GPT-5 Modellversionen erklärt: Von GPT-5 bis GPT-5.4
GPT-5 ist kein einzelnes Modell. Dieser Leitfaden erklärt jede GPT-5.x-Version und was Entwickler über die sich weiterentwickelnde Modellfamilie wissen sollten.

Hallo, ich bin Dora. Ich hatte nicht geplant, diese Woche über GPT-5-Modelle zu schreiben. Ich blieb einfach wieder beim Auswählen einer Version im Modell-Dropdown hängen. Eine kurze Pause, dann die vertraute Frage: Hilft 5.2 hier wirklich, oder klicke ich auf die neuere Version, weil sie neuer ist?
Auf WaveSpeedAI verfügbar — Pro-Token-Abrechnung, OpenAI-kompatibler Endpunkt. GPT-5.5 API → · GPT-5.4 API → · Playground öffnen →
Diese kleine Reibung hat mich in ein Kaninchenloch geführt. Ich verbrachte ein paar Abende Ende Februar und Anfang März 2026 damit, dieselben Aufgaben in der 5.x-Familie erneut durchzuführen: eine kompakte Forschungszusammenfassung, eine strukturierte JSON-Extraktion und ein einfaches Multi-Datei-Code-Refactoring. Nichts Ausgefallenes. Nur die Art von Arbeit, die sich entweder einfacher anfühlt oder eben nicht. Dies sind meine Feldnotizen, kein Triumphmarsch.

Warum GPT-5 ein System ist und kein einzelnes Modell
Ich sehe immer wieder, wie Menschen über “das” GPT-5-Modell sprechen, als wäre es ein einzelnes Gehirn, das man einfach austauscht. Das hat nicht mit dem übereingestimmt, was ich beobachtet habe, oder mit dem, was OpenAI in ihren Dokumenten und öffentlichen Gesprächen andeutet.
Überblick über die Router-Architektur
Das Verhalten sieht aus wie ein geroutetes System: eine “Eingangstür”, die stillschweigend entscheidet, welcher interne Spezialist welchen Teil Ihrer Anfrage bearbeitet. Man kann es sich wie einen Verkehrsregler vorstellen, der einige Ziele im Kopf hat: Latenz stabil halten, einen Qualitätsschwellenwert treffen und teure Spezialisten nur dann einsetzen, wenn die Eingabe sie wirklich benötigt. Deshalb kann sich dasselbe Prompt zwischen “schnellen” und “Standard”-Einstellungen oder zwischen benachbarten Versionen etwas unterschiedlich anfühlen – es sind mehr als ein Modell im Spiel.
In der Praxis habe ich Signale dafür gesehen, wenn:
- Tool-Aufrufe bei bestimmten Durchläufen schneller aufgegriffen werden, als hätte ein Planer früher eingegriffen.
- Die Zuverlässigkeit des JSON-Modus nach einem systemseitigen Update steigt, auch wenn sich die API-Parameter nicht geändert haben.
- Die Latenz unter Last besser standhält, als es für ein einzelnes Monolith sein sollte.
Ich kann nicht hinter den Vorhang schauen, aber die Ausgaben deuten auf einen Router hin, der Kosten, Geschwindigkeit und Aufgabentyp abwägt und dann einen Pfad wählt. Dieser Rahmen hilft mir zu verstehen, warum sich zwei “GPT-5”-Labels unterschiedlich verhalten können.
Wie OpenAIs Versionierung funktioniert
OpenAI liefert Modellfamilien in der Regel mit benannten Versionen und gelegentlichen “Preview”-Builds. Im Laufe der Zeit kann eine Version zur Standardversion werden und später veraltet sein. Die Labels können sich schneller ändern, als Blog-Beiträge mithalten können. Wenn ich unsicher bin, überprüfe ich die OpenAI-Modelldokumentation und das API-Änderungsprotokoll, bevor ich eine Version festlege. Es lohnt sich auch, die API-Referenz auf kleine, aber wichtige Flags (Antwortschema, JSON-Modi, Tool-Calling-Nuancen) zu überfliegen, die sich zwischen Versionen ändern.
Wenn ich also “GPT-5” sage, meine ich das geroutete System, das unter diesem Familiennamen zugänglich ist. Und wenn ich “5.1” oder “5.3” sage, meine ich eine spezifische Konfiguration dieses Systems, oft mit unterschiedlichen Standardwerten, leicht unterschiedlichen Routern und manchmal neuen Sicherheits- oder Zuverlässigkeitsgarantien.
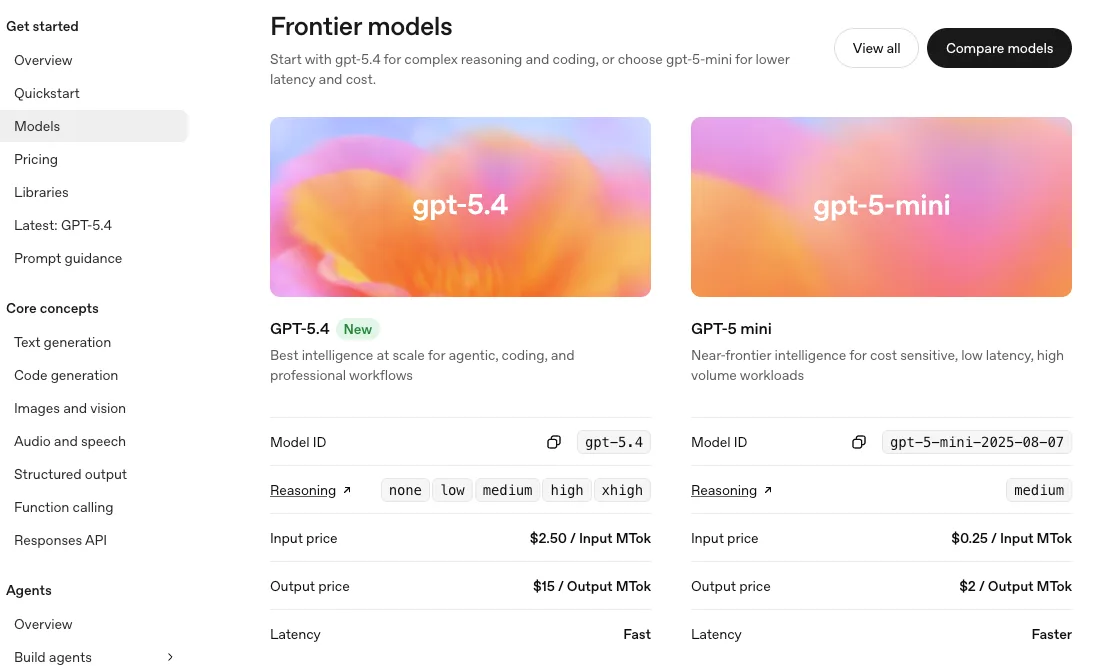
GPT-5 (Basis) — Anfängliche Fähigkeiten
Ich behandelte das GPT-5 zunächst als Generalisten. Nicht weil es magisch war, sondern weil es drei gängige Aufgaben mit wenig Einrichtungsaufwand recht gut erledigte.
Kernfunktionen beim Start
- Klarheit beim Schlussfolgern: Bei Planungsaufgaben wie “Entwirf mir einen 3-Schritte-Ansatz, dann fülle Schritt 1 aus” hielt das Basismodell die Struktur ein, ohne dass ich zu viel erklären musste. Es war nicht spektakulär. Es war beständig.
- Tool-Nutzung ohne Drama: Funktionsaufrufe funktionierten sofort. Wenn ich darum bat, strukturierte Felder zu extrahieren, wurden meistens konsistente, typisierte Argumente übergeben.
- Längerer Kontext ohne Zusammenbruch: Ich verwendete lange Briefings und mehrteilige Referenzen. Es blieb kohärent genug, um nützlich zu sein, besonders wenn ich es mit Abschnittsüberschriften verankerte.
- JSON-Modus und Antwortschemata: Mit einem einfachen Schema konnte ich beim ersten Versuch 8–9 von 10 Mal parsbare Ausgaben erhalten. Wenn es scheiterte, scheiterte es offensichtlich (abgeschnittenes Objekt), was eine seltsame Art von Gnade ist.
Frühe Einschränkungen
- Determinismus ist noch weich: Selbst bei niedriger Temperatur veränderten wiederholte Durchläufe leicht die Formulierung und manchmal die Reihenfolge. Für die Produktion musste ich eine leichte Nachbearbeitung hinzufügen (Schlüssel sortieren, Leerzeichen normalisieren), um Diffs ruhig zu halten.
- Tool-Aufruf-Gedächtnis: Wenn ich Tools verkettete, “vergaß” das Modell manchmal die Randbedingungen eines vorherigen Tools, es sei denn, ich stellte sie erneut dar. Eine kleine Unannehmlichkeit, aber real.
- Latenzspitzen: Die meisten Aufrufe waren in Ordnung. Dann dauerten ein oder zwei merklich länger. Keine Minuten, aber genug, um eine enge Schleife zu stören.
- Kostenbewusstsein: Das Basismodell war nicht das günstigste, daher fühlten sich unachtsam lange Prompts teuer an. Ich kürzte System-Nachrichten und lagerte Boilerplate in Code-Templates aus. Einfacher Schritt, bedeutsame Einsparungen.
GPT-5.1 bis GPT-5.3 — Inkrementelle Änderungen
Diese Punkt-Releases haben den Charakter der GPT-5-Modelle nicht verändert. Sie haben Schrauben angezogen.
Versions-für-Versions-Verbesserungen
- 5.1: Das Befolgen von Anweisungen wurde präziser. Wenn ich um “nur Aufzählungspunkte, keine Einleitung” bat, wurde es öfter befolgt. Die JSON-Konformität stieg ebenfalls leicht an.
- 5.2: Bessere Verankerung in Zitaten. Wenn ich Passagen bereitstellte und um zitatgestützte Zusammenfassungen bat, verankerte es sich sauberer im zitierten Text. Halluzinationen gingen zurück, nicht auf null, aber genug, dass ich es bemerkte.
- 5.3: Tool-Aufrufe fühlten sich unter Last verlässlicher an. Weniger seltsame Argumentformen. Ich sah auch leicht schnellere erste Token in meinen Logs, obwohl dies der Router sein könnte, der intelligentes Triage betreibt, nicht das Modell selbst.
All das zeigte sich auf stille Weise: weniger Wiederholungen, weniger Bereinigung, weniger Handhalten in Prompts.
Entwicklerorientierte Unterschiede
- Antwortschemata: Die neueren Releases waren auf gute Weise wählerischer. Wenn ich ein Schema deklarierte, befolgten sie es entweder oder schlugen schnell fehl. Das sparte mir mehr Zeit als jeder “Intelligenz”-Schub.
- Streaming-Deltas: Der Token-Stream kam in stabileren Blöcken. Einfacher, UIs zu bauen, die nicht zittern.
- Tool-Signatur-Toleranz: 5.2 und 5.3 verarbeiteten strenge Typen ohne Improvisation. Wenn ein Feld ein Enum war, erfand es seltener neue Werte. Das reduzierte Absicherungscode.
Diese sind klein, aber sie entfernen Papierschnitte. Wenn Sie Agenten pflegen, ist Klein über viele Aufrufe groß.
Was gleich blieb
- Kontextlängenrealitäten: Riesigen Kontext einzuspeisen bestraft weiterhin Latenz und Kosten. Kürzen und Indizieren gewinnen immer noch.
- Stil-Drift: Selbst mit Beispielen wanderte der Ton bei längeren Ausgaben etwas. Ich halte Referenz-Snippets bereit und bitte das Modell, diese nachzuahmen – das funktioniert besser als Adjektive.
- “One-Shot-Genie” ist selten: Die besten Ergebnisse kommen immer noch von stetigem Gerüstbau, klaren Zielen, kleinen Schritten und Feedback. Das Modell wurde besser, aber mein Systemdesign war wichtiger.
GPT-5.4 — Was aktuelle Leaks vermuten lassen
Ich habe beim Schreiben dieses Textes keinen Zugang zu 5.4. Ich stütze mich auf öffentliche Hinweise, Entwicklergespräche, ein paar SDK-Referenzen, die Leute entdeckt haben, und das allgemeine Muster, wie sich diese Familien entwickeln. Behandeln Sie dies als richtungsweisend, nicht als definitiv. Wenn Sie sich in der Nähe eines Launch-Fensters befinden, überprüfen Sie die Modelldokumentation und aktuelle Versionshinweise.
Hinweise auf den Fast-Modus
Es gibt anhaltende Gespräche über einen “schnellen” oder “Turbo”-Routing-Pfad in 5.4. Meine Vermutung: ein latenzorientiertes Profil, das einige Qualitätssicherungen lockert, im Geiste ähnlich den Geschwindigkeitsstufen, die wir in vergangenen Familien gesehen haben. Wenn das eintrifft, würde ich Folgendes erwarten:
- Schnellere erste Token-Zeit.
- Leicht höhere Varianz bei der genauen Formatierung, es sei denn, Sie verwenden strikte Schemata.
- Besseres Parallelverhalten für Chat-UIs und Live-Agenten.
Wenn Ihnen wahrgenommene Geschwindigkeit mehr am Herzen liegt als perfekte Formulierung, könnte dies der Standard werden.
Signale zur Bildverarbeitung
Einige Hinweise deuten auf ein stärkeres Bildverständnis und robustere OCR bei unübersichtlichen Eingaben hin (Blendung, schief eingescannte Quittungen, Code-Screenshots). Ich würde auch konstantere Antworten bei Diagrammen und Tabellen erwarten, besonders wenn Sie ein Zielschema angeben. Die praktische Konsequenz: weniger manuelle Vorverarbeitung. Heute beschneide oder verbessere ich oft Bilder vor dem Senden. Wenn 5.4 mehr von diesem Chaos absorbieren kann, entfällt ein ganzer Schritt.
Verbesserungen im Coding-Workflow
Die Diskussionen hier drehen sich um Planung und Multi-Datei-Bearbeitungen. Wenn dies stimmt, könnte 5.4:
- Klarere Schrittepläne vorschlagen, bevor Code angepasst wird.
- Funktionssignaturen über Dateien hinweg konsistent halten.
- Off-by-One- und Import-Pfad-Fehler reduzieren.
Selbst eine kleine Verbesserung der Zuverlässigkeit ist wichtig. In meinen Tests mit früheren Versionen entstand 70–80 % der “verlorenen Zeit” nicht durch Logik, sondern durch das Bereinigen von zuversichtlichen, aber leicht falschen Bearbeitungen. Wenn 5.4 das um nur 10–15 % reduziert, wird es sich wie mehr als ein inkrementelles Release anfühlen.

Wie Entwickler zwischen GPT-5.x-Versionen wählen
Ich wähle keine Version aus, weil ein Blog es mir so sagt. Ich führe kleine, langweilige Tests durch. Hier ist der Rahmen, der sich für mich bewährt hat.
Anwendungsfall-Zuordnung
- Inhaltsentwurf mit Tonsteuerung: Ich tendiere zu Neuerem (5.2/5.3), weil die Stiladhärenz leicht verbessert wurde. Ich halte eine kleine Bibliothek von Ton-Beispielen bereit und weise darauf hin.
- Strukturierte Extraktion: Welche Version mir die höchste Schema-Adhärenz liefert, gewinnt. In letzter Zeit war das 5.2 oder 5.3 mit expliziten Antwortschemata. Ich füge immer noch einen Validator und einen Retry hinzu.
- Agenten und Tool-Workflows: 5.3 war bei Funktionsargumenten am beständigsten. Wenn 5.4s Fast-Modus real ist, werde ich ihn A/B für Live-Agenten testen, die schnelles Hin-und-Her mehr brauchen als perfekte Prosa.
- Code-Unterstützung: Ich beginne mit kurzem Kontext und bitte zuerst um einen Plan. Wenn das Modell keinen glaubwürdigen Plan schreiben kann, wird es auch keine sauberen Diffs schreiben. Benachbarte 5.x-Versionen unterscheiden sich hier gerade genug, um wichtig zu sein – testen Sie auf Ihrem Repository, nicht auf einer Spielzeugdatei.
Ich verfolge drei Zahlen für jeden Anwendungsfall: erfolgreiche Erstdurchlaufrate, durchschnittliche Latenz und der Prozentsatz der Aufrufe, die menschliche Bereinigung benötigen. Wenn eine neuere Version nicht mindestens eine davon in die richtige Richtung bewegt, wechsle ich nicht.
Kosten-Nutzen-Abwägungen
Die OpenAI-Preise ändern sich, und ich werde hier keine Zahlen erraten. Das Muster ist jedoch stabil:
- Neuere Modelle sind nicht immer teurer, können es aber sein. Ich budgetiere nach Token, nicht nach Gefühl.
- Lange Prompts erhöhen die Kosten exponentiell. Ich streiche Boilerplate, komprimiere Beispiele und referenziere externe IDs wo möglich.
- Wenn Sie Arbeit batchweise erledigen (Zusammenfassungen, Extraktionen), gewinnt meist die günstigste zuverlässige Version. Bei benutzerorientierten Anwendungen zählt die wahrgenommene Geschwindigkeit oft mehr als die reinen Kosten.
Zwei praktische Tipps, die mir Geld und Zeit gespart haben:
- Goldene Sets: Halten Sie 20–50 echte Prompts mit bekannten guten Ausgaben bereit. Führen Sie sie erneut aus, wenn Sie einen Wechsel erwägen. Kein Gedächtnis, nur saubere Vergleiche. Sie werden die Kompromisse schnell sehen.
- Absicherungen im Code, nicht in Prosa: Schemata, Validatoren und kleine Nachprozessoren schlagen seitenweise Anweisungen.
Seitenaktualisierungsrichtlinie (kontinuierlich gepflegt)
Ich aktualisiere diese Seite, wenn ich bedeutsame Änderungen in GPT-5-Modellen sehe, normalerweise nach erneuter Ausführung meines Testsets oder wenn sich OpenAIs Dokumentation ändert. Ich füge eine kurze Notiz mit einem Datum hinzu, was ich getestet habe und was sich verändert hat (wenn überhaupt). Ich verlinke auf offizielle Quellen, wo ich kann, und kennzeichne Unsicherheiten, wenn ich etwas nicht überprüfen kann.
Wenn Sie mit ähnlichen Einschränkungen zu kämpfen haben, lohnt sich ein gelegentlicher Blick, aber warten Sie nicht auf mich. Die Modelldokumentation ist die Wahrheitsquelle. Ich halte meine Notizen beständig, nicht erschöpfend.
Eine kleine Beobachtung zum Abschluss: Je mehr ich “GPT-5” als ein lebendes System behandle statt als einen einzelnen Schalter, desto ruhiger werden meine Entscheidungen. Das Dropdown hört auf, sich wie ein Test anzufühlen. Es ist nur ein Knopf, den ich mit einem Grund drehe.
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten