Claude Code Agent Harness:架構解析
深入解析 Claude Code 如何串接工具、管理權限並協調 Agent 會話——為開發者提供的技術剖析。

在建構自己的工具呼叫系統時,我一再遇到同一個問題:為什麼接線感覺比提示詞難這麼多?
模型的部分很快就上手了。但當我需要它實際做事情——讀取檔案、執行 shell 指令、與外部服務溝通——每個決策都感覺可能出錯。權限邊界、上下文限制、工具調度。
然後,在 2026 年 3 月下旬,Claude Code 的原始碼因 2.1.88 版本的 npm source map 意外洩露。超過 50 萬行 TypeScript,幾小時內就被鏡像備份。Anthropic 確認這是打包錯誤——沒有涉及客戶資料——並開始發出 DMCA 下架通知。
但架構已成為公開知識。而它揭示的不是模型,是 harness。
關於來源的說明:此處的細節來自社群分析、開源復現,以及 Anthropic 的公開文件和工程部落格——並非洩露的程式碼本身。不確定的細節會特別標注。
什麼是 Agent Harness?
定義及其在 Agentic 系統中的角色
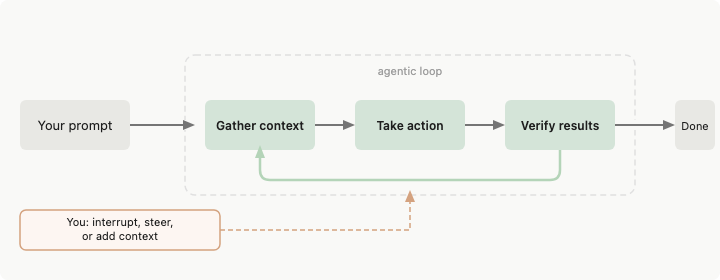
Agent harness 是語言模型與現實世界之間的一切。模型產生文字,harness 決定那些文字能觸碰什麼。
Anthropic 的 Claude Code 文件直接描述了這一點:Claude Code「提供工具、上下文管理,以及將語言模型轉變為強大程式碼代理的執行環境。」模型負責推理,harness 負責行動。
當你的 agent 讀取檔案時,harness 決定是否允許讀取、如何處理結果,以及有多少回應能放入下一個提示詞。模型永遠不會直接接觸檔案系統。
為什麼 Harness 設計對生產環境至關重要
大多數 agent 示範都跳過這個部分。你看到模型呼叫函數、取得結果、再呼叫另一個。看起來很乾淨。然後你在真實的程式碼庫上跑了 45 分鐘,事情悄悄地崩潰了——上下文溢位、權限太寬鬆或太煩人、工具結果被截斷但模型毫不知情。
Anthropic 工程團隊曾撰文討論此事:即使是在多個上下文視窗的迴圈中運行的前沿模型,若沒有設計良好的 harness,也會表現不佳。Agent 試圖一次做太多事,或過早宣告任務完成。Harness 對這種傾向施加結構。

Claude Code 的工具介面
核心工具類別
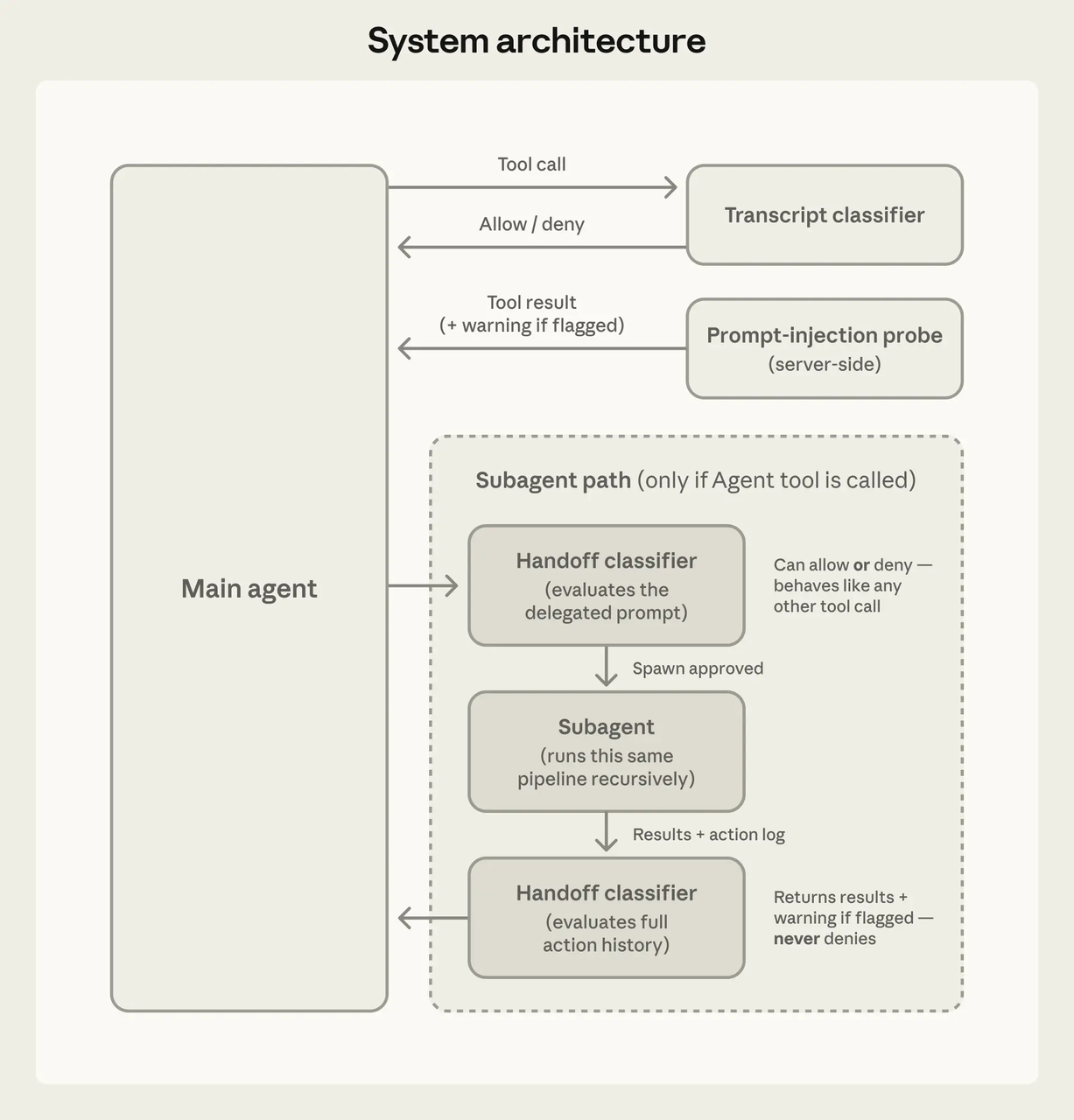
根據官方 Claude Code 文件和公開分析,Claude Code 公開了大約 19 個需要權限控管的工具。主要類別包括:檔案讀取與編輯、shell 執行(Bash)、Git 操作、網頁抓取、Notebook 編輯,以及 MCP 工具呼叫。社群分析指出,若加上 LSP 整合、子代理生成和內部協調工具,數量可能接近 40 個。
每個工具都是獨立沙箱化的。並非「agent 擁有檔案系統存取權」——而是「agent 可以使用 Read 工具,而 Read 有自己的權限閘道,在任何執行前都會檢查規則管道。」
工具的註冊與調度方式
模型決定要嘗試什麼,工具系統決定什麼被允許,兩者在架構上是分離的。
每次工具呼叫在執行前都會通過權限檢查。社群深度分析描述了一個核心函數,按照拒絕/詢問/允許的順序評估規則——拒絕永遠優先。有三種可能的結果:靜默執行、提示用戶,或阻擋。
被入侵的模型無法透過說服來繞過安全檢查。Harness 不在乎模型的論點,規則就是規則。
權限層級
Claude Code 的權限模型被多位社群分析師描述為大致三個層級:
第一層——自動核准:唯讀或本質上安全的操作。檔案讀取、文字搜索、程式碼導航。這些不會改變狀態,因此無需中斷即可執行。
第二層——提示確認:以受控方式修改狀態的操作。檔案編輯、某些 shell 指令。在自動模式下(2026 年 3 月引入),運行在 Sonnet 4.6 上的後台分類器會評估這些操作是否可以不詢問就執行。分類器能看到用戶的請求和工具呼叫,但看不到模型的散文輸出——這是刻意的設計選擇,防止模型用甜言蜜語通過閘道。
 第三層——需要明確批准或阻擋:高風險操作。可能以不可預測方式修改系統狀態的 shell 指令、工作目錄以外的操作、任何看起來像資料外洩的操作。
第三層——需要明確批准或阻擋:高風險操作。可能以不可預測方式修改系統狀態的 shell 指令、工作目錄以外的操作、任何看起來像資料外洩的操作。
一個注意事項:三層架構的框架來自社群分析,並非 Anthropic 的官方文件。官方系統使用允許/詢問/拒絕規則和六種權限模式(default、acceptEdits、plan、auto、dontAsk、bypassPermissions)。「三層」是個有用的心智模型,但只是一種簡化。
會話與上下文管理
Claude Code 如何追蹤會話狀態
Claude Code 在一個會話中累積上下文——讀取的檔案、執行的指令、grep 結果、diff、錯誤輸出。這一切都堆疊進一個不斷增長的提示詞。與聊天介面中每條訊息相對獨立不同,Claude Code 的會話是持續的工作記憶。
會話儲存在本地。每條訊息、工具使用和結果都被存儲,支援回放、恢復和分支。在程式碼變更之前,harness 會快照受影響的檔案,以便你可以還原。
輸出截斷與 Token 成本處理
大型工具輸出是個真實問題。Claude Code 為 MCP 工具輸出設定了預設最大值 25,000 個 token,並在 10,000 個 token 時發出警告。伺服器作者可以為工具標注允許更大的結果(最多 500,000 個字元),這些結果會持久化到磁碟而非保留在上下文中。
這是那種你不會想到的事情,直到你的 agent 因工具結果被截斷而悄悄丟失追蹤資訊。明確的、可配置的限制加上基於磁碟的備援——值得借鑒。
壓縮行為
這個問題在我理解之前就困擾了我。當 token 使用量達到上下文視窗的約 98% 時,Claude Code 會自動壓縮:它會摘要早期歷史以釋放空間。關鍵元資料被保留,圖片和 PDF 會被移除。
棘手之處在於:壓縮可能丟失重要細節。實際的解決方法是:將所有關鍵內容放在 CLAUDE.md 中,harness 會在每次輪次重新讀取它。
Anthropic 的harness 設計研究發現,對於延伸會話,完整的上下文重置——新的 agent 實例從交接工件中接手——有時比壓縮效果更好。雖然增加了更多的編排複雜性,但上下文保真度更好。
MCP 整合層
Claude Code 如何連接到 MCP 伺服器
 MCP(模型上下文協定) 是將 AI 工具連接到外部服務的開放標準。Claude Code 支援三種傳輸模式:HTTP(推薦用於遠端伺服器)、stdio(用於本地程序)和 SSE。
MCP(模型上下文協定) 是將 AI 工具連接到外部服務的開放標準。Claude Code 支援三種傳輸模式:HTTP(推薦用於遠端伺服器)、stdio(用於本地程序)和 SSE。
新增伺服器只需一個指令:claude mcp add server-name --transport http "URL"。之後,伺服器的工具會作為可呼叫工具出現在會話中,受到與內建工具相同的權限管道約束。
工具發現與驗證流程
有一個細節讓我印象深刻:工具搜索。當你連接 MCP 伺服器時,Claude Code 不會在啟動時將所有工具結構定義載入到上下文中。它在會話開始時只載入工具名稱,然後在任務實際需要時使用搜索機制來發現相關工具。只有 Claude 使用的工具才會進入上下文。
這使 MCP 的開銷保持在低水準。驗證流程取決於伺服器——OAuth、API 金鑰、標頭。Claude Code 要求用戶明確批准新的 MCP 伺服器。
什麼已可用於生產,什麼仍在演進
MCP 整合功能完善且被積極使用。但有幾個值得了解的實際限制:
建議的上限約為 5–6 個活躍 MCP 伺服器,因為每個都會啟動一個子程序。工具搜索有助於降低上下文開銷,但超過這個數量後延遲仍會增加。
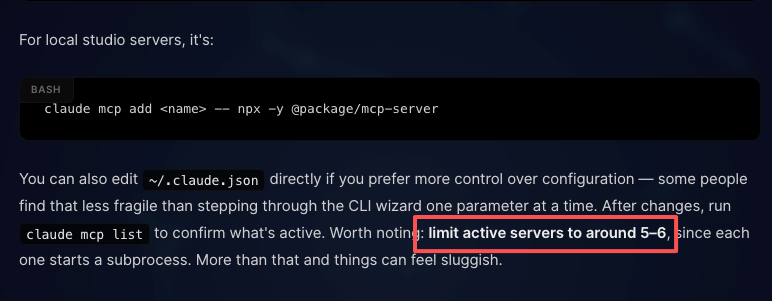 大型 MCP 回應需要謹慎處理。 25K token 的預設限制對大多數使用案例有效,但對資料庫結構定義來說會很緊張。持久化到磁碟的備援有所幫助,但模型在上下文中只能獲得一個引用而非完整結果。
大型 MCP 回應需要謹慎處理。 25K token 的預設限制對大多數使用案例有效,但對資料庫結構定義來說會很緊張。持久化到磁碟的備援有所幫助,但模型在上下文中只能獲得一個引用而非完整結果。
而且社群構建的 MCP 伺服器品質參差不齊。Anthropic 的文件明確指出,第三方伺服器可能是提示詞注入的載體。權限系統有所幫助,但信任仍然是你的責任。
給構建者的啟示
這個架構揭示了關於生產級 Agentic 系統的什麼
Claude Code 設計中的幾個模式,我認為具有普遍適用性:
將推理與權限執行分離。 模型決定它想做什麼,另一個系統決定是否允許。被入侵的模型無法覆蓋安全檢查,因為它字面上是不同的程式碼路徑。
讓上下文管理顯式化。 壓縮、截斷限制、工具搜索、磁碟持久化——這些都是主動管理模型所見內容的機制。大多數業餘 agent 構建把上下文當作無底洞,但它不是。
為會話持續性設計。 快照、可還原的檔案變更、CLAUDE.md 作為持久錨點。長時間運行的 agent 需要能在上下文壓縮中存活的記憶。
權限的細粒度有其回報。 按工具、按模式、按目錄的規則,加上拒絕優先的評估。比起「允許一切」的開關,這需要更多工作,但這是示範和可部署系統之間的差距所在。
何時自建 Harness vs. 使用託管層
狹窄、定義明確的任務——例如運行測試並發布結果的 CI 機器人——你可以自己接一個最小化的 harness。幾個工具、一個簡單的權限檢查、一個固定的上下文視窗。
延伸會話、跨上下文重置的狀態、不受信任的工具輸出、數十個工具——基於現有的 harness 構建或仔細研究一個。Claude Agent SDK、OpenAI 的 Codex 架構、LangGraph 都已解決了你最終會遇到的問題。
大多數團隊低估了 harness 的複雜性。我當然也這樣。模型才是簡單的部分。
常見問題
Claude Code 的 agent harness 是什麼?
Claude 模型與現實世界之間的基礎設施層——工具調度、權限、上下文管理、會話狀態、MCP 連接。Anthropic 將其描述為「將語言模型轉變為強大程式碼代理」的東西。
Claude Code 如何處理工具權限?
基於規則的管道評估每次工具呼叫:允許、詢問或拒絕,且拒絕永遠優先。在自動模式下,一個獨立模型實例上的後台分類器評估模糊案例——且刻意不查看 agent 的散文輸出,以防止提示詞注入。
Claude Code 的 MCP 整合適合生產環境嗎?
功能完善且被積極使用,但在伺服器數量、回應大小和第三方信任方面有實際限制。它正在快速演進。
我可以使用相同的模式構建自己的 harness 嗎?
可以。Claude Agent SDK 公開了相同的權限模式、鉤子和上下文管理。像 Everything Claude Code 這樣的社群專案也記錄了可重用的模式。
規範相容性和行為相容性有什麼區別?
規範相容性意味著支援相同的工具和配置。行為相容性意味著以相同方式處理邊緣案例——壓縮丟棄了一條關鍵規則、工具返回了 100K token、模型試圖繞過權限。匹配規範很直接,匹配行為需要幾個月的時間。
有一件事一直縈繞著我:harness 才是難的部分。每個人都假設模型是競爭優勢。確實如此——直到你嘗試讓它可靠地做事超過五分鐘。那才是工程的所在。
前幾篇文章:




