What Is Fugu Ultra? Sakana AI's Multi-Agent API
Learn how Fugu Ultra coordinates expert agents behind one API endpoint, where it fits production work, and its observability limits.
I’ve spent the last few days reading every page Sakana has published about Fugu Ultra, plus the technical report and early developer reactions. This is what I’d want a colleague to read before they brought it into a sprint planning conversation.
Short version: Fugu Ultra is not another frontier model. It’s a small coordinator model that calls other frontier models on your behalf. That distinction changes most of what you’d assume about how to evaluate it.
This piece sticks to the architecture question. API code, billing fields, and exact pricing live in a separate guide.
What Is Fugu Ultra?

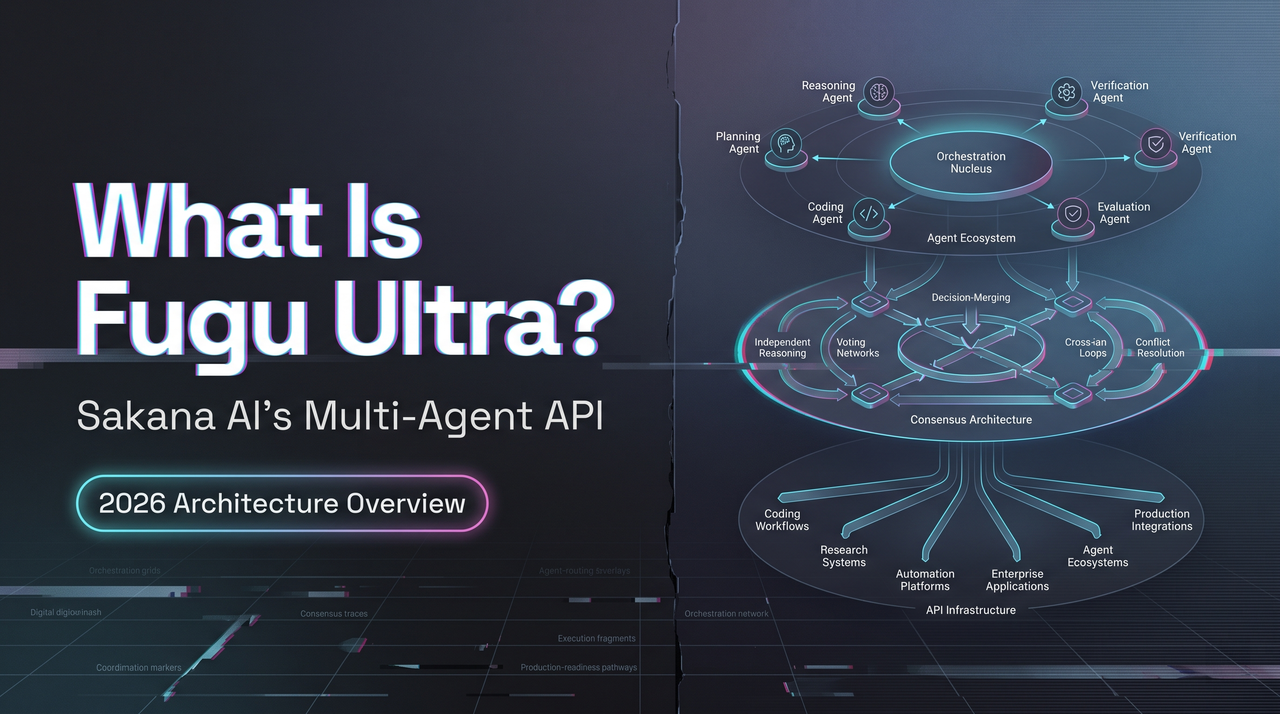
A multi-agent system presented as one model endpoint
Sakana AI launched Fugu and Fugu Ultra on June 22, 2026 as part of Sakana Fugu. From the caller’s perspective it looks like a normal model endpoint. One request, one answer, OpenAI-compatible API.
Underneath, something different is happening. Fugu Ultra is itself an LLM — reportedly around 7 billion parameters — but it’s not trained to answer your prompt directly. It’s trained to coordinate other models. When a request arrives, Fugu Ultra decides which expert models in its pool should handle which parts of the task, has them work, verifies their output, and synthesizes a final answer.
The multi-agent machinery doesn’t reach your code. It also doesn’t reach your logs in any granular way.
How it differs from a conventional foundation model
A conventional foundation model is one set of weights producing one stream of tokens. You know what model answered. You can pin a version. You can reproduce outputs.
Fugu Ultra is structurally different:
- It doesn’t generate the answer itself. It generates a coordination plan, delegates, and returns synthesized work.
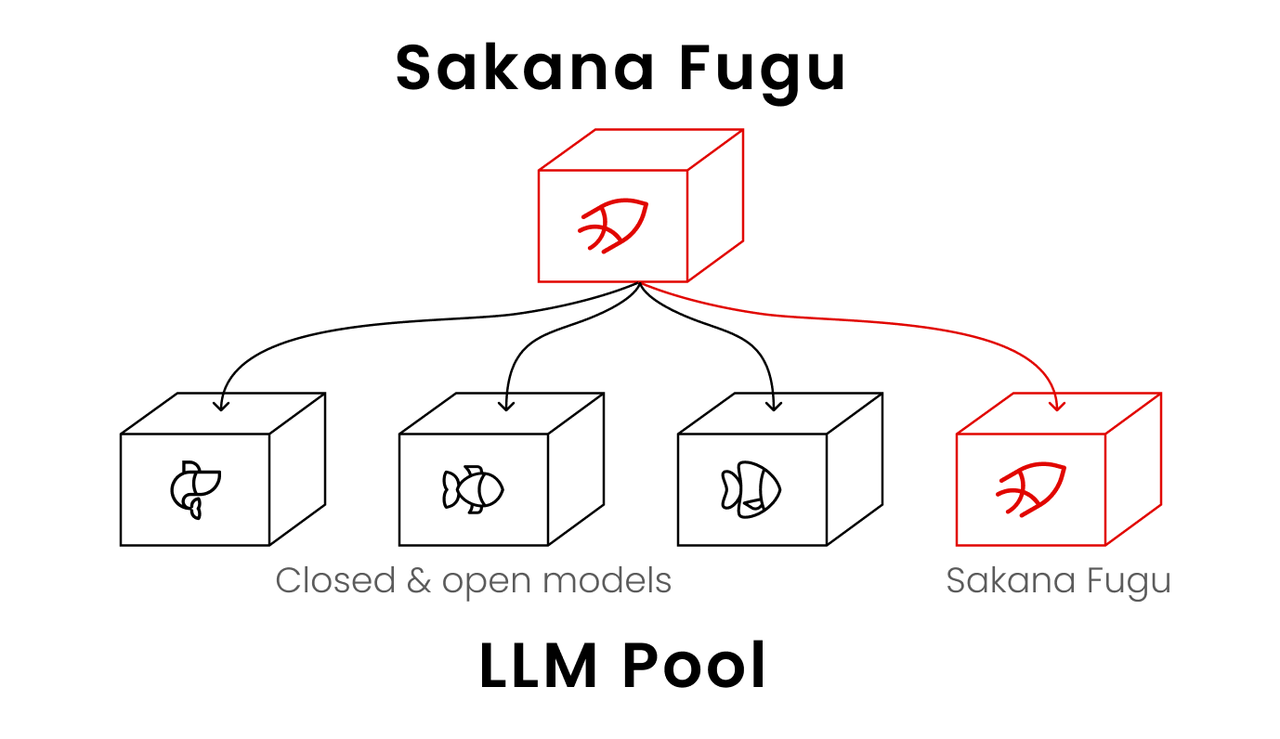
- Its capability comes from the pool, not its own weights. When a new frontier model lands, Sakana can add it and retrain the coordinator. Your “model” gets better without you doing anything — and without your knowledge.
- It hides per-query routing by design. Not “undocumented.” Deliberately hidden.
- It runs on third-party models. GPT 5.5, Claude Opus 4.8, and Gemini 3.1 Pro have all been named in independent reporting as agents in the pool.
The right frame is not “is Fugu Ultra better than Claude,” but “is a learned coordinator over multiple frontier models better than picking one frontier model yourself for your specific workload.”
How Fugu Ultra Routes Complex Work
A trained orchestrator over a pool of third-party models
The coordination logic isn’t a rules engine or a semantic classifier. It’s a learned model, grounded in two ICLR 2026 papers from Sakana — TRINITY (Thinker/Worker/Verifier roles) and the Conductor (RL-trained agent communication). The Fugu GitHub repo walks through both.
Practically: Fugu Ultra doesn’t follow a fixed playbook like “if it’s code, send to GPT.” It’s learned through training when to delegate, to whom, and how to combine outputs. The routing isn’t auditable the way a hand-written router would be. Sakana has been explicit about this — per-query model selection stays hidden.
One-to-three-agent routing by task
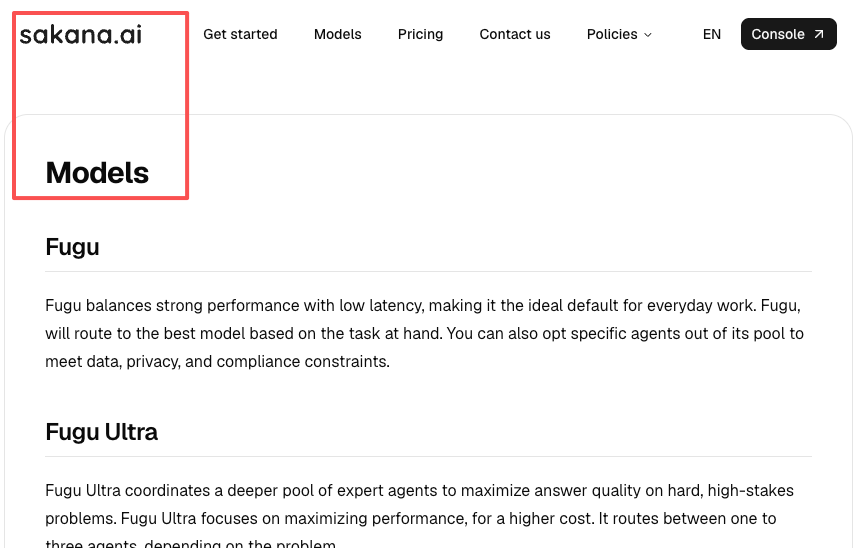
Per Sakana’s models documentation, Fugu Ultra “routes between one to three agents, depending on the problem.” Light reasoning may stay in the coordinator. Hard problems fan out across the pool and come back through a verification and synthesis pass.
Two consequences:
- On easy prompts, Fugu Ultra behaves a lot like a single model. Orchestration overhead is real but small.
- On hard prompts, you’re paying for several models to talk to each other before any user-visible output appears. Latency variance is wide — early reports showed individual requests ranging from ~11 seconds to over four minutes.
Fugu Ultra doesn’t auto-select between itself and the base Fugu tier — the caller does. Wire Ultra into everything and you’ll pay for multi-agent reasoning on prompts a 7B model would have handled alone.
Where Fugu Ultra Fits Best
Research, coding, engineering analysis, and long-chain tasks
Workloads where I’d reach for Fugu Ultra share a few traits: the task is hard enough that any single model has known weak spots, answer quality matters more than latency, and the workflow can absorb wide latency.
Concretely:
- Multi-step coding work — large diffs, multi-file refactors, code review where you’d want a second opinion.
- Research and paper reproduction — long reasoning chains where verification is genuinely useful, not theater.
- Engineering and scientific analysis — patent investigation, deep document review, anything where you’d otherwise run the same prompt against two models and compare.
- Security audits — Sakana’s own framing leans here, and Thinker/Worker/Verifier maps cleanly onto adversarial review.
- Pipelines where vendor lock-in is a stated risk — an orchestration layer is a structural fit, not just a feature.
The pattern: tasks where you were already going to invoke multiple models. Fugu Ultra collapses that into one call.
Where Fugu Ultra Is a Poor Fit
Low-latency interactions, simple prompts, and predictable-cost workloads
Three categories where I wouldn’t reach for it:
- Anything interactive with a tight latency budget. Chat UIs, autocomplete, anything a user is staring at. Latency variance up to several minutes is a UX failure for typing-speed interaction.
- Simple prompts a smaller model handles fine. Classification, extraction, short Q&A. Orchestration tokens get billed at full rates regardless of how trivial the surface answer was.
- Workloads where cost predictability is the actual requirement. Two functionally identical requests can produce different bills, because the coordinator decides at runtime how much orchestration to do.
A subtler poor fit: anything that has to be audited to a specific model. If your compliance posture requires “this output came from model X, version Y,” Fugu Ultra structurally can’t give you that answer.
Some workloads need a known model. Some workloads need a good answer however it got there. Don’t confuse the two.
Production Implications
Latency, routing risk, and the model-selection visibility gap
Three operational realities before letting Fugu Ultra into production:
Latency is wide and not under your control. The coordinator decides how much orchestration to do per request. Plan for tail latency, not average.
Routing risk is real. Fugu Ultra depends on third-party providers. If one provider has an incident, Fugu can route around it — but if Sakana itself has an incident, you have no router. Keep a direct-to-provider fallback.
Per-request model attribution is unavailable. You won’t know which model produced any output. Fine for internal R&D. For regulated workflows or post-incident root-cause analysis, this gap matters. Decide before you wire it in.
Fixed Ultra pool vs opt-out controls on the base tier
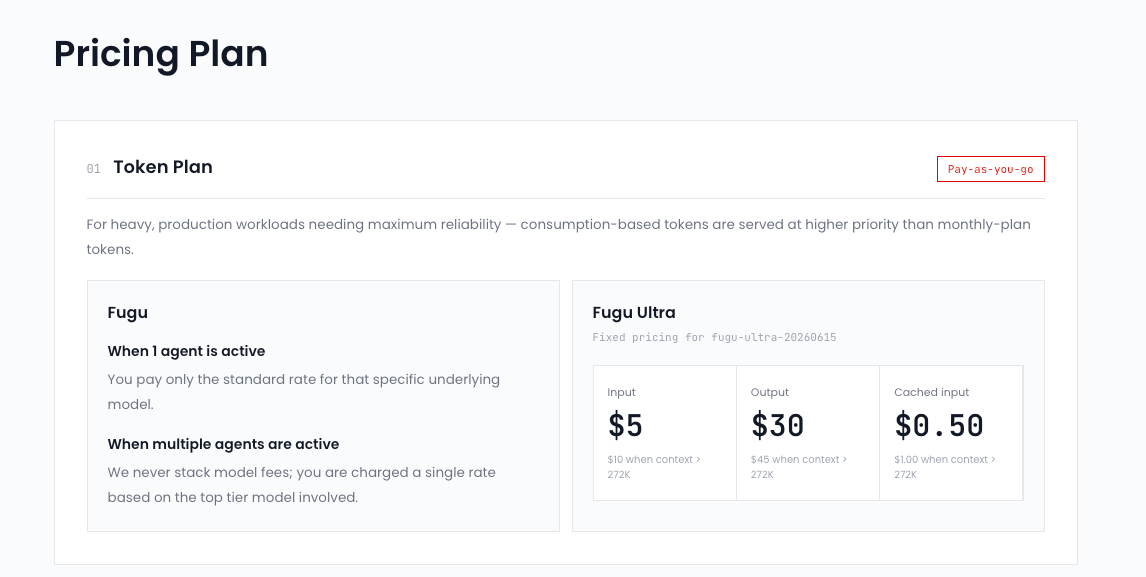
A detail that directly affects compliance review, per Sakana’s product page:
- Fugu (base tier) lets you opt specific agents or providers out of its pool.
- Fugu Ultra uses a fixed agent pool with no opt-out. Accept the full pool or don’t use Ultra.
If your compliance team would block any underlying provider, Fugu Ultra is a non-starter regardless of how well it benchmarks. The base tier may still be viable. Same goes for regional availability — Fugu is currently unavailable in the EU/EEA pending GDPR work.
FAQ
Can Fugu Ultra replace a single-model endpoint directly?
At the API surface, yes — it’s OpenAI-compatible. Architecturally, it’s a different category of thing. You’re trading a known model for a coordinator over a pool. Whether that swap is net positive depends on whether your workload benefits from multi-model reasoning and whether you can absorb the latency and attribution trade-offs.
Why can teams not see which model answered each request?
Sakana states the routing is proprietary. The coordinator’s per-query decisions are intentionally hidden. The product position is that you’re buying the result of orchestration, not the orchestration itself. It’s a design choice, not an oversight, and unlikely to change.
When does multi-agent reasoning add needless overhead?
When the task is small enough that any single competent model would handle it on the first try. The honest test: if you wouldn’t manually run this prompt through two models and compare, you probably don’t need an orchestrator for it.
What regional or provider controls matter before adoption?
Three to check. Regional availability — Fugu is not yet available in the EU/EEA pending GDPR work. The fixed Ultra pool — if any underlying provider fails your compliance review, Ultra is out. Data handling — review Sakana’s current policy in the console directly, since this gets updated.
Conclusion
Fugu Ultra is best understood as a learned coordinator over a pool of frontier models, served behind a single API. Not a bigger model. A different shape of product.
That shape fits some workloads cleanly — hard, multi-step tasks where quality matters more than latency. It fits others badly — interactive UX, simple prompts, anything requiring per-output attribution.
Evaluate it on the specific workload, not on Sakana’s benchmark table. Run your own evals against the tasks you actually run.
More to come once I’ve put it through a real workload for a few weeks.
Previous posts: