Claude Mythos 的網路安全能力:開發者與安全團隊必須了解的重點
Claude Mythos 引發了嚴重的網路安全疑慮。以下說明相關洩露聲稱對正在評估此模型的開發者與安全團隊意味著什麼。

「我們應該擔心這件事嗎?」 這條來自客戶安全團隊的訊息出現在 Slack 上,當時我正在審查內部 AI 工具選項,而 Anthropic 外洩事件的報導 恰好出現在我的動態中。
在 WaveSpeedAI 上即刻可用 — 按 token 透明計費,OpenAI 相容端點。 Claude Opus 4.7 API → · 開啟 Playground →
接下來的 48 小時裡,這個問題不斷被提起。提問者不是 AI 愛好者,而是 CISO、安全主管,以及在 AI 基礎設施上構建系統的開發者——他們突然發現自己身陷一場毫無準備的對話之中。
Mythos 事件不僅僅是一次 AI 產品公告,更是威脅環境走向的訊號。在新模型發布時,釐清哪些是已確認的事實、哪些是推測,比以往任何時候都更加重要。在這篇文章中,我們將一起深入探討這個問題的答案。
外洩草稿揭露了哪些關於 Mythos 網路安全能力的內容
這份外洩的草稿部落格文章——屬於近 3,000 份遭曝光的內部資產之一——包含兩項關於網路安全的驚人聲明,被廣泛引用。Anthropic 在任何公開公告之前撰寫的內部文字,將這款未發布的模型(內部與「Capybara」層級相關聯,稱為 Claude Mythos)描述為「目前在網路能力方面遠超任何其他 AI 模型」。文中進一步警告,該模型「預示著即將到來的一波模型浪潮,這些模型利用漏洞的速度將遠遠超過防禦者的應對能力」。
另一段關鍵文字展現了不尋常的謹慎態度:「在準備發布 Claude Mythos 時,我們希望格外謹慎,並了解它所帶來的風險——甚至超越我們自身測試所能獲取的認知。特別是,我們希望了解該模型在網路安全領域的潛在近期風險,並分享結果以協助網路防禦者做好準備。」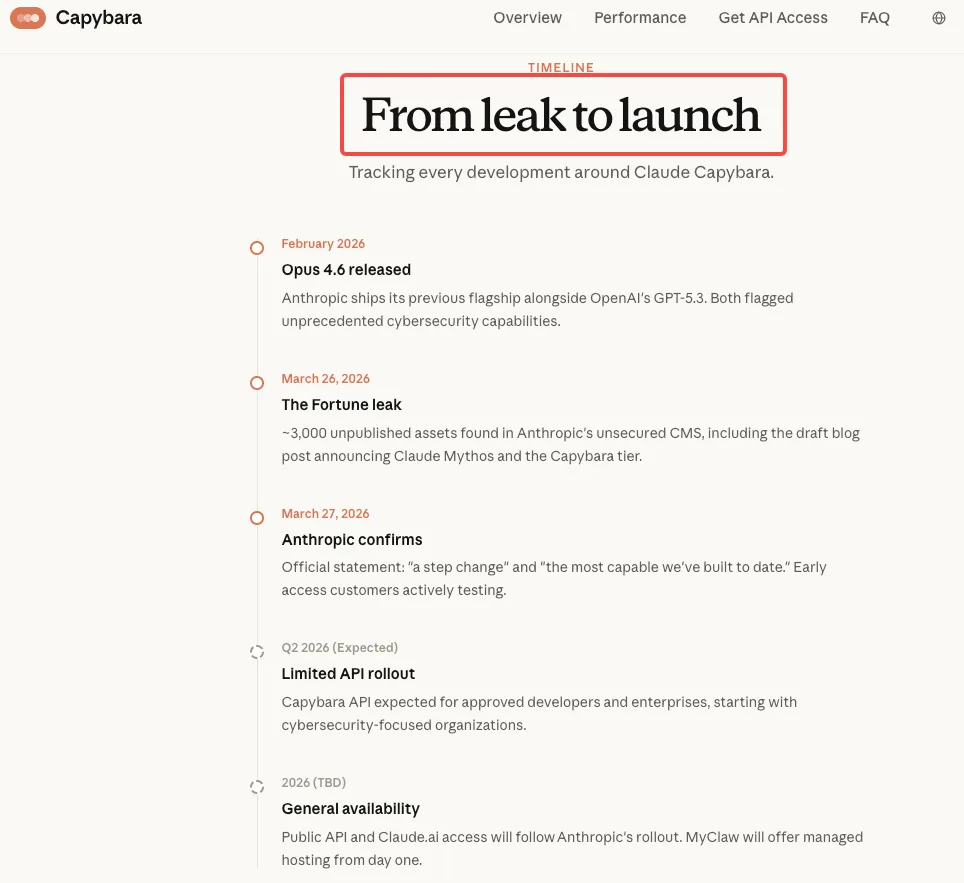
這種表述方式將網路安全風險視為需要主動與防禦者分享的重大外部效應,而非可管理的限制。這與 Anthropic 先前發布版本的立場明顯不同。
外洩內容中缺少什麼?具體的基準數字、漏洞利用類別或詳細方法論。「在網路安全測試中取得顯著更高的分數」代表了已披露能力的全部範圍。網路上流傳的任何更具體的說法都是推測。
為何 Anthropic 將此視為前所未有的風險
「在網路能力方面遠超任何其他 AI 模型」究竟意味著什麼
如果你了解 Opus 4.6——目前的基準——已經具備哪些能力,這個聲明的份量便截然不同。Mythos 並非在超越一個低門檻。
Anthropic 的前沿紅隊使用 Claude Opus 4.6,在生產環境的開源代碼庫中發現並驗證了超過 500 個高嚴重性漏洞——這些錯誤數十年來未被發現,儘管經過多年的專家審查。該團隊未使用任何專業指令或自定義工具,僅依賴模型的開箱即用能力。
一個值得關注的案例:Opus 4.6 在大約 90 分鐘內識別出 Ghost CMS(一個擁有 50,000+ GitHub 星標且此前安全記錄無可挑剔的平台)中的一個盲目 SQL 注入漏洞。
AI 驅動的漏洞發現與傳統模糊測試之間的結構性差異是重要的背景。模糊測試器向代碼輸入數據,直到出現問題。Claude 則對代碼進行推理:跨組件追蹤邏輯、閱讀提交歷史以尋找已修復漏洞的未修補變體,並評估哪些代碼路徑存在固有風險,而非研究每個可能的輸入。根據 Anthropic 自己的內部評估,Mythos 在這方面的表現優於目前所有其他可用工具——且差距顯著。
防禦者差距問題:為何攻擊可能超越防禦
草稿最重要的洞察並非列舉新的攻擊類型,而是闡明攻擊者與防禦者之間的不對稱性為何存在。攻擊者只需找到一個弱點,防禦者卻需要覆蓋所有環節。一個能夠對代碼進行推理、識別潛在漏洞模式並協助優化漏洞利用的 AI 模型,將壓縮從「構想」到「有效攻擊」的時間。
據報導,Anthropic 已警告政府高層官員,Mythos 可能透過啟用高度複雜的自主代理,使 2026 年大規模網路攻擊的可能性增加。Dark Reading 於 2026 年初進行的一項調查發現,48% 的網路安全專業人員現在將代理型 AI 列為本年度首要攻擊媒介——超過深度偽造和社會工程攻擊。
這不是 Mythos 從零創造的問題,而是一種加速器。對手已毫不猶豫地使用 AI,且不受合規限制。自我限制使用前沿模型的防禦者,有可能在關鍵領域拱手相讓。
防禦性與攻擊性應用:界線在哪裡
合法使用案例:漏洞掃描、紅隊測試、代碼加固
Mythos 能力的防禦性應用確實意義重大——這也是 Anthropic 首要構建並發布它的原因。
Claude Code Security——內建於 Claude Code 的新能力——可掃描代碼庫中的安全漏洞,並為人工審查提出針對性的軟件修補建議,幫助團隊發現傳統方法常常遺漏的安全問題。任何操作均不在未經人工批准的情況下執行:Claude Code Security 識別問題並提出解決方案,但最終決定始終由開發者做出。
將 Mythos 層級的能力應用於這一工作流程,意味著能夠發現即使 Opus 4.6 也可能遺漏的漏洞類別——業務邏輯中依賴上下文的缺陷、多組件交互模式,以及需要理解系統架構而非代碼模式的身份驗證繞過。對於目前按季度安排人工滲透測試的安全團隊而言,以 Mythos 級別推理品質進行 AI 驅動的持續掃描,代表著在運營可行性方面的實質性轉變。
對於紅隊來說,同樣的能力需要嚴格的範圍界定和授權。模型本身無法區分授權測試和惡意使用——這個責任始終由你的流程和護欄來承擔。
Anthropic 正在採取哪些措施限制濫用
在 Opus 4.6 的同期,Anthropic 部署了激活層級探針,以實時偵測和阻止網路濫用,並承認這可能對合法安全研究造成摩擦。「這將為合法研究和部分防禦工作帶來摩擦,我們希望與安全研究社群合作,找到解決方案,」該公司警告道。
針對 Mythos,管控措施在結構上而非僅在技術上有所不同。根據外洩文件和 Anthropic 的公開聲明,初期訪問限於經過審查的安全研究人員和防禦者——目標是在攻擊性能力廣泛普及之前構建防禦工具。這與 Anthropic 處理先前高風險版本的方式相呼應,也與 NIST AI 風險管理框架所建議的實踐一致,該框架倡導對雙重用途 AI 系統進行分階段部署並持續監控。
對於任何試圖建立威脅面模型的安全團隊,MITRE ATT&CK 框架中的對抗性 AI 戰術部分值得深入研究。其中記錄的戰術假設模型能力遠低於 Mythos 所代表的水準。
早期訪問安全客戶正在評估什麼
外洩草稿明確說明了 Anthropic 的推廣優先順序:「我們將在未來幾週內緩慢擴大 Claude Mythos 的訪問範圍,開放給更多使用 Claude API 的客戶。由於我們對網路安全用途特別感興趣,這將是我們優先擴大早期訪問計劃的領域。」
早期訪問群體正在針對模型設計要解決的具體問題評估 Mythos:比現有工具更快、更全面地在已加固的生產代碼庫中發現漏洞。分析師指出,它可能從兩個方向壓縮攻防差距——加速漏洞發現、持續紅隊測試和威脅獵取,同時若遭濫用,也會降低發動複雜攻擊的門檻。
對於目前處於評估期的安全客戶,實際問題集中在三個方面:Mythos 如何與現有的 SIEM 和漏洞管理工作流程整合,模型的發現結果是否能以與現有工單系統兼容的格式呈現,以及大規模部署時人工審查的要求是什麼。
在對 40 多位跨行業 CISO 的訪談中,VentureBeat 發現,針對基於推理的掃描工具的正式治理框架是例外而非常態。最常見的回應是,這個領域被認為如此新興,以至於許多 CISO 認為這種能力不會在 2026 年初就到來。參與早期訪問計劃的團隊,實際上正在撰寫整個行業將會遵循的治理規範。
對在 AI 基礎設施上構建系統的開發團隊的影響
如果你的團隊正在 Claude 或任何前沿 AI 模型之上構建產品,Mythos 事件帶來了兩個截然不同的擔憂類別。
第一個是直接的:你是 AI 輔助攻擊的潛在目標,而這些攻擊正變得越來越強大。
第二個擔憂在於架構層面:你的 AI 基礎設施如何防範提示注入、未授權工具訪問和代理濫用。組織需要將每個代理、機器人和 AI 服務視為一個身份,對非人類身份採用與人類用戶相同程度的管控、權限和監督——要求清點訪問權限,並消除會形成不安全機器人的硬編碼憑證。
在實踐中,這對於今天在 Claude 上構建系統的團隊意味著以下幾點:
嚴格限制 MCP 伺服器訪問範圍。 你連接到 Claude 代理的每個 MCP 伺服器都是潛在的攻擊面。使 Claude Code 強大的擴展代理能力,同樣使範圍界定不當的代理權限成為重大風險媒介。
將 CLAUDE.md 視為安全文件。 CLAUDE.md 中定義代理可使用哪些工具、可讀取哪些文件以及可執行哪些操作的指令,是安全控制措施,而非僅僅是生產力輔助工具。一份授予廣泛文件訪問或工具權限的 CLAUDE.md 會放大風險。
對 AI 生成的修補程式,而非僅對 AI 生成的代碼進行人工審查。 AI 生成的代碼引入 XSS 漏洞的可能性是人工編寫代碼的 2.74 倍,引入不安全對象引用的可能性是人工編寫代碼的 1.91 倍。發現漏洞的相同推理能力,也可能引入漏洞。對安全相關變更進行人工審查不是可選項。
常見問題
安全團隊現在可以訪問 Claude Mythos 嗎?
目前沒有任何公開管道可以訪問。該模型的推廣計劃反映了網路安全方面的擔憂:早期訪問僅限於經過審查的防禦性網路安全組織。對於希望提前準備的安全團隊,Claude Code Security——基於 Opus 4.6,目前以有限研究預覽版向 Enterprise 和 Team 客戶開放——是最接近公開可訪問的工具,也是了解 Mythos 層級能力將如何延伸的有用基準。
Anthropic 正在構建哪些保護措施?
已確認的措施包括實時濫用偵測探針、優先考慮防禦者的分階段推廣,以及修補程式的人機協作要求。對於 Mythos,重點在於部署治理、工具邊界和審計追蹤。
Claude Mythos 是否會用於商業紅隊測試?
尚未確認。早期訪問群體專注於防禦性安全用例。商業紅隊測試——組織雇用安全公司主動探測其系統——處於一個模糊地帶:這是授權的攻擊性行為。鑑於公司對攻擊性濫用的明確擔憂,預計紅隊測試用例將受到嚴格訪問控制,而非開放的 API 訪問。
相關文章:
