GPT-5.4 für Entwickler: Was die geleakten Signale für KI-Workflows bedeuten
Schnellmodus, Vision-Upgrades und Coding-Agent-Signale – das könnten die GPT-5.4-Leaks für KI-Infrastrukturbuilder bedeuten.

Hallo, ich bin Dora. Ich hatte nicht geplant, GPT‑5.4 zu verfolgen. Ich bin einfach immer wieder auf kleine Stolpersteine in meinen Agent-Workflows gestoßen – Pausen, lang genug, um zu E-Mails zu wechseln und dann zu vergessen, was ich gerade getan habe. Wenn ein Modell „Fast Mode” und Bildverarbeitung in voller Auflösung verspricht, horche ich auf – nicht weil ich das Neueste haben möchte, sondern weil ich weniger dieser kleinen Unterbrechungen will.
Dieser Artikel richtet sich an GPT-5.4-Entwickler, oder genauer gesagt, an Entwickler, die entscheiden, ob und wie sie damit bauen wollen. Ich bin nicht hier, um das Modell zu verkaufen. Ich bin hier, um zu zeigen, wo es Reibung reduzieren könnte, wo es das wahrscheinlich nicht wird, und was man aufbauen sollte, damit die heutige Arbeit die morgigen Release Notes übersteht.
Warum Entwickler GPT-5.4 genau beobachten
Der Wandel zum Modell-als-Infrastruktur
Ich habe eine langsame, aber reale Verschiebung beobachtet: Modelle ähneln weniger „Produkten” und mehr Versorgungsunternehmen, durch die man Aufgaben leitet. Vor einem Jahr habe ich jedes Modell wie eine Persönlichkeit behandelt. Jetzt behandle ich sie wie Fahrspuren auf einer Autobahn: Spuren für hohe Genauigkeit, Geschwindigkeit und günstige Kosten – und ich versuche, reibungslos zwischen ihnen zu wechseln.
Wenn GPT‑5.4 ein Zwei-Spur-Muster (schnell/langsam oder schnell/denken) stabilisiert, ermutigt es uns, Agenten rund um Routing zu gestalten, nicht um einzelne Wetten. Das klingt abstrakt, bis man eine Aufgabe mit 12 Schritten debuggt und feststellt, dass Schritt 3 nur eine schnelle Klassifizierung benötigt, Schritt 8 aber sorgfältige Chain-of-Thought-Verarbeitung. Ich habe diese Logik in aktuellen Systemen von Hand zusammengestückelt. Es ist fragil. Wenn die Infrastruktur es einbaut, haben wir weniger Stellen, an denen man stolpern kann.
Ich beeindrucken Versionsnummern nicht: Ich interessiere mich dafür, ob ein Release mir erlaubt, Schritte zu reduzieren oder Verbindungscode zu entfernen. GPT‑5.4, wenn es in die angedeutete Richtung geht, könnte eines davon sein.
Warum inkrementelle Releases wichtig sind
Kleine Versionsbumps wirken langweilig, aber sie bewahren Teams vor Neuaufbauten. Wenn Modelle Schnittstellen stabil halten und gleichzeitig Latenz oder Bildgenauigkeit verbessern, muss ich weder Benutzer noch mich selbst neu einarbeiten. Der Wert zeigt sich in Dingen wie: weniger Wiederholungsversuche, präzisere Prompts, kürzere Timeouts.
Ich behalte die OpenAI API-Dokumentation und die Modellseiten im Blick auf strukturelle Änderungen statt auf Slogans. Wenn GPT‑5.4 sich in bestehende Endpunkte mit vernünftigeren Standardwerten und klarerem Systemverhalten einfügt, ist das ein Gewinn. Weniger Code-Änderungen, vorhersehbarere Logs. Und für alle, die Agenten in der Produktion warten, schlägt Vorhersehbarkeit jeden Tag Neuheit.

Fast Mode – Was er für Agent-Workflows verändert
Aktuelle Reasoning-Kosten in mehrstufigen Agenten
In meinen Läufen über den letzten Monat mit Modellen der aktuellen Generation dauert ein typischer mehrstufiger Agent (planen → abrufen → Tools aufrufen → zusammenfassen) 8–15 Modellaufrufe. Jeder Aufruf kostet zwei Dinge: Tokens und Aufmerksamkeit. Die Tokens kann man budgetieren. Die Aufmerksamkeit ist das, was einen erschöpft – die kleinen Wartezeiten, die teilweisen Wiederholungsversuche, die Momente, in denen man sich fragt, ob es feststeckt.
Bei mir dauert eine typische interne Tool-Auflösungsaufgabe durchschnittlich 20–45 Sekunden von Ende zu Ende. Das meiste davon ist kein schweres Reasoning: Es sind leichte Prüfungen und Formatierungen. Wenn GPT‑5.4s Fast Mode die Latenz bei diesen leichten Schritten reduziert und dabei die Genauigkeit gut genug hält, verändert das die Form des gesamten Laufs. Der lange Schwanz kleiner Wartezeiten wird gestutzt. Das sieht auf dem Papier nicht dramatisch aus, fühlt sich aber in der täglichen Arbeit besser an.
Dual-Mode-Inferenz und Routing-Logik
Was ich beobachte, ist, ob „Fast Mode” nur ein kleineres Modell ist oder wirklich ein Modell, das mit einem Denker innerhalb einer Grenze gepaart ist. Wenn die API einen sauberen Hinweis bereitstellt – sagen wir einen Parameter oder eine Tool-Level-Routing-Regel – kann ich die Entscheidung zentralisieren: schnell für Klassifizierung, vollständig für Synthese. Keine besonderen Verzweigungen mehr in jedem Agentenschritt.
In Tests mit heutigen Modellen habe ich Dual-Route-Verhalten prototypisiert, indem ich Schrittintention und Konfidenz geprüft habe. Es ist umständlich, aber funktioniert: schnelle Route für bekannte Muster, tiefe Route bei hoher Unsicherheit. GPT-5.4 wird wahrscheinlich dasselbe tun, wenn die API nicht automatisch routet. Falls es automatisch routet, verlagert sich die Aufgabe auf das Schreiben vernünftiger Leitplanken und Logging, damit man sehen kann, wann das Modell die langsame Spur zu oft nutzt.
In jedem Fall ist Logik der Kern. Eine Funktion namens „Fast” hilft nicht, wenn man nicht erkennen kann, wann sie verwendet wird. Ich nehme lieber einen einfachen Parameter und ein gutes Trace als Magie.
Implikationen der Tool-Aufruf-Schleife
Hier kommt es täglich an: Tool-Schleifen. Wenn ein Agent dreimal hintereinander den Taschenrechner, die Datenbank oder den Browser aufruft, summiert sich der Overhead. Wenn Fast Mode die Round-Trip-Kosten für das Parsen der Absicht und den Aufbau von Funktionsargumenten reduziert, schrumpft die Schleife. Das befreit Budget für die Schritte, die tatsächlich Reasoning benötigen.
Aber es gibt einen Haken: Wenn der schnelle Durchlauf auch nur 5–10 % der Aufrufe falsch weiterleitet, zahlt man es in Wiederholungsversuchen und Leitplanken zurück. Meine Faustregel ist einfach: Gesamtanzahl der abgeschlossenen Schleifen pro Minute messen, nicht die Latenz pro Aufruf. Wenn diese Zahl mit aktiviertem Fast Mode steigt, behalten. Wenn sie sinkt (mehr Wiederholungen, mehr Korrekturen), für diesen Flow deaktivieren. Es geht nicht um Geschwindigkeit, sondern um verlässlichen Durchsatz.
Bildverarbeitung in voller Auflösung – Praxisanwendungen
Screenshot-zu-Code-Pipelines
Ich betreibe eine kleine Screenshot-zu-Komponenten-Pipeline für interne Tools. Heute übersieht die Bildverarbeitung mit niedriger Auflösung winzige Abstände oder Zustandshinweise (Hover vs. Aktiv). Bildverarbeitung in voller Auflösung, wenn sie real und zu vernünftigen Token-Kosten zugänglich ist, ändert das. Das Modell kann den 1-Pixel-Rand und den subtilen Schatten sehen, der Erhöhung signalisiert.
In der Praxis würde ich es so verdrahten: Hochauflösender Durchlauf zur Beschriftung atomarer UI-Elemente, dann ein schneller rein textbasierter Durchlauf zur Code-Assemblierung mithilfe einer Bibliothekskarte. Zwei Durchläufe, jeder gut in seinem Bereich. Die Auszahlung ist nicht **„Design zu Code”-**Magie, sondern weniger manuelle Korrekturen. Bei einem einfachen Dashboard könnte das mir 10–15 Minuten und ein paar Trips zurück nach Figma ersparen.
UI-Debugging-Workflows
Ein ruhiger, aber nützlicher Fall: Bug-Reproduktionen. Ich bekomme oft Screenshots mit halb abgeschnittenen Error-Toasts oder Modal-Overlays. Hochauflösende Bildverarbeitung hilft dem Modell, über z-Index und Layout-Stacking nachzudenken, ohne dass ich es in Worten beschreiben muss. Das Modell kann anmerken: Der Schließen-Button des Toasts überlappt die Navigation: wahrscheinlich ein CSS-Stacking-Problem. Ich überprüfe es trotzdem, aber näher an der Lösung zu beginnen ist eine Erleichterung.
Für Teams könnte es in die Triage einfließen: Screenshot einfügen, eine Liste wahrscheinlicher Ursachen erhalten, plus Selektoren zum Untersuchen. Nichts Magisches, nur eine engere Schleife.
Interpretation von Design-Assets
Designer geben mir Exporte mit Namenskonventionen, die unter Zeitdruck abweichen – es passiert. Hochauflösende Bildverarbeitung plus Kontext über das Designsystem kann Ordnung wiederherstellen. Das Modell kann visuelle Tokens (Abstände, Radius, Farbkontrast) den nächstliegenden Designsystem-Variablen zuordnen.
Grenzen gelten weiterhin. Das Modell kennt den Geschmack Ihres Teams nicht. Aber es kann den langweiligen Teil erledigen: „Diese 12 Icons sind 20px, diese 3 sind 16px: wahrscheinliche Nichtübereinstimmung.” Das ist nicht schlagzeilen würdig, aber es ist die Art kleiner Korrektheit, die sich über einen Sprint summiert.
Coding-Agent-Signale im Kontext
Warum Leaks in Codex-Repos aufgetaucht sind
Sie haben wahrscheinlich Hinweise gesehen – Commits, die auf Agent-Signale verweisen, oder Configs mit unerklärten Routing-Flags. Ich interpretiere Leaks nicht zu viel, aber sie decken sich mit dem, was Entwickler brauchen: klarere Signale darüber, wann das Modell plant, handelt oder reflektiert. Frühere Codex-Ära-Repos haben das oft mit Heuristiken im Client gefälscht. Deshalb sind Configs geleakt: Logik musste außerhalb des Modells leben.
Wenn GPT‑5.4 festere Zustandssignale freilegt (auch einfache wie „Planen” vs. „Ausführen”), können Programmierer UI und Logging synchronisieren, ohne Signale aus dem Text zu parsen.
Potenzial für die Bearbeitung mehrerer Dateien
Mehrdatei-Bearbeitungen sind der Punkt, an dem Coding-Agenten versagen. Heute unterteile ich den Kontext, bitte um einen Plan und wende dann Diffs mit einem Linter in der Schleife an. Es funktioniert, bis es das nicht mehr tut – meist wenn der Agent eine kleine Datei vergisst oder etwas mittendrin umbenennt. Bessere native Unterstützung würde so aussehen: einen Commit mit einer Dateikarte vorschlagen, Begründung pro Datei einschließen und mir erlauben, Änderungen pro Datei zu akzeptieren.
Auch ohne neue Primitiven könnte GPT‑5.4s verbessertes Reasoning (wenn es ankommt) plus strengere Nachrichten – „Zeig mir einen Patch-Satz, keine Prosa” – die Fallstricke reduzieren. Ich hatte einigen Erfolg damit, ein Patch-Format zu erzwingen und alles andere abzulehnen. Es ist langweilig. Es hilft.
Verbesserungen bei der Repository-Navigation
Kontextfenster sind größer geworden, aber Navigation ist immer noch wichtig. Die besten Coding-Läufe, die ich 2026 hatte, verwenden einen schnellen Indexer, der eine Symbolkarte und einen Abhängigkeitsgraphen erstellt, und dann nur die relevanten Ausschnitte einspeist. Wenn GPT‑5.4 besser darin ist, diese Karten zu lesen – Querverweistabellen, Symbolzusammenfassungen – können wir dünneren, schärferen Kontext übergeben.
Ein praktisches Signal, das man beobachten sollte: Wie oft der Agent nach einer Datei fragt, die er bereits gesehen hat. Weniger Wiederholungen bedeuten normalerweise, dass er ein besseres Arbeitsset aufbaut. Ich protokolliere das. Wenn Sie es nicht tun, fangen Sie jetzt damit an: Es ist eine einfache Metrik, die man über Releases hinweg beobachten kann.
Was Entwickler jetzt aufbauen sollten
Modell-agnostische Architekturmuster
Ich versuche, Modelle hinter einem schmalen Port zu halten. Ein Broker entscheidet über das Routing: Tools bleiben zustandslos und in Logs sichtbar: Prompts leben in versionierten Dateien mit Tests. Auf diese Weise kann ich, wenn GPT‑5.4 Fast Mode lohnend macht, Spuren wechseln, ohne alles neu zu verdrahten.
Zwei Muster, die sich für mich bewährt haben:
- Typisierte Tool-Schemas mit strikten Validatoren. Weniger Raterei, weniger schlechte Aufrufe.
- Trace-First-Design. Jeder Agentenschritt schreibt ein kompaktes Trace, das ich wiedergeben kann. Wenn ein Modell-Update das Verhalten ändert, kann ich alte und neue Läufe vergleichen.
Keines davon ist glänzend. Beides ist das, was das Liefern am Laufen hält, wenn Modelle sich verschieben.
Modell-Release-Kanäle überwachen
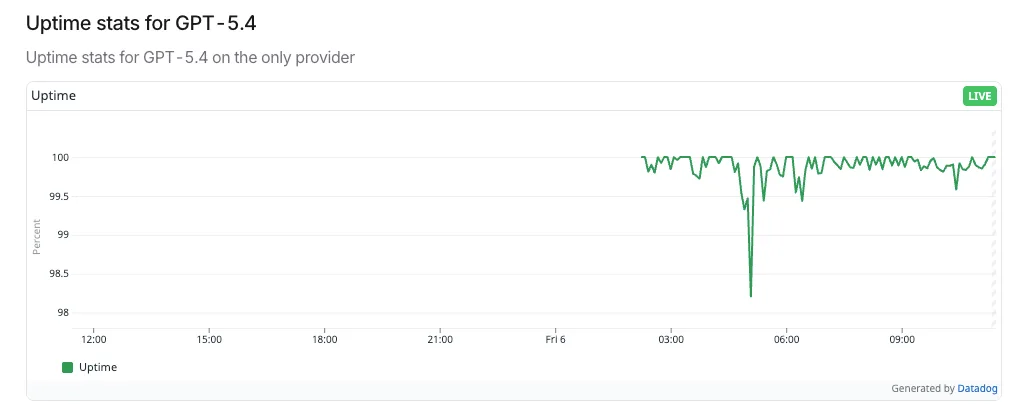
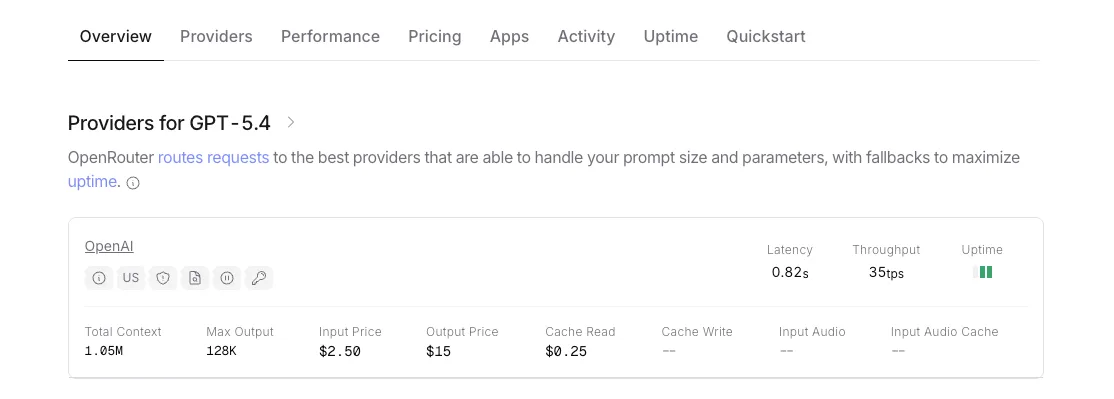
Auch wenn Sie sich nicht schnell bewegen, beobachten Sie die Kanäle. Ich abonniere Modellseiten und überfliege die Modellliste und Release-Notes. Ich markiere drei Dinge pro Update: Latenzhinweise, Token-Preise und alle neuen systemweiten Schalter (Modi, Routing, Sicherheitsverhalten). Dann führe ich einen kleinen Benchmark-Satz erneut aus – 10–20 Traces, die meine echten Workflows repräsentieren.
Das dauert eine Stunde. Es spart später Tage. Wenn GPT‑5.4 phasenweise ausgerollt wird (das geschieht normalerweise so), sehen Sie die Randfälle zuerst in Traces, nicht in Support-Tickets. Das ist der Sinn des Monitorings: Drift ruhig erkennen, bevor es zum Brand wird.

Status-Hinweis
Ich wurde nicht gesponsert, um das zu schreiben. Ich habe auch noch keine Produktionswetten auf GPT‑5.4 gemacht. Meine Notizen hier stammen aus angrenzenden Experimenten und Mustern, die sich über frühere Modell-Updates gehalten haben. Wenn und wenn offizielle Dokumente Modi oder Bilddetails klären, werde ich sie verlinken und anpassen. Bis dahin sollte man das als Feldnotizen behandeln – hoffentlich nützlich, aber vorläufig.
Noch eine letzte Sache, über die ich noch nachdenke: Wenn Fast Mode die stillen Teile schneller macht, bemerken wir dann weniger – oder machen wir uns einfach weniger Sorgen? Mit beidem kann ich leben.
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten