GPT-5.5 API 可用性:團隊應如何規劃
GPT-5.5 已宣布,但 API 存取尚未完全上線。以下是團隊現在可以規劃的事項,以及仍需驗證的內容。

上週五,我花了一整天把 Codex 工作流程改接到 GPT-5.5,然後週一又花時間向兩位客戶解釋,為什麼這個推出決策比媒體標題所呈現的複雜得多。我的名字出現在 WaveSpeedAI 許多「我們應該遷移嗎?」的文件上,所以我是 Dora——那個讓團隊等兩週才簽核模型切換的人。API 已上線。這是大多數報導說對的部分,然後就停在那裡了。 我想寫的是上線後的十天,當「可用」變成「真正整合」,以及我合作的大多數團隊正在碰壁的地方。
這是一份規劃筆記,不是教學文章。如果你是來找 curl 範例的,官方文件比我寫得更好。
GPT-5.5 目前的可用狀態
ChatGPT 和 Codex 的推出狀態
GPT-5.5 於 2026 年 4 月 23 日 在 ChatGPT 和 Codex 中向 Plus、Pro、Business 和 Enterprise 用戶上線,其中 GPT-5.5 Pro 僅限 Pro、Business 和 Enterprise 方案。在 Codex 中,該模型配備 400K 上下文視窗,以及以 2.5 倍成本換取 1.5 倍速度的 Fast 模式——詳情在 OpenAI 的 GPT-5.5 發布公告 中有清楚說明。第一天的發布僅涵蓋消費者介面。我想特別標注這點,因為上週我看到的工單有一半都假設 API 從一開始就與消費者介面同步上線。
OpenAI 關於 API 可用性的說明
早期媒體報導遺漏的部分:API 存取在一天後才上線,也就是 2026 年 4 月 24 日。 gpt-5.5 和 gpt-5.5-pro 現在都已在 Responses 和 Chat Completions API 中公開,詳見 OpenAI 自家的 GPT-5.5 模型文件。API 介面的上下文視窗為 100 萬個 token,不同於 Codex 的 40 萬上限。兩個介面,兩個限制——很容易混淆,值得在你的工程師之前就先記下來。所以問題不再是「我的團隊什麼時候可以用」,而是「我們應該用嗎?我們要先驗證什麼?」
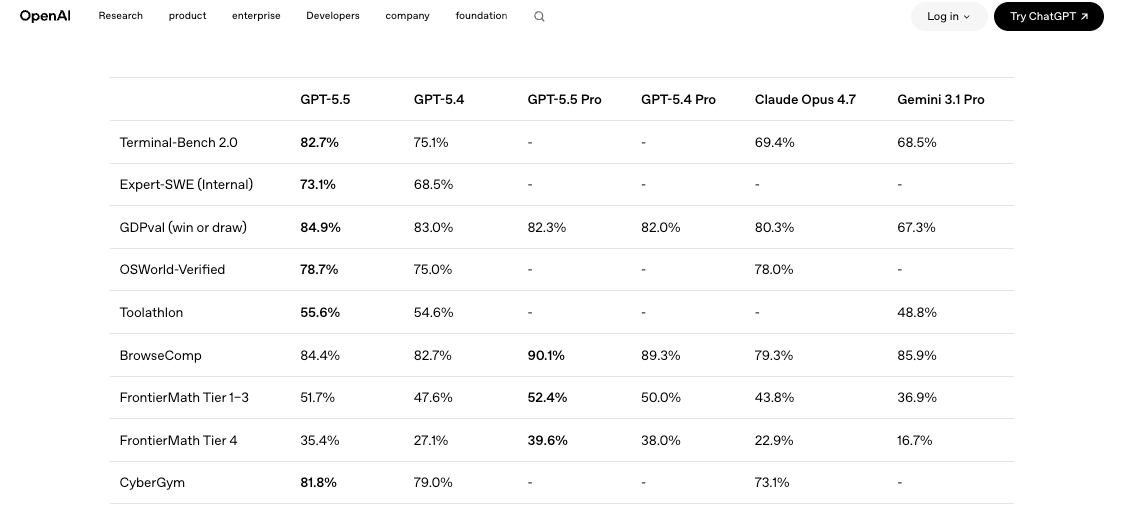
API 整合前,團隊可以安全規劃的事項
評估標準與遷移準備
我不建議當天就遷移。以下是我會先確定的事項。
針對你現有的模型建立一套小型評估框架。從你的實際工作負載中挑選五到十個有代表性的提示詞,依據真正重要的維度評分:正確性、token 成本、延遲、重試率。以相同提示詞、相同溫度設定、相同工具定義並排執行 GPT-5.4 和 GPT-5.5。LLM Stats 發布的獨立基準測試比較 顯示 GPT-5.5 在 10 個共用基準中的 9 個領先,但在 SWE-Bench Pro 上只有微幅進步。言下之意:升級是真實的,但並非全面性的優勢。你的工作負載才是決定因素。
現在就決定你的備援方案,不要等到第一個 429 錯誤才想。新模型發布後,前 30 天的速率限制歷史上都會比較嚴格。在你切換任何一個生產請求之前,先把 GPT-5.4 設定好作為備援。我見過兩個團隊跳過這個步驟,然後在上線日流量高峰時付出代價。
採購、安全性和工程方面的問題
這週我必須回答的幾個問題:
- 定價翻倍了。 標準費率是每 100 萬個輸入 token $5 美元、每 100 萬個輸出 token $30 美元,詳見 OpenAI 官方定價頁面。Pro 方案是 $30 / $180。Token 效率的提升在 Codex 工作負載上可以部分抵消這個成本,但在大多數其他工作負載上,預期帳單會有明顯增加。
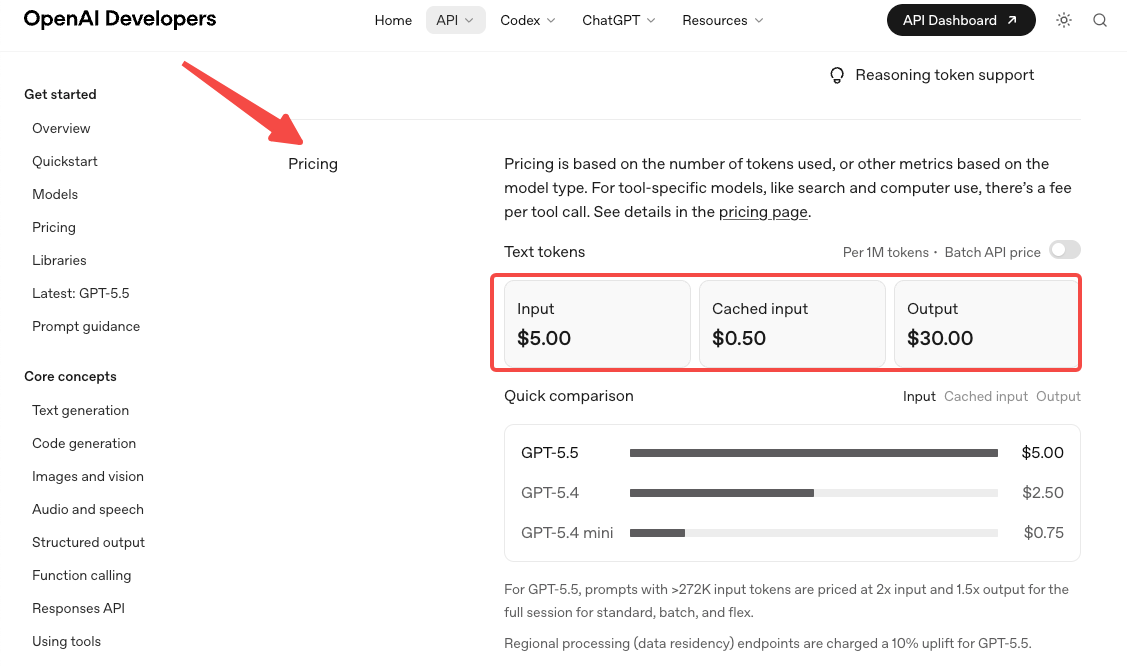
- 長上下文定價在 272K 處改變。 超過該門檻後,整個 session 的輸入費率變為 2 倍、輸出為 1.5 倍。如果你的工作流程經常超過 272K token,請對成本做兩次模擬——一次在門檻以下,一次在門檻以上。這個問題常見於那些圍繞 GPT-5.4 分級結構建置系統、並假設新模型會沿用相同結構的團隊。
- 安全團隊需要閱讀系統卡。 GPT-5.5 配備更嚴格的資安分類器,詳見 GPT-5.5 系統卡。在 OpenAI 調整期間,部分合法工作負載可能一開始會被攔截。值得提醒所有透過 API 執行安全工具、程式碼分析管道或紅隊工作流程的人。
投入生產使用前仍需驗證的事項
模型 ID、速率限制、定價和工具支援
我建議按以下順序驗證:
-
模型 ID 和快照。 鎖定快照,而非別名。別名會變動;快照不會。在將任何內容硬編碼到客戶端之前,先在 GPT-5.5 模型頁面 上確認可用清單。
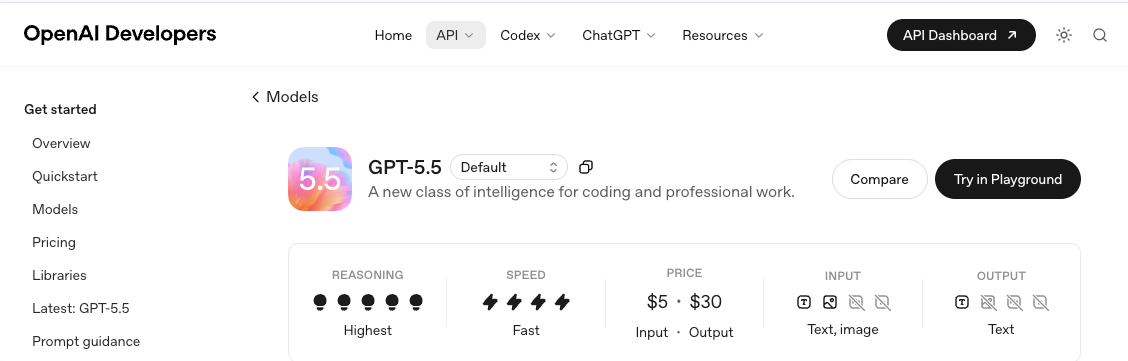
-
你的方案速率限制。 OpenAI 的分級系統會根據消費自動升級,但上線日的限制可能比 GPT-5.4 目前享有的更嚴格。OpenAI 速率限制文件 是我的起點,在假設容量足夠之前,值得先針對你目前的方案執行一次合成突發測試。
-
工具和結構化輸出的行為。 函式呼叫、網路搜尋和結構化輸出都可以運作,但確切的 schema 和推理模式的交互行為需要針對你實際的工具定義進行冒煙測試。我見過推理努力程度設定以不會在生產流量之前顯現的方式改變重試行為。
吞吐量與企業推出細節
對於運行大量請求的團隊:Batch 和 Flex 以標準費率的一半執行,Priority 則是 2.5 倍。言下之意:如果你的工作可以接受非同步處理,GPT-5.5 的 Batch 模式每個 token 的成本與標準方案的 GPT-5.4 相同。 這才是這次發布中隱藏的真正套利機會,而我認識的人中幾乎沒有人將其納入考量。apidog 上的 GPT-5.5 定價明細 提供了比我更好的實例說明。
直接整合供應商 vs 平台化整備
我在一個聚合模型存取的平台工作,所以我的立場是公開的。但這個結構性論點不論你使用誰的平台都相同:當單一供應商在第一天就發布一個 2 倍定價的模型時,路由邏輯的必要性反而變得更強,而非更弱。
直接整合供應商的做法是這樣的:重寫客戶端、重新測試提示詞、重做成本模型,每個供應商都要重複這些步驟。多模型平台——包括 WaveSpeedAI,但也包括其他平台——讓你只需修改設定就能切換模型。取捨在於你在自己和來源之間多了一個層級。對於每天頻繁發布的高頻團隊來說,這個層級通常值得這種抽象化。對於在低流量單一工作負載上執行一個模型的團隊來說,則不然。
無論如何,我都建議規劃路由設定。高價值查詢走 GPT-5.5,常規流量走 GPT-5.4 或其他前沿模型——光是這個模式,相較於單一模型預設設定,通常就能削減 40–60% 的帳單,不論你以哪個供應商為中心。
常見問題
GPT-5.5 的 API 是否已上線?
是的,自 2026 年 4 月 24 日起。4 月 23 日的發布僅涵蓋 ChatGPT 和 Codex;API 在一天後才跟進。gpt-5.5 和 gpt-5.5-pro 均可在 Responses 和 Chat Completions 端點存取,上下文視窗為 100 萬個 token。
團隊在開始整合工作之前應該驗證什麼?
你實際 token 組合的定價影響、你目前方案的速率限制上限、確認 GPT-5.4 備援已設定並測試完成,以及一個在你實際工作負載上比較兩個模型的簡短評估框架。鎖定快照 ID,而非別名。
等待而不使用 GPT-5.4 是否值得?
取決於工作負載。對於代理型程式設計和電腦使用任務,GPT-5.5 展現出明顯進步,如 TechCrunch 的發布報導 所記載。對於 GPT-5.4 已符合品質要求的工作負載,在沒有可衡量提升的情況下,翻倍的每 token 定價很難說得過去。
團隊應如何準備快速的 API 推出?
現在就建立評估框架,如果你還沒有的話透過抽象層路由,並假設速率限制在放寬之前會先收緊。不要預付大量點數餘額——這一世代的定價仍在變動中。
翻倍的定價真的意味著帳單翻倍嗎?
不,但相去不遠。Codex 工作負載的 token 效率提升讓實際帳單低於 2 倍。在其他工作負載上,預期接近標示價格。Batch 處理以半價執行,是最值得先拉的槓桿。
結論
API 已上線。定價已改變。速率限制仍在調整中。這些都不意味著你應該急著行動。 它的意思是,大多數團隊原本期望的規劃視窗比預期更快關閉,現在的工作是驗證,而非等待。
我正在進行我自己的遷移,預計需要兩週時間。GPT-5.5 在那之後是否會留在我的預設路由中——我還不知道。這正是評估的用途所在。
待續。




