der anfängliche Zugang auf geprüfte Sicherheitsforscher und Verteidiger beschränkt — das Ziel ist, defensive Tools zu entwickeln, bevor offensive Fähigkeiten breit verfügbar werden. Dies spiegelt Anthropics Umgang mit früheren risikoreichen Veröffentlichungen wider und stimmt mit den vom NIST AI Risk Management Framework empfohlenen Praktiken überein, die eine schrittweise Einführung mit laufender Überwachung für Dual-Use-KI-Systeme befürworten.
Der Abschnitt über adversarielle KI-Taktiken im MITRE ATT&CK Framework ist es wert, für jedes Sicherheitsteam, das versucht, die Bedrohungsoberfläche hier zu modellieren, überprüft zu werden. Die dort dokumentierten Taktiken gehen von deutlich weniger fähigen Modellen aus als das, was Mythos darstellt.
Was Early-Access-Sicherheitskunden bewerten
Der durchgesickerte Entwurf war explizit bezüglich Anthropics Rollout-Priorität: „Wir werden den Zugang zu Claude Mythos in den kommenden Wochen langsam auf mehr Kunden ausweiten, die die Claude API nutzen. Da wir besonders an Cybersicherheits-Anwendungsfällen interessiert sind, ist das der Bereich, in dem wir das EAP zunächst ausweiten möchten.”
Die Early-Access-Kohorte bewertet Mythos anhand des spezifischen Problems, das das Modell lösen soll: Schwachstellen in gehärteten Produktions-Codebasen schneller und umfassender zu finden als bestehende Tools. Analysten weisen darauf hin, dass es die Offense-Defense-Lücke in beide Richtungen verkleinern könnte — schnellere Schwachstellenerkennung, kontinuierliches Red-Teaming und Bedrohungsjagd ermöglichend, während es auch die Messlatte für sophistizierte Angriffe senkt, wenn es missbraucht wird.
Für Sicherheitskunden, die sich derzeit im Evaluierungszeitraum befinden, drehen sich die praktischen Fragen um drei Bereiche: wie Mythos in bestehende SIEM- und Schwachstellenmanagement-Workflows integriert wird, ob die Erkenntnisse des Modells in Formaten präsentiert werden können, die mit bestehenden Ticketing-Systemen kompatibel sind, und wie die Anforderungen an die menschliche Überprüfung im großen Maßstab aussehen.
In Gesprächen mit mehr als 40 CISOs aus verschiedenen Branchen stellte VentureBeat fest, dass formale Governance-Frameworks für reasoning-basierte Scanning-Tools die Ausnahme und nicht die Norm sind. Die häufigsten Antworten waren, dass der Bereich als so neu angesehen wurde, dass viele CISOs nicht dachten, dass diese Fähigkeit so früh im Jahr 2026 ankommen würde. Die Teams innerhalb des Early-Access-Programms schreiben gewissermaßen das Governance-Handbuch, dem der Rest der Industrie folgen wird.
Implikationen für Entwicklerteams, die auf KI-Infrastruktur aufbauen
Wenn Ihr Team Produkte auf Claude oder einem anderen frontier-KI-Modell aufbaut, schafft die Mythos-Situation zwei unterschiedliche Kategorien von Bedenken.
Die erste ist direkt: Sie sind ein potenzielles Ziel für KI-gestützte Angriffe, und diese Angriffe werden leistungsfähiger.
Das zweite Bedenken ist architektonischer Natur: wie Ihre KI-Infrastruktur gegen Prompt Injection, unbefugten Tool-Zugriff und Agent-Missbrauch gesichert ist. Organisationen müssen jeden Agenten, Bot und KI-Dienst als Identität behandeln und dieselben Kontrollen, Berechtigungen und Überwachung auf nicht-menschliche Identitäten anwenden wie auf menschliche Benutzer — was eine Inventarisierung des Zugriffs erfordert und hartcodierte Anmeldeinformationen eliminiert, die unsichere Bots schaffen.
Praktisch bedeutet dies mehrere Dinge für Teams, die heute auf Claude aufbauen:
Schränken Sie den MCP-Server-Zugriff streng ein. Jeder MCP-Server, den Sie mit einem Claude-Agenten verbinden, ist eine potenzielle Angriffsfläche. Die erweiterten agentischen Fähigkeiten, die Claude Code leistungsfähig machen, machen schlecht eingegrenzte Agent-Berechtigungen auch zu einem bedeutenden Risikobereich.
Behandeln Sie CLAUDE.md als Sicherheitsdokument. Anweisungen in CLAUDE.md, die definieren, welche Tools ein Agent verwenden kann, welche Dateien er lesen darf und welche Operationen er ausführen kann, sind Sicherheitskontrollen, keine bloßen Produktivitätshilfen. Eine schlecht geschriebene CLAUDE.md, die umfassenden Dateizugriff oder Tool-Berechtigungen gewährt, verstärkt das Risiko.
Wenden Sie menschliche Überprüfung auf KI-generierte Patches an, nicht nur auf KI-generierten Code. KI-generierter Code ist 2,74-mal häufiger anfällig für XSS-Schwachstellen und 1,91-mal häufiger anfällig für unsichere Objektreferenzen im Vergleich zu menschlich geschriebenem Code. Dieselbe Reasoning-Fähigkeit, die Schwachstellen findet, kann sie auch einführen. Menschliche Überprüfung sicherheitsrelevanter Änderungen ist keine Option.
FAQ
Können Sicherheitsteams jetzt auf Claude Mythos zugreifen?
Nicht über einen öffentlichen Kanal. Der Rollout-Plan des Modells spiegelt die Cybersicherheitsbedenken wider: Der Early Access ist auf geprüfte defensive Cybersicherheitsorganisationen beschränkt. Für Sicherheitsteams, die sich vorbereiten möchten, ist Claude Code Security — basierend auf Opus 4.6, jetzt in begrenzter Research Preview für Enterprise- und Team-Kunden verfügbar — das am nächsten öffentlich zugängliche Tool und eine nützliche Baseline für das Verständnis dessen, was Mythos-Tier-Fähigkeiten erweitern würden.
Welche Schutzmaßnahmen entwickelt Anthropic?
Bestätigte Maßnahmen umfassen Echtzeit-Missbrauchserkennungs-Proben, schrittweisen Rollout mit Priorisierung von Verteidigern und Human-in-the-Loop-Anforderungen für Patches. Für Mythos liegt der Schwerpunkt auf Deployment-Governance, Tool-Grenzen und Audit-Trails.
Wird Claude Mythos für kommerzielles Red Teaming verfügbar sein?
Nicht bestätigt. Die Early-Access-Kohorte konzentriert sich auf defensive Sicherheits-Anwendungsfälle. Kommerzielles Red Teaming — bei dem Organisationen Sicherheitsfirmen beauftragen, ihre Systeme aktiv zu testen — befindet sich in einer mehrdeutigen Zone: Es ist autorisierter Angriff. Angesichts der erklärten Bedenken des Unternehmens über offensive Missnutzung sind bedeutende Zugriffskontrollen statt offenem API-Zugriff für Red-Teaming-Anwendungsfälle zu erwarten.
Vorherige Beiträge:
- Claude Mythos vs Claude Opus 4.6: Was der Leak für Entwickler enthüllt
- Claude Mythos (Opus 5) geleakt: Was wir bisher wissen
- Was ist Claude Mythos? Leak, Capybara-Tier & Was Anthropic bestätigt hat
- Claude Sonnet 4.6: Ein „Non-Hogging the Spotlight”-Arbeitsmodell
- Claude Opus 4.6 und Sonnet 4.6: Alles, was Sie wissen müssen
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten