Seed2.1 Pro vs Turbo: A Pre-Launch Decision Tracker
Track whether Seed2.1 Turbo becomes official and how builders should evaluate model variants without unverified claims.

This piece is a tracker, not a review. Seed2.1 Pro is real. A Turbo variant is not — at least not in any documentation I can verify today. I’m publishing this as a holding document so that when (or if) the second variant lands, the evaluation scaffolding is already in place and the team doesn’t end up writing a comparison piece in a panic.
If you’re routing production traffic across model tiers and watching the Seed family for a faster sibling to Seed2.1 Pro, this is what’s worth tracking, what’s not worth assuming, and what would actually trigger a real comparison article.
I’ll mark every claim with what I can verify. Where something is rumored, inferred, or carried over from the Seed 2.0 era, I’ll say so plainly.
What Is Confirmed About Seed2.1 Variants?

Short version: one variant is documented. The other isn’t.
Seed2.1 Pro is the confirmed release. It sits in the position you’d expect — the higher-capability tier in the Seed2.1 generation, intended for tasks where quality matters more than per-token cost. That’s the limit of what’s publicly verifiable as of writing.
A “Seed2.1 Turbo” name has been circulating in community discussions and a few secondhand writeups. I have not found it in official documentation, an API model ID, a pricing page, or any first-party announcement. Until one of those four things appears, treating “Turbo” as a real product name is a guess.
What makes the guess plausible — but still a guess — is the Seed 2.0 history. The previous generation shipped multiple variants under names that followed a recognizable tiering pattern (a flagship, a faster/cheaper sibling, sometimes a specialized variant). The ByteDance Seed research page is the canonical place to track which variants have actually been announced — worth bookmarking rather than relying on secondhand summaries. If Seed2.1 follows the same playbook, a second tier is likely. The name “Turbo” is one of several plausible labels. It could just as easily ship as Flash, Lite, Mini, Fast, or something else entirely. Naming has shifted across vendors recently and there’s no reason to assume continuity.
Three things I’m specifically not assuming:
- That a second variant is imminent.
- That it will be called Turbo when (or if) it ships.
- That its capabilities will mirror the Seed 2.0 fast-tier behavior — model families re-tier between generations, and the gap between Pro and a hypothetical second variant could be smaller, larger, or differently shaped than last time.
This is where the article pauses. There is not enough confirmed information to write a real comparison. What follows is the evaluation scaffold for when there is.
How the Variants Should Be Evaluated
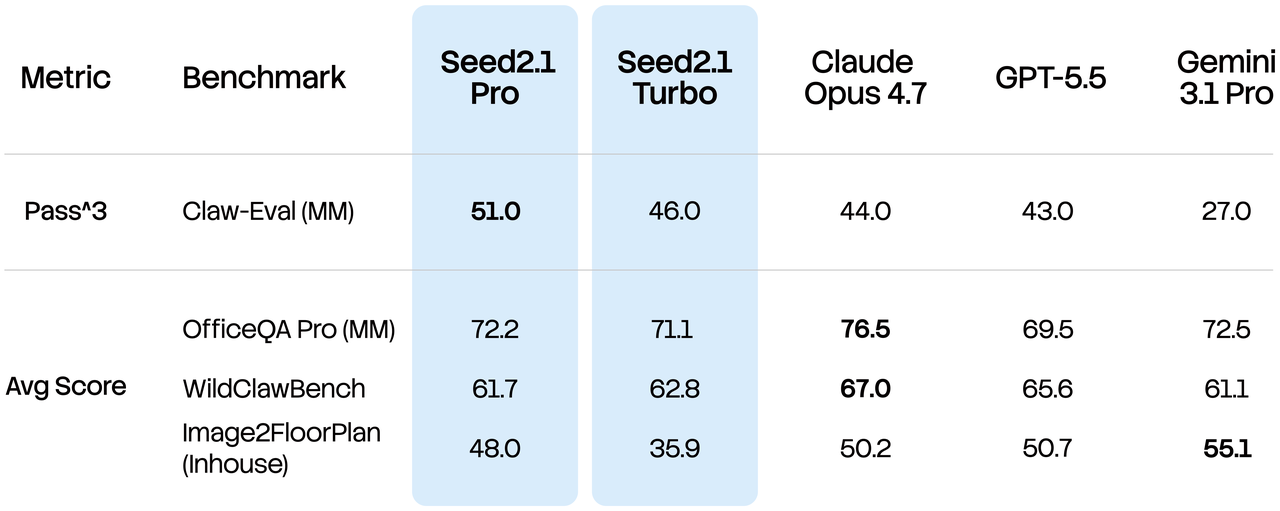
When a second variant lands — under whatever name — the comparison shouldn’t be a generic benchmark sweep. It should be a workload-shaped matrix that maps to how teams actually deploy these models. Sketching this out now means the comparison can ship within days of the launch, not weeks.
The dimensions worth measuring:
| Dimension | What to measure | Why it matters |
|---|---|---|
| Coding API workloads | Pass rate on multi-file edits, function-calling accuracy, refactor coherence | Coding API traffic is where tier differences show up fastest — quality gaps compound across a multi-step agent run. |
| Document AI tasks | Long-context retrieval accuracy, table extraction, layout preservation | Document AI workloads punish models that trade context fidelity for speed. |
| Production agents | Tool-call success rate, recovery from failed calls, loop termination | Production agents amplify small reliability gaps into observable failure rates. |
| Latency at p50 / p95 / p99 | Token-to-first-byte and full-response time across load levels | The tail latency, not the median, is what breaks real systems. |
| Structured output | JSON / schema adherence under adversarial prompts | A faster tier that drops schema compliance under load is worse than no faster tier. The OpenAI structured outputs guide is a reasonable reference for what “strict” schema adherence is supposed to look like in practice. |
| Failure modes and fallback | What does each variant do when it can’t answer well? | Faster variants tend to fail differently — silent confidence is worse than visible refusal. |
 The point of laying this out before the launch is to avoid the common mistake: when a faster variant ships, teams benchmark it on the easy stuff (single-turn Q&A, short generations, simple JSON), get encouraging numbers, route production traffic to it, and discover the real gaps in production at 2 a.m. Anthropic’s engineering writeup on building effective agents makes the same point from a different angle — the failure modes that matter are the ones that only show up under real workload composition, not benchmark composition.
The point of laying this out before the launch is to avoid the common mistake: when a faster variant ships, teams benchmark it on the easy stuff (single-turn Q&A, short generations, simple JSON), get encouraging numbers, route production traffic to it, and discover the real gaps in production at 2 a.m. Anthropic’s engineering writeup on building effective agents makes the same point from a different angle — the failure modes that matter are the ones that only show up under real workload composition, not benchmark composition.
Model routing decisions belong in this matrix too. The question isn’t just “is the faster variant good enough?” — it’s “good enough at what, and what’s the routing rule that captures that?” A binary “use Pro for hard tasks, fast tier for easy ones” rule is almost always wrong, because the classifier that decides “hard vs easy” is itself a model and itself wrong some percentage of the time. The matrix above is what you’d use to build a smarter routing policy.
Anthropic’s documentation on choosing between Claude models gives a reasonable template for how a vendor frames tier selection — useful as a reference for what kind of guidance the Seed team might eventually publish, and a reminder that vendor-published routing advice is a starting point, not a substitute for your own evaluation.
What Would Trigger Publication?
This article stays in the holding state until specific evidence appears. Listing the triggers so the decision is mechanical, not subjective:
-
An official model name in vendor documentation. Not a tweet, not a leak, not a community discussion thread. The vendor’s own published docs.
-
A working model ID accessible through the API. Something a developer can actually call. The ID itself is also load-bearing — slug, filename, and focus keyword in this article all have to be revised if the name turns out not to be “Turbo.”
-
API documentation describing capability and context-window differences. Marketing copy isn’t enough. The reference docs need to state what’s different from Pro.
-
Published pricing. Without per-token pricing, the “should I route traffic here?” question can’t be answered, and the comparison piece is academic.
-
Stated rate limits and concurrency limits. These are part of the production decision, not a footnote. A faster tier with strict limits behaves very differently from one without. Anthropic’s rate limits documentation is a useful template for the kind of detail that should be available before you commit traffic — request-per-minute, token-per-minute, and concurrency caps all matter for different reasons.
If any of those five exist but others don’t, the article can move into draft but not publish. If all five exist, publication is justified.
If the official name turns out to be anything other than “Turbo” — Flash, Lite, Mini, or something else — the title, focus keyword, URL slug, and most of the meta fields on this post have to be rewritten before it goes live. I’d rather catch that now than redirect URLs later.
Final note on what would not trigger publication: a leaked benchmark, a vendor employee’s social post, or a third-party SDK adding a new model constant ahead of the official announcement. Those are signals worth tracking, not facts worth publishing on.
FAQ
Can one evaluation set fairly compare different latency tiers?
Only if the evaluation reports per-dimension scores separately rather than collapsing into a single number. A model that’s 30% faster but 5% worse on structured output isn’t “worse on average” — it’s a different tradeoff curve. The same evaluation set works across tiers; the same scoring methodology often doesn’t.
What routing mistakes appear after adding a faster tier?
The two I see most often: routing all “short” prompts to the faster tier (length is a bad proxy for difficulty), and routing based on a one-time classification rather than re-checking when the conversation evolves. A conversation that starts simple and becomes complex needs to escalate mid-stream, and most routing layers don’t support that cleanly.
Should fallback models share identical structured-output constraints?
Yes, and this is non-negotiable for production agents. If your primary model produces a JSON schema and your fallback produces something subtly different — different null handling, different array shapes, different enum casing — your downstream consumers break at the worst possible time. Lock the schema at the consumer boundary, not at the model boundary.
When does maintaining two variants create unnecessary overhead?
When the volume on the secondary tier is too low to justify the operational cost of monitoring it. Two models means two sets of dashboards, two failure-mode catalogs, two prompt-tuning workstreams. If the faster tier carries less than roughly 15% of traffic, the overhead usually isn’t worth it — pick one and standardize. This rule of thumb is mine, not a vendor recommendation.
Conclusion
Seed2.1 Pro is real. Anything called “Seed2.1 Turbo” is not, as far as official documentation is concerned today. This article exists to make sure the moment a second variant ships — under whatever name — the evaluation scaffolding is already in place and the comparison can be honest from day one.
The scaffolding is the point. The benchmark matrix, the routing questions, the FAQ — all of it works regardless of what the second variant ends up being called or how it ends up being positioned. Run those evaluations on your own workload before trusting any vendor framing of “Pro vs [faster tier].”
I’ll update this when something verifiable lands. Until then, this is where it sits.
Previous posts:
Related Articles

Seedance 2.0 Mini API: Production Integration Guide

Unlimited-OCR vs DeepSeek-OCR 2: Production Tradeoffs

Seed2.1 API: What Builders Should Verify

Seedance 2.5 API Watch: Access and Production Readiness

What Is Unlimited-OCR? Long-Document Parsing Explained
