Claude Code Agent Harness: Architektur im Detail
Wie Claude Code Tools verdrahtet, Berechtigungen verwaltet und Agent-Sitzungen orchestriert — eine technische Aufschlüsselung für Entwickler.

Beim Aufbau meines eigenen Tool-Calling-Systems bin ich immer wieder auf dieselbe Frage gestoßen: Warum fühlt sich die Verdrahtung so viel schwieriger an als das Prompting?
Der Modellteil klickte schnell. Aber in dem Moment, in dem ich brauchte, dass es Dinge tut — Dateien lesen, Shell-Befehle ausführen, mit externen Diensten kommunizieren — fühlte sich jede Entscheidung so an, als könnte sie etwas kaputt machen. Berechtigungsgrenzen. Kontextlimits. Tool-Dispatch.
Dann, Ende März 2026, wurde Claude Codes Quellcode versehentlich über eine npm-Source-Map in Version 2.1.88 offengelegt. Über 500.000 Zeilen TypeScript, innerhalb von Stunden gespiegelt. Anthropic bestätigte, dass es sich um einen Packaging-Fehler handelte — keine Kundendaten betroffen — und begann, DMCA-Takedowns einzuleiten.
Aber die Architektur wurde öffentliches Wissen. Und was sie enthüllte, war nicht das Modell. Es war das Harness.
Ein Hinweis zu den Quellen: Die Details hier stammen aus Community-Analysen, Open-Source-Reproduktionen sowie Anthropics öffentlicher Dokumentation und Engineering-Blog — nicht aus dem geleakten Code selbst. Unsichere Details sind gekennzeichnet.
Was ist ein Agent Harness?
Definition und Rolle in agentischen Systemen
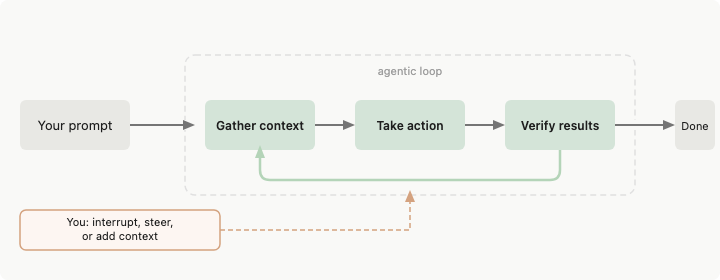
Ein Agent Harness ist alles zwischen dem Sprachmodell und der realen Welt. Das Modell generiert Text. Das Harness entscheidet, was dieser Text berühren kann.
Anthropics Dokumentation für Claude Code beschreibt es direkt: Claude Code „stellt die Tools, das Kontextmanagement und die Ausführungsumgebung bereit, die ein Sprachmodell in einen fähigen Coding-Agenten verwandeln.” Das Modell denkt nach. Das Harness handelt.
Wenn Ihr Agent eine Datei liest, entscheidet das Harness, ob das Lesen erlaubt ist, was mit dem Ergebnis passiert und wie viel der Antwort in den nächsten Prompt passt. Das Modell berührt das Dateisystem niemals direkt.
Warum Harness-Design für die Produktion wichtig ist
Die meisten Agent-Demos überspringen diesen Teil. Man sieht ein Modell, das eine Funktion aufruft, ein Ergebnis erhält, eine weitere aufruft. Es sieht sauber aus. Dann läuft man es 45 Minuten lang auf einer echten Codebasis, und Dinge gehen still kaputt — Kontext-Overflows, Berechtigungen zu locker oder zu lästig, Tool-Ergebnisse abgeschnitten ohne dass das Modell es weiß.
Anthropics Engineering-Team hat darüber geschrieben: Selbst ein Frontier-Modell, das in einer Schleife über mehrere Kontextfenster läuft, wird ohne ein gut gestaltetes Harness schlechter abschneiden. Der Agent versucht zu viel auf einmal zu tun oder erklärt den Job vorzeitig für erledigt. Das Harness legt dieser Tendenz Struktur auf.

Claude Codes Tool-Oberfläche
Kern-Tool-Kategorien
Basierend auf der offiziellen Claude Code Dokumentation und öffentlichen Analysen stellt Claude Code ungefähr 19 berechtigungsgesteuerte Tools bereit. Die Hauptkategorien: Datei-Lesen und -Bearbeiten, Shell-Ausführung (Bash), Git-Operationen, Web-Fetching, Notebook-Bearbeitung und MCP-Tool-Aufrufe. Community-Analysen legen nahe, dass die Zahl näher an 40 liegt, wenn man LSP-Integration, Subagenten-Spawning und interne Koordinations-Tools einbezieht.
Jedes Tool ist unabhängig sandboxed. Es ist nicht „der Agent hat Dateisystemzugriff” — es ist „der Agent kann das Read-Tool verwenden, und Read hat sein eigenes Berechtigungs-Gate, das eine Regel-Pipeline prüft, bevor irgendetwas ausgeführt wird.”
Wie Tools registriert und dispatched werden
Das Modell entscheidet, was es versuchen möchte. Das Tool-System entscheidet, was erlaubt ist. Architektonisch getrennt.
Jeder Tool-Aufruf durchläuft eine Berechtigungsprüfung vor der Ausführung. Community-Deep-Dives beschreiben eine Kernfunktion, die Deny/Ask/Allow-Regeln in dieser Reihenfolge auswertet — Deny gewinnt immer. Drei mögliche Ergebnisse: still fortfahren, den Benutzer fragen oder blockieren.
Ein kompromittiertes Modell kann Sicherheitsprüfungen nicht durch Überzeugungskraft umgehen. Das Harness kümmert sich nicht um das Argument des Modells. Regeln sind Regeln.
Berechtigungsstufen
Claude Codes Berechtigungsmodell wurde von mehreren Community-Analysten als ungefähr drei Stufen beschrieben:
Stufe 1 — Auto-genehmigt: Nur-Lese- oder von Natur aus sichere Aktionen. Datei-Lesen, Textsuche, Code-Navigation. Diese ändern keinen Zustand, daher werden sie ohne Unterbrechung ausgeführt.
Stufe 2 — Bestätigung anfordern: Aktionen, die den Zustand auf kontrollierte Weise ändern. Dateibearbeitungen, bestimmte Shell-Befehle. Im Auto-Modus (eingeführt März 2026) bewertet ein im Hintergrund laufender Klassifizierer auf Sonnet 4.6, ob diese ohne Nachfragen fortgesetzt werden können. Der Klassifizierer sieht die Anfrage des Benutzers und den Tool-Aufruf, aber nicht den Fließtext des Modells — eine bewusste Design-Entscheidung, um zu verhindern, dass das Modell sich am Gate vorbeiredet.
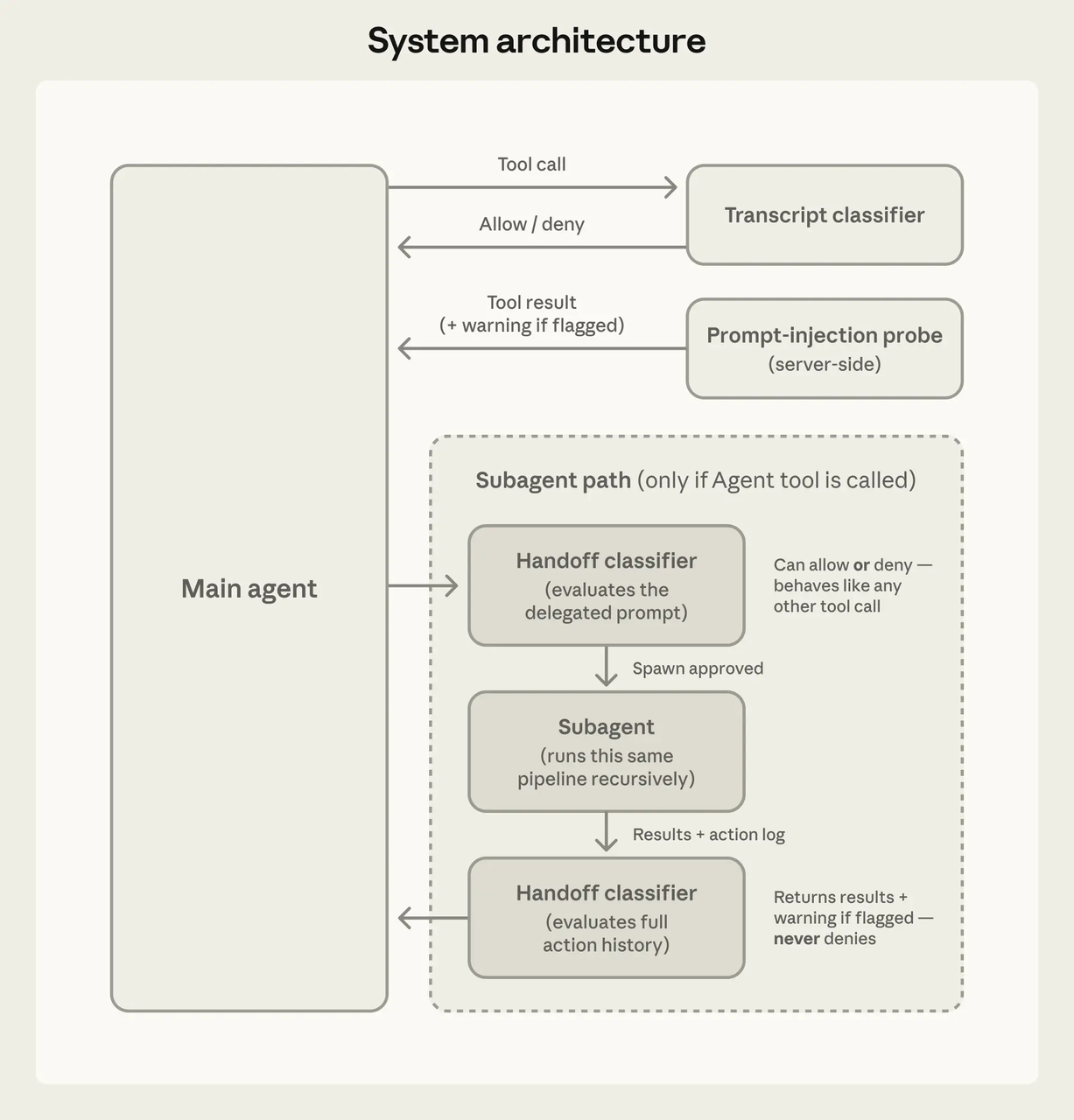 Stufe 3 — Explizite Genehmigung erforderlich oder Blockierung: Hochrisiko-Operationen. Shell-Befehle, die den Systemzustand unvorhersehbar ändern könnten, Operationen außerhalb des Arbeitsverzeichnisses, alles, was wie Daten-Exfiltration aussieht.
Stufe 3 — Explizite Genehmigung erforderlich oder Blockierung: Hochrisiko-Operationen. Shell-Befehle, die den Systemzustand unvorhersehbar ändern könnten, Operationen außerhalb des Arbeitsverzeichnisses, alles, was wie Daten-Exfiltration aussieht.
Ein Vorbehalt: Das Drei-Stufen-Framing stammt aus der Community-Analyse, nicht aus Anthropics offiziellen Docs. Das offizielle System verwendet Allow/Ask/Deny-Regeln und sechs Berechtigungsmodi (default, acceptEdits, plan, auto, dontAsk, bypassPermissions). Die „drei Stufen” sind ein nützliches mentales Modell, aber eine Vereinfachung.
Sitzungs- und Kontext-Management
Wie Claude Code den Sitzungsstatus verfolgt
Claude Code akkumuliert Kontext über eine Sitzung — gelesene Dateien, ausgeführte Befehle, Grep-Ergebnisse, Diffs, Fehlerausgaben. Alles stapelt sich in einen wachsenden Prompt. Anders als bei einer Chat-Schnittstelle, bei der jede Nachricht einigermaßen unabhängig ist, ist eine Claude Code-Sitzung ein kontinuierliches Arbeitsgedächtnis.
Sitzungen werden lokal gespeichert. Jede Nachricht, jede Tool-Nutzung und jedes Ergebnis werden gespeichert, was Zurückspulen, Fortsetzen und Verzweigen ermöglicht. Vor Codeänderungen erstellt das Harness Snapshots der betroffenen Dateien, damit man sie rückgängig machen kann.
Ausgabe-Trunkierung und Token-Kostenbehandlung
Große Tool-Ausgaben sind ein echtes Problem. Claude Code setzt ein Standard-Maximum von 25.000 Tokens für MCP-Tool-Ausgaben, mit einer Warnung bei 10.000 Tokens. Server-Autoren können Tools annotieren, um größere Ergebnisse zu erlauben (bis zu 500.000 Zeichen), die auf der Festplatte gespeichert werden, anstatt im Kontext zu bleiben.
Das ist die Art von Sache, über die man nicht nachdenkt, bis der Agent stillschweigend den Überblick über Informationen verliert, weil ein Tool-Ergebnis abgeschnitten wurde. Explizite, konfigurierbare Limits mit festplattenbasierten Fallbacks — es lohnt sich, das zu übernehmen.
Kompaktierungsverhalten
Das hat mich erwischt, bevor ich es verstand. Wenn die Token-Nutzung etwa 98 % des Kontextfensters erreicht, kompaktiert Claude Code automatisch: Es fasst frühere Geschichte zusammen, um Platz freizugeben. Kritische Metadaten werden beibehalten. Bilder und PDFs werden entfernt.
Der knifflige Teil: Die Kompaktierung kann wichtige Details verlieren. Die praktische Lösung: Alles Kritische in CLAUDE.md ablegen, das das Harness bei jedem Turn erneut liest.
Anthropics Forschung zum Harness-Design hat festgestellt, dass vollständige Kontext-Resets — bei denen eine neue Agenten-Instanz von einem Übergabe-Artefakt aufgreift — manchmal besser funktionieren als Kompaktierung für ausgedehnte Sitzungen. Mehr Orchestrierungskomplexität, aber bessere Kontext-Treue.
MCP-Integrationsschicht
Wie Claude Code mit MCP-Servern verbindet
 MCP (Model Context Protocol) ist ein offener Standard zur Verbindung von KI-Tools mit externen Diensten. Claude Code unterstützt drei Transport-Modi: HTTP (empfohlen für Remote-Server), stdio (für lokale Prozesse) und SSE.
MCP (Model Context Protocol) ist ein offener Standard zur Verbindung von KI-Tools mit externen Diensten. Claude Code unterstützt drei Transport-Modi: HTTP (empfohlen für Remote-Server), stdio (für lokale Prozesse) und SSE.
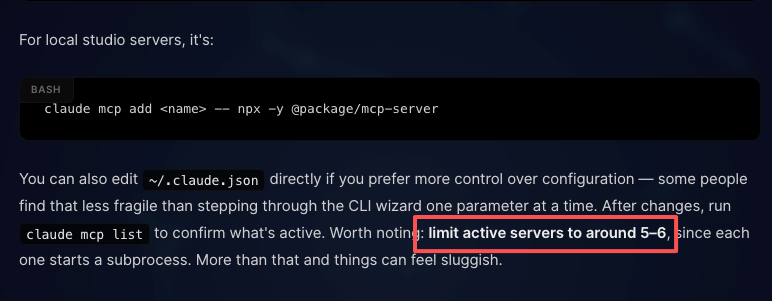
Das Hinzufügen eines Servers ist ein Befehl: claude mcp add server-name --transport http "URL". Danach erscheinen die Tools des Servers als aufrufbare Tools in der Sitzung, unterliegen aber derselben Berechtigungs-Pipeline wie eingebaute Tools.
Tool-Discovery und Auth-Flows
Ein Detail, das mich beeindruckt hat: Tool-Suche. Wenn man MCP-Server verbindet, lädt Claude Code nicht alle ihre Tool-Schemas im Voraus in den Kontext. Es lädt nur Tool-Namen beim Sitzungsstart, verwendet dann einen Suchmechanismus, um relevante Tools zu entdecken, wenn eine Aufgabe sie tatsächlich benötigt. Nur die Tools, die Claude verwendet, gelangen in den Kontext.
Das hält den MCP-Overhead gering. Auth-Flows hängen vom Server ab — OAuth, API-Schlüssel, Header. Claude Code erfordert explizite Benutzergenehmigung für neue MCP-Server.
Was produktionsreif ist vs. noch in der Entwicklung
MCP-Integration ist funktional und wird aktiv genutzt. Aber ein paar praktische Grenzen sind erwähnenswert:
Das empfohlene Limit liegt bei etwa 5–6 aktiven MCP-Servern, da jeder einen Subprozess startet. Tool-Suche hilft beim Kontext-Overhead, aber die Latenz schleicht sich jenseits davon ein.
 Große MCP-Antworten erfordern sorgfältige Behandlung. Das Standard-Limit von 25K Tokens funktioniert für die meisten Anwendungsfälle, wird aber bei Datenbank-Schemas eng. Der Persist-to-Disk-Fallback hilft, obwohl das Modell nur eine Referenz anstatt des vollständigen Ergebnisses im Kontext erhält.
Große MCP-Antworten erfordern sorgfältige Behandlung. Das Standard-Limit von 25K Tokens funktioniert für die meisten Anwendungsfälle, wird aber bei Datenbank-Schemas eng. Der Persist-to-Disk-Fallback hilft, obwohl das Modell nur eine Referenz anstatt des vollständigen Ergebnisses im Kontext erhält.
Und Community-gebaut MCP-Server variieren in der Qualität. Anthropics Docs weisen ausdrücklich darauf hin, dass Drittanbieter-Server Prompt-Injection-Vektoren sein können. Das Berechtigungssystem hilft, aber das Vertrauen liegt immer noch bei Ihnen.
Lektionen für Builder
Was diese Architektur über produktionsreife agentische Systeme enthüllt
Ein paar Muster aus Claude Codes Design, von denen ich denke, dass sie sich verallgemeinern lassen:
Trennen Sie Reasoning von der Berechtigungsdurchsetzung. Das Modell entscheidet, was es tun möchte. Ein anderes System entscheidet, ob es erlaubt ist. Ein gejailbreaktes Modell kann Sicherheitsprüfungen nicht umgehen, weil es buchstäblich ein anderer Code-Pfad ist.
Machen Sie Kontext-Management explizit. Kompaktierung, Trunkierungslimits, Tool-Suche, Disk-Persistenz — das sind alles Mechanismen zur aktiven Verwaltung dessen, was das Modell sieht. Die meisten Hobby-Agent-Builds behandeln Kontext als einen bodenlosen Sack. Das ist er nicht.
Designen Sie für Sitzungskontinuität. Snapshots, rückgängig machbare Dateiänderungen, CLAUDE.md als persistenter Anker. Langläufige Agenten brauchen Gedächtnis, das Kontext-Komprimierung überlebt.
Berechtigungsgranularität zahlt sich aus. Pro-Tool-, Pro-Muster-, Pro-Verzeichnis-Regeln mit Deny-First-Auswertung. Mehr Arbeit als ein pauschales „alles erlauben”-Flag, aber es ist der Unterschied zwischen einer Demo und einem deployablen System.
Wann man sein eigenes Harness baut vs. eine verwaltete Schicht nutzt
Enge, klar definierte Aufgabe — ein CI-Bot, der Tests ausführt und Ergebnisse postet — man kann ein minimales Harness selbst verdrahten. Ein paar Tools, eine einfache Berechtigungsprüfung, ein festes Kontextfenster.
Ausgedehnte Sitzungen, Zustand über Kontext-Resets hinaus, nicht vertrauenswürdige Tool-Ausgaben, Dutzende von Tools — bauen Sie auf einem bestehenden Harness auf oder studieren Sie eines genau. Das Claude Agent SDK, OpenAIs Codex-Architektur, LangGraph haben alle Probleme gelöst, auf die man irgendwann stoßen wird.
Die meisten Teams unterschätzen die Harness-Komplexität. Das habe ich sicherlich getan. Das Modell ist der einfache Teil.
FAQ
Was ist Claude Codes Agent Harness?
Die Infrastrukturschicht zwischen dem Claude-Modell und der realen Welt — Tool-Dispatch, Berechtigungen, Kontext-Management, Sitzungszustand, MCP-Verbindungen. Anthropic beschreibt es als das, was „ein Sprachmodell in einen fähigen Coding-Agenten verwandelt.”
Wie behandelt Claude Code Tool-Berechtigungen?
Eine regelbasierte Pipeline bewertet jeden Tool-Aufruf: allow, ask oder deny, wobei deny immer gewinnt. Im Auto-Modus bewertet ein Hintergrundklassifizierer auf einer separaten Modellinstanz mehrdeutige Fälle — und sieht bewusst nicht die Fließtext-Ausgabe des Agenten, um Prompt-Injection zu verhindern.
Ist Claude Codes MCP-Integration produktionsreif?
Funktional und aktiv genutzt, aber mit praktischen Limits rund um Server-Anzahl, Antwortgröße und Drittanbieter-Vertrauen. Es entwickelt sich schnell weiter.
Kann ich mein eigenes Harness mit denselben Mustern bauen?
Ja. Das Claude Agent SDK stellt dieselben Berechtigungsmodi, Hooks und das Kontext-Management bereit. Community-Projekte wie Everything Claude Code haben wiederverwendbare Muster dokumentiert.
Was ist der Unterschied zwischen Spec-Parität und Verhaltens-Parität?
Spec-Parität bedeutet, dieselben Tools und Konfigurationen zu unterstützen. Verhaltens-Parität bedeutet, Edge-Cases auf dieselbe Weise zu behandeln — Kompaktierung lässt eine kritische Regel fallen, ein Tool gibt 100K Tokens zurück, ein Modell versucht Berechtigungen zu umgehen. Die Spec zu erfüllen ist unkompliziert. Das Verhalten zu erfüllen dauert Monate.
Etwas, das mir geblieben ist: das Harness ist der schwierige Teil. Jeder geht davon aus, dass das Modell der Wettbewerbsvorteil ist. Und das ist es — bis man versucht, es zuverlässig Dinge tun zu lassen, länger als fünf Minuten. Dort lebt die Ingenieurskunst.
Vorherige Beiträge:
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt

GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing

GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten

MAI-Image-2.5 API: Was Entwickler wissen sollten
