Claude Mythos 與 Claude Opus 4.6 對比:洩露內容對開發者意味著什麼
Claude Mythos 與 Opus 4.6 對比:從洩露內容看能力差距,開發者究竟該等待還是立即動手。

上週在衝刺 Claude Code 整合 的過程中,Mythos 洩漏消息突然出現在我的動態中。十分鐘內收到三條 Slack 訊息,都是同一個問題的變體:「我們該暫停建置嗎?」我是 Dora,AI 愛好者,從那時起便密切追蹤這件事——我認為答案比炒作所暗示的更加微妙。
在 WaveSpeedAI 上執行 Claude Opus 4.6(以及更新的 Opus 4.7) — 按 Token 計費,相容 OpenAI。Claude Opus 4.6 API → · Claude Opus 4.7 API → · 開啟 Playground →
讓我帶你了解洩漏內容的實際內容、Opus 4.6 目前能提供什麼,以及如何就時機做出真實的決策。
基準:Claude Opus 4.6 目前為開發者提供什麼
在深入討論 Mythos 推測 之前,先以目前實際可用且有文件記錄的內容為基礎。
程式碼與代理任務效能
Claude Opus 4.6 在 Terminal-Bench 2.0 上達到 65.4%,在 OSWorld 上達到 72.7%,使其成為 Anthropic 在程式碼和電腦使用任務上最強的公開可用模型。Terminal-Bench 的數字不僅僅是一個基準獎杯——它代表真實的代理能力:多步驟除錯、大規模重構,以及在延伸工作流程中跨工具的自主鏈接。
該模型專為跨整個工作流程而非單一提示運作的代理而建置,使其對於大型程式碼庫、複雜重構以及隨時間展開的多步驟除錯特別有效。如果你在建置程式碼代理或代理管道,這是真正能解決問題並以生產品質交付程式碼的模型。
在運營上重要的是:Opus 4.6 將複雜任務分解為獨立的子任務,並行執行工具和子代理,並以真實精確度識別阻礙因素。這正是在真實 CI/CD 相鄰自動化中造成差異的行為,而非僅在示範環境中。
API 可用性、定價與文件
這是對你的決策時間軸真正重要的部分。Claude Opus 4.6 以每百萬 Token 輸入 $5/輸出 $25 的價格提供最先進的推理能力——相較於 Opus 4.1 時代的 $15/$75 降低了 67%。完整的 Claude API 文件是公開的、有版本控制的且穩定的。你今天就可以透過 claude-opus-4-6 存取它。
4.6 世代的一個突出特點是,完整的 100 萬 Token 上下文視窗包含在標準定價中,消除了適用於早期模型的長上下文額外費用。對於處理大型程式碼庫攝入或長期研究工作流程的團隊來說,與前幾代相比,這是一個顯著的成本降低。
目前已完整記錄且可立即使用的成本優化槓桿:
Claude Mythos 洩漏說明了什麼差距
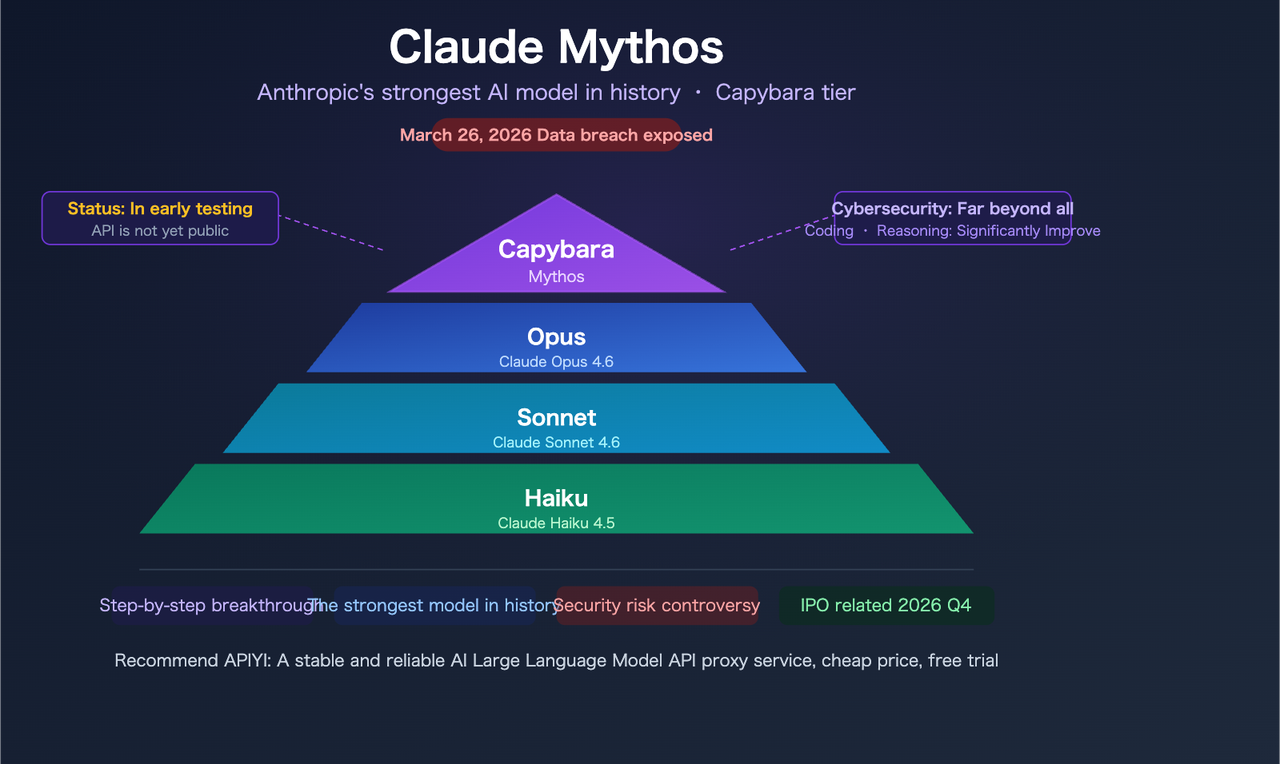
本月初,Fortune 報導 Anthropic 在一個配置錯誤的公開可搜尋資料存儲中意外暴露了近 3,000 個內部檔案。其中包括:一篇關於名為 Claude Mythos 的模型的草稿部落格文章——內部代號也稱為「Capybara」。
深入了解之前的重要框架:以下所有內容均來自未經驗證的草稿文件,而非官方發布。 沒有公開基準、沒有 API 存取、沒有定價頁面。Anthropic 已確認該模型存在並處於有限測試中。其他一切仍是草稿。
程式碼——「大幅更高的分數」解析
洩漏的部落格指出:「與我們之前最好的模型 Claude Opus 4.6 相比,Capybara 在軟體程式碼、學術推理和網路安全等測試中獲得了大幅更高的分數。」這是來自內部文件的有意義措辭——「大幅更高」不是迴避的行銷文案,這是一個強烈的內部聲明。
我們沒有的:具體數字。除草稿中的定性語言外,沒有發布具體分數。任何人現在引用確切的 Mythos 基準數字都是在編造。這裡誠實的解讀是,Anthropic 的內部評估顯示差距大到足以保證一個新的產品層級——這本身就是重要的訊號,但與擁有已驗證的數據不同。

學術推理改進
洩漏的草稿將學術推理與程式碼並列為關鍵的差異化能力。Anthropic 將 Mythos 描述為「在推理、程式碼和網路安全方面有重大進展的通用模型」。對於建置研究助手、文件分析管道或法律/財務推理工作流程的開發者來說,這值得關注——Opus 4.6 已在 BigLaw Bench 上達到 90.2%,如果 Mythos 進一步推進這個領域,使用案例的表面積將大幅擴展。
網路安全能力:全新領域
這是獲得最多報導的能力維度——理由充分。洩漏的草稿描述該模型「在網路能力方面目前遠超任何其他 AI 模型」,並警告它「預示著即將到來的一波模型,可以以遠超防禦者努力的方式利用漏洞」。
洩漏的內部文件警告,該模型可能透過快速發現和利用軟體漏洞來顯著提高網路安全風險,可能加速網路軍備競賽。這就是為什麼 Anthropic 的初始推出僅限於專注於網路防禦的組織——這個不尋常的舉動表明對濫用的真實擔憂,而非僅僅是標準的安全劇場。
這裡的雙重用途緊張關係是真實的。Anthropic 目前的 Opus 4.6 已展示出在生產程式碼庫中發現先前未知漏洞的能力,該公司承認這是雙重用途——同時幫助駭客和防禦者。Mythos 似乎進一步推進了這一能力,這解釋了謹慎推出的原因。
這是一個新層級,而非版本升級——為何重要
Capybara 在結構上高於 Opus
洩漏的草稿指出:「Capybara 是一個新名稱,代表一個新的模型層級:比我們的 Opus 模型更大、更智慧——而 Opus 模型直到現在都是我們最強大的。」這在結構上與 Opus 4.5 → Opus 4.6 不同。Anthropic 目前有三個層級:Haiku、Sonnet、Opus。Capybara 將在所有層級之上新增第四個。
這影響你如何設計你的系統。如果你在假設 Opus 始終是上限的情況下建置,那麼其上的新層級意味著潛在的能力升級,這不僅僅是漸進式的微調升級——它們代表一個不同類別的任務成功率。
定價:設計上更昂貴
目前沒有官方定價,但結構訊號很明確。草稿部落格指出,該模型運行成本昂貴,尚未準備好供大眾使用。鑑於 Capybara 在新層級中位於 Opus 之上,預計定價將高於 Opus 4.6 目前的每百萬 Token $5/$25。高出多少確實未知——但計劃它會明顯更高,而非僅小幅增加。
這不一定是壞消息。從 Opus 4.1 到 Opus 4.6 降價 67% 顯示 Anthropic 已學會在幾代之間降低旗艦定價。Capybara 今天以溢價定價推出並不意味著 12 個月後仍保持如此。這個模式表明真正的投資回報問題是,能力躍升是否能在你特定的任務分佈上證明成本的合理性。

你的團隊是否應該等待 Claude Mythos?
這是你真正來這裡尋求的決策。以下是誠實的框架。
如果你在建置程式碼代理或代理工作流程
現在就用 Opus 4.6 建置。 能力差距可能是真實的,但等待一個沒有公開時間表的未發布模型不是一個產品策略。Opus 4.6 已經是用於代理程式碼最強的公開可用模型——Terminal-Bench 2.0 的 65.4% 是一個有意義的基準,今天就支援生產使用案例。
更重要的一點是:你現在做出的架構決策——提示快取策略、子代理編排、工具使用模式——將在 Mythos 推出時直接轉移過去。在 Opus 4.6 上建置,設計模型無關的路由,當它推出時,你將比那些等待並從頭開始的團隊處於更好的遷移位置。
如果你的優先事項是大規模成本效率
絕對現在就建置。 Mythos 預計比 Opus 4.6 更昂貴,且沒有跡象表明推出時會有等效的預算層。如果你在運行高容量工作負載,其中每百萬 Token $5/$25 已需要透過批次處理和提示快取仔細優化,Mythos 在公開可用後也不太可能成為你的預設模型。利用這段時間優化你的 Opus 4.6 工作流程;這些節省是真實的且今天就可用。
值得計算的數學:一個每月在標準 Opus 4.6 上花費 $2,500 的團隊,透過模型混合、批次處理和快取,實際上可以降至約每月 $250。這 90% 的降低在你等待的幾個月裡會顯著複利增長。
如果你的使用案例涉及漏洞研究或安全性
這是等待有意義的唯一情況——但你可能無法選擇。 Mythos 的初始存取群組專注於安全研究人員和防禦者——目標是在模型的攻擊性能力廣泛可用之前準備好防禦。如果你的團隊從事攻擊性安全研究或防禦工具,正確的做法是透過 Anthropic 的管道申請提前存取,同時繼續在 Opus 4.6 上建置。
對於一般企業安全工具(程式碼掃描、合規性、漏洞分類),Opus 4.6 已具備能力且完全可用。Mythos 可能延伸上限,而非下限。
Mythos 不公開可用時該怎麼做
具體來說,以下是如何避免浪費精力同時保持有效率地採用 Mythos 的方法:
設計模型無關的路由。 將你的模型呼叫抽象在路由層後面,這樣將 claude-opus-4-6 換成未來的 claude-capybara-* 模型字串就是配置更改,而非架構重寫。無論 Mythos 如何,這都是良好的實踐——它還讓你今天可以將成本敏感的任務路由到 Sonnet 4.6。
# 範例:模型無關的路由封裝器
import anthropic
MODEL_CONFIG = {
"flagship": "claude-opus-4-6", # Mythos 推出時在此替換
"balanced": "claude-sonnet-4-6",
"fast": "claude-haiku-4-5-20251001"
}
def call_claude(task_tier: str, messages: list, **kwargs):
client = anthropic.Anthropic()
return client.messages.create(
model=MODEL_CONFIG[task_tier],
max_tokens=1024,
messages=messages,
**kwargs
)現在實施提示快取。 根據 Anthropic 的提示快取文件,快取寫入在首次命中時產生 25% 的附加費,然後在後續命中時以 90% 折扣讀取。對於具有重複系統提示或大型上下文塊的代理工作流程,這是目前可用的最高槓桿成本優化——它在 Mythos 上也將以同樣方式運作。
追蹤官方發布節奏。 Anthropic 已確認與提前存取客戶進行測試。Anthropic 使用的分階段推出模式——先是安全合作夥伴,然後是更廣泛的存取——表明一般 API 可用性可能在數週至數月後,而非數天後。
誠實評估你的任務分佈。 如果你 80% 的 API 呼叫是文件摘要、問答或結構化提取,Mythos 在程式碼和網路安全方面的進步可能對你的影響不大。Opus 4.6 在這些工作負載上已經足夠強大。將你的 Mythos 評估保留給你目前達到 Opus 上限的任務。
常見問題
問:我今天可以使用 Claude Mythos 嗎?
不行。截至 2026 年 3 月底,Claude Mythos(Capybara)僅對一小群提前存取客戶開放,特別是那些從事網路防禦應用的客戶。沒有公開 API、沒有文件、也沒有宣布的推出日期。Claude Opus 4.6 可透過 Anthropic API 上的 claude-opus-4-6 存取,仍然是最強的公開可用模型。
問:Opus 4.6 仍然是最好的公開 Claude 模型嗎?
是的。Claude Opus 4.6 和 Sonnet 4.6 仍然是最強大的公開可用 Claude 模型——它們在程式碼、推理和複雜任務方面已經非常強大。Opus 4.6 在代理程式碼的公開排行榜上名列前茅,並在 Anthropic 的平台、AWS Bedrock、Google Vertex AI 和 Microsoft Foundry 上均有完整文件記錄的穩定 API 存取。
問:Claude Mythos 會貴多少?
未知。洩漏的草稿確認該模型「運行成本昂貴」,而位於 Opus 結構上方的新 Capybara 層級暗示高於 Opus 4.6 目前每百萬 Token $5/$25 的價格溢價。沒有發布官方定價。歷史先例顯示 Anthropic 確實在模型世代中降低旗艦定價,因此早期推出定價可能無法反映長期成本。
往期文章:




