如何使用OpenRouter设置G0DM0D3:分步指南(2026)
2026年使用OpenRouter API密钥设置G0DM0D3的分步指南。三种部署选项:本地、静态托管或Docker API服务器。

嘿,大家好,我是 Dora。你知道吗,我曾经数过自己在对比模型输出时开了多少个浏览器标签页?七个。四个不同的聊天界面、两个 API 沙盒,还有一个用来追踪各模型回答的电子表格。G0DM0D3 就是为了消除这种摩擦而生的 —— 一个 HTML 文件,50+ 个模型并行执行同一提示词,自动评分排名。
本文记录了如何让 G0DM0D3 运行起来,从零开始直到完成你的第一次多模型评估。四种部署方式,各适用于不同场景。我还会介绍费用估算,因为同时运行 55 个模型并非免费,没人应该在 OpenRouter 账单上才发现这一点。
开始之前:你需要什么
OpenRouter 账户和 API 密钥(免费注册,按量付费)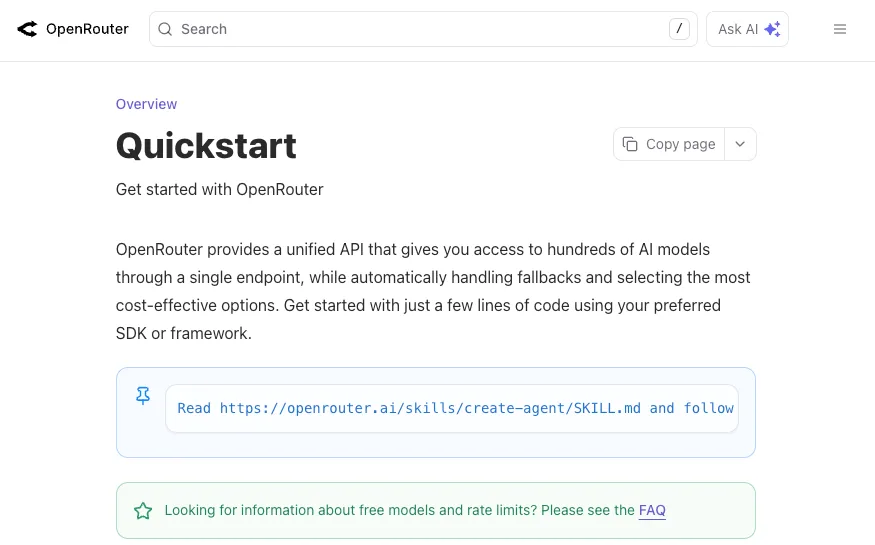
G0DM0D3 通过 OpenRouter 路由所有模型调用,这是一个统一的 API 网关,覆盖 Anthropic、OpenAI、Google、Meta、Mistral 等 300+ 个模型。一个 API 密钥,一个计费账户,所有模型一网打尽。
在 openrouter.ai 注册,进入 Keys,创建一个密钥并复制。这是 G0DM0D3 唯一需要的凭证。新账户会获得少量免费额度 —— 足够运行 GODMODE CLASSIC,但不够完整的 ULTRAPLINIAN 运行。费用详情后面会说。
浏览器(用于本地/托管版)或 Node.js 18+(用于 API 服务器)
核心应用是一个单独的 index.html 文件。只要能打开浏览器,你就能运行 G0DM0D3。无需 npm install,无需构建步骤,无需框架。api/ 目录中的可选 API 服务器需要 Node.js 18+ 或 Docker —— 但大多数人用不到它。
了解 G0DM0D3 能做什么、不能做什么
G0DM0D3 是一个多模型评估和红队测试工具,而不是 ChatGPT 的替代品。它并行运行模型,对输出按 100 分制综合评分,并告诉你哪个模型在你的特定提示词上表现最佳。
它不做的事情:跨会话持久化对话、管理账户或在服务器端存储任何内容。聊天记录存在 localStorage 中。清除浏览器数据,记录就消失了。
方式一 —— 托管版(零安装)
最快的路径。无需下载,无需终端,无需配置。
访问 godmod3.ai
在浏览器中打开 godmod3.ai。完整应用从单个静态文件加载。安装就到此为止。
在设置中粘贴你的 OpenRouter API 密钥
点击设置图标,粘贴你的 OpenRouter API 密钥。密钥存储在 localStorage 中 —— 永远不会离开你的机器,永远不会触及 G0DM0D3 的服务器。每次 API 调用都直接从你的浏览器发送到 OpenRouter。这一点可以验证,因为完整源代码在 GitHub 上公开。
选择模式(GODMODE CLASSIC 还是 ULTRAPLINIAN)
GODMODE CLASSIC 并行运行 五个预配置的模型+提示词组合。速度快、费用低,适合快速对比。ULTRAPLINIAN 是旗舰功能 —— 它跨五个层级查询 10 到 55 个模型,对每个响应评分,并返回带综合分数的优胜者。建议先用 CLASSIC 确认密钥可用,再扩大规模。
关于托管版的数据处理须知
godmod3.ai 上的托管版会收集匿名操作元数据 —— 调用了哪个端点、响应时长、成功或失败。不包含消息内容、提示词或 API 密钥。这在项目的 GitHub 上的 TERMS.md 中有说明。如果这种元数据收集对你很重要,请改用自托管。
方式二 —— 本地单文件部署
适合希望 API 密钥和提示词完全留在自己机器上的用户。两条命令搞定。
克隆仓库
git clone https://github.com/elder-plinius/G0DM0D3.git
cd G0DM0D3本地启动服务
python3 -m http.server 8000这就是全部设置。无需安装依赖。这一行 Python 命令在 8000 端口提供目录服务。
打开 http://localhost:8000,在设置中添加 API 密钥
流程与托管版相同 —— 在浏览器中打开,将 OpenRouter 密钥粘贴到设置中,选择模式。区别在于:所有内容都从你的文件系统运行。此配置下没有外部服务器接收元数据,因为根本没有外部服务器。
清除浏览器数据前请导出聊天记录
这是没人在踩坑前会认真阅读的警告。G0DM0D3 将聊天记录存储在 localStorage 中。如果你清除浏览器数据 —— 或切换浏览器,或打开隐身窗口 —— 记录就永远消失了。没有云同步,没有备份,界面上也没有导出按钮。如果你需要保留评估会话的记录,在关闭标签页之前手动复制输出内容。把每次会话都视为临时性的。
方式三 —— 静态托管(Vercel / GitHub Pages / Cloudflare Pages)
适合团队共享访问、每人使用自己 OpenRouter 密钥的场景。
将 index.html 作为根资产上传
将 index.html 推送到 GitHub 仓库并启用 Pages,或拖入 Vercel,或推送到 Cloudflare Pages。零服务端依赖 —— 所有 API 调用都源自访问者的浏览器。
无需构建步骤,无需环境变量
托管端无需任何配置。没有构建命令,没有环境变量。每个用户在客户端粘贴自己的 OpenRouter API 密钥。
自定义域名和 HTTPS 设置
任何静态托管服务的标准操作。有一点值得注意:localStorage 受 origin 限制。如果你在同时也提供其他 JavaScript 服务的域名上部署 G0DM0D3,该 origin 上的任何脚本都可以读取存储的 API 密钥。如果部署安全性对你很重要,请使用专用子域名。
方式四 —— 完整 API 服务器(Docker)
适用于生产集成、团队部署,或任何希望以编程方式基于 G0DM0D3 评估引擎进行构建的场景。
用 Docker 构建并运行
cd api/
docker build -t g0dm0d3-api .
docker run -p 7860:7860 g0dm0d3-apiAPI 服务器运行在 7860 端口,以 REST 端点(兼容 OpenAI SDK)的形式暴露 ULTRAPLINIAN 引擎、AutoTune、Parseltongue 和 STM。
将 OPENROUTER_API_KEY 设置为环境变量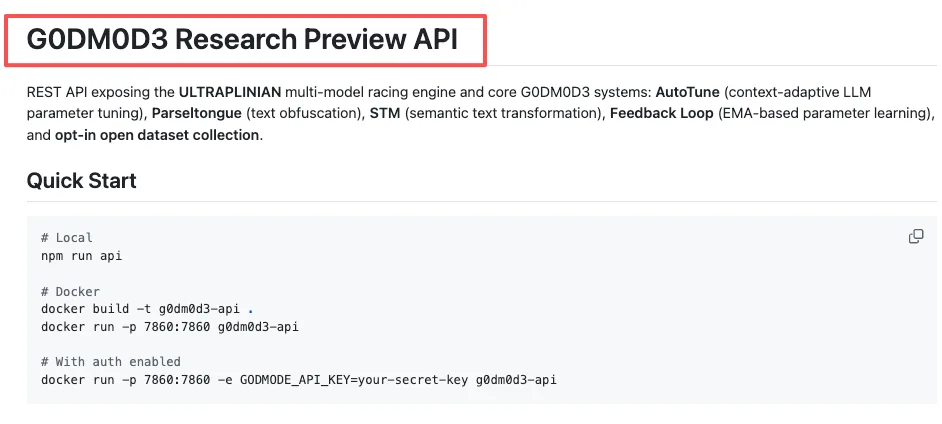
对于 API 服务器,OpenRouter 密钥存储在环境变量中,而非 localStorage:
docker run -p 7860:7860 -e OPENROUTER_API_KEY=sk-or-v1-your-key-here g0dm0d3-api何时使用 API 服务器,何时使用静态文件
静态 index.html 适合个人使用 —— 单人、单浏览器、临时会话。当你需要共享访问而无需每人管理自己的 OpenRouter 密钥,或需要从脚本进行编程访问时,API 服务器更合适。
团队访问和共享部署注意事项
将 GODMODE_API_KEY 或 GODMODE_API_KEYS(逗号分隔)设置为环境变量来保护 API。不设置的话,服务器处于开放状态 —— 本地开发可以,但面向互联网时很危险。
运行你的第一次多模型评估
GODMODE CLASSIC:输入提示词,看 5 个模型竞速
输入提示词,五个模型+提示词组合并行启动 —— Claude、Grok、Gemini 等。5–8 秒内出结果。每次提示词触发五次 API 调用。按当前费率,一次短暂的 CLASSIC 运行花费不到一分钱。
ULTRAPLINIAN:设置层级(1=10 个模型,5=55 个模型),查看综合分数
ULTRAPLINIAN 才是费用计算真正开始重要的地方。五个层级:10、21、31、41 或 55 个模型。每个模型收到相同的提示词,每个响应按 100 分综合评分 —— 质量(50%)、过滤程度(30%)、速度(20%)。
说说实际费用。完整的第五层运行会触发 55 个同时进行的 API 调用。对于 1K token 的提示词、约 500 token 的响应,整次运行大约消耗 76,500 个 token。按模型组合的混合平均价格 200–400 美元/百万 token 计算,完整层级的一次 ULTRAPLINIAN 运行大约花费 0.15–0.30 美元。十次:1.50–3.00 美元。研究会话中的一百次:15–30 美元。请合理规划预算,并通过 OpenRouter 控制台监控支出,而不是依赖 G0DM0D3 界面 —— 该工具没有内置消费追踪器。
关于评分有一点需要了解:研究论文指出,响应长度对有效分数范围的贡献约为 47%。较长的响应得分更高,与准确性无关。在解读排行榜时请记住这个偏差。
AutoTune:经过 10-20 次交互后让其收敛
AutoTune 基于 EMA 学习循环调整采样参数 —— temperature、top_p、top_k。它观察哪些参数配置能产生评分更好的输出,并在会话过程中自适应。需要 10–20 次交互才能进入有效状态。不要在前三次查询就对它下判断。
常见设置错误及修复方法
”API 密钥不起作用” —— OpenRouter 密钥格式和额度要求
GitHub issues 页面上最常见的问题。检查三点:
第一,格式。OpenRouter 密钥以 sk-or-v1- 开头。如果你的密钥不是这样,说明粘贴的凭证有误。
第二,额度。即使你的提示词只需要极少费用,某些模型也要求正的额度余额。免费层级涵盖 25+ 个模型,包括来自 Google、Meta 和 Mistral 的选项,但 Claude 或 GPT-5 等高级模型需要充值额度。OpenRouter 对额度购买收取 5.5% 手续费 —— 100 美元的额度实际需要支付 105.50 美元。
第三,时机。如果你刚刚创建账户,密钥有时需要短暂等待才能激活。在尝试 55 个模型的 ULTRAPLINIAN 之前,先运行一个简单查询确认其可用。
本地服务时的 CORS 错误 —— 原因及修复方法
如果你双击 index.html 而不是通过 python3 -m http.server 提供服务,浏览器会以 file:// URL 打开它。某些浏览器会阻止来自 file:// origin 的跨域 API 请求。解决方法:始终通过本地 HTTP 服务器提供服务。python3 -m http.server 8000 一行命令即可消除这个问题。
并行模式下模型返回错误 —— 速率限制处理
从单个 API 密钥同时发送 55 个请求可能会触发 OpenRouter 的每密钥速率限制。症状:部分模型槽位返回错误,而其他模型正常完成。ULTRAPLINIAN 可以处理部分结果 —— 它对返回的内容进行评分 —— 但糟糕的运行会产生不完整的排行榜。
两个实用修复方法。第一,从较低层级(10–21 个模型)开始,确认账户的速率限制能够处理并发后再扩大规模。第二,如果你使用的是 OpenRouter 免费层级,速率限制更严格。充值额度可以放宽限制。不稳定的 WiFi 会加剧这个问题 —— 浏览器在不稳定移动网络上同时发出 55 个 HTTP 请求会产生超时。请使用稳定的网络连接。
常见问题
运行 55 个模型的 ULTRAPLINIAN 需要多少费用?
对于典型提示词,每次运行大约 0.15–0.30 美元,具体取决于模型组合和响应长度。费用并不均匀 —— Claude 和 GPT-5 等高级模型每 token 的费用远高于 Meta 或 Mistral 的开源替代品。在完整层级下进行 100 次查询的研究会话,预计花费 15–30 美元。在 openrouter.ai/activity 监控支出。
我可以与团队共享 G0DM0D3 实例吗?
使用静态文件(方式 1–3)时,每人需要自己的 OpenRouter 密钥 —— 密钥在每个人的浏览器中客户端存储。使用 Docker API 服务器(方式 4)时,你可以在服务器端设置一个共享的 OpenRouter 密钥,并通过 GODMODE_API_KEY 控制访问权限。这是预定的团队部署路径。
G0DM0D3 支持 Ollama 或本地模型吗?
不直接支持。 G0DM0D3 在架构上与 OpenRouter 的 API 紧密耦合。它没有指向本地 Ollama 端点的接口。如果需要本地模型评估,你需要修改源代码 —— 该项目在 AGPL-3.0 下开源 —— 将 OpenRouter 调用替换为兼容 Ollama 的端点。这是一次非trivial 的分叉,而不是配置更改。
新版本发布时如何更新 G0DM0D3?
在克隆的仓库中运行 git pull。 应用是单个文件,因此没有迁移、没有数据库更新、没有依赖解析。对于 godmod3.ai 上的托管版,更新会自动进行 —— 你始终获得最新部署。
并行运行模型调用时有速率限制吗?
有,但那是 OpenRouter 的速率限制,不是 G0DM0D3 的。 在静态部署中,该工具本身没有服务端速率限制。OpenRouter 按账户层级和额度余额执行每密钥限制。如果你在第五层持续遇到限制,要么充值以增加配额,要么在较低层级运行。
G0DM0D3 在 AGPL-3.0 下授权。企业使用需要单独许可证 —— 详情见 GitHub 仓库。该工具由 elder-plinius(Pliny the Prompter)构建,用于 AI 安全研究、红队测试和多模型评估。
往期文章:
