GPT-5.5 API可用性:团队应提前规划什么
GPT-5.5已宣布发布,但API访问尚未完全开放。以下是团队现在可以提前规划的内容,以及仍需进一步确认的事项。

上周五,我花了一整天把一个 Codex 工作流迁移到了 GPT-5.5,然后又花了周一向两位客户解释为什么这个上线决策比发布头条所呈现的要复杂得多。在 WaveSpeedAI,很多”要不要迁移”的评估文档上都有我的名字,我是 Dora——那个让团队在批准模型切换前等两周的人。API 已经上线了。这是大多数报道说对、然后就停下来的部分。我想写的是发布后的十天,即”可用”变成”真正集成”的过程,以及我合作的大多数团队正在踩的坑。
这是一篇规划笔记,不是教程。如果你来找 curl 示例,官方文档比我讲得更好。
GPT-5.5 目前在哪里可用
ChatGPT 和 Codex 的上线状态
GPT-5.5 于 2026 年 4 月 23 日 面向 ChatGPT 和 Codex 中的 Plus、Pro、Business 和 Enterprise 用户正式上线,其中 GPT-5.5 Pro 仅限 Pro、Business 和 Enterprise 层级使用。在 Codex 中,该模型搭载 400K 上下文窗口,并提供一个速度快 1.5 倍、成本高 2.5 倍的快速模式——这些细节在 OpenAI 的官方 GPT-5.5 发布公告中有清晰说明。发布第一天仅覆盖了消费者端产品。我特别提这一点,是因为上周我看到的工单中,有一半都假设 API 从一开始就与消费者端同步上线了。
OpenAI 关于 API 可用性的说明
早期媒体报道遗漏的部分:API 访问在一天后,即 2026 年 4 月 24 日才上线。 gpt-5.5 和 gpt-5.5-pro 现已在 Responses 和 Chat Completions API 中开放,已在 OpenAI 自己的 GPT-5.5 模型文档中得到确认。API 层面的上下文窗口为 100 万 token,与 Codex 的 40 万上限不同。两个产品面,两个限制——很容易混淆,值得在你的工程师动手之前先记下来。所以问题不再是”我的团队什么时候能用”,而是”我们应该用吗,以及我们首先要验证什么”。
API 集成前团队可以安全规划的事项
评估标准与迁移准备
我不建议当天就迁移。以下是我会首先确认的内容。
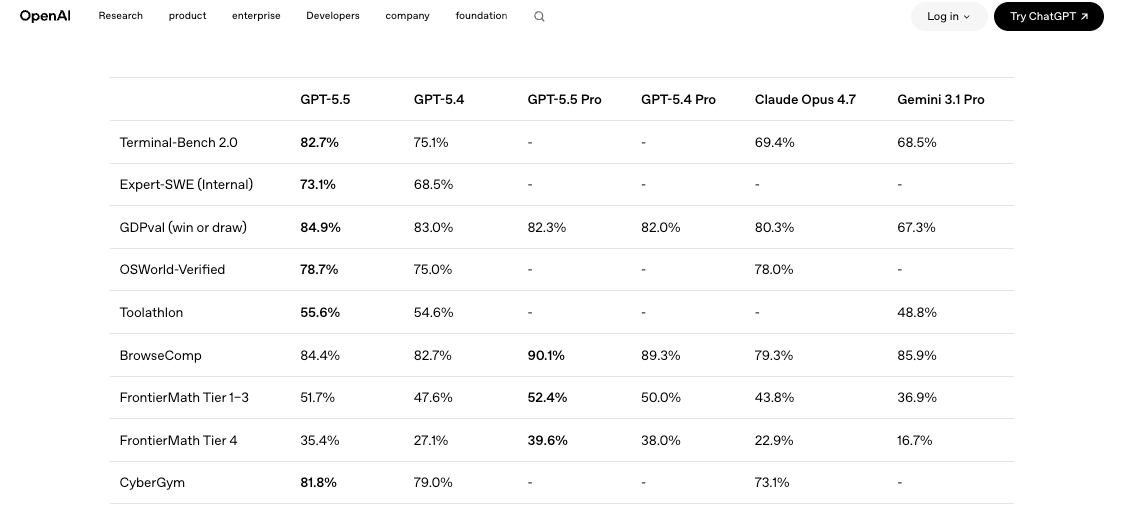
针对你当前使用的模型搭建一个小型评估框架。从你的真实工作负载中抽取五到十个有代表性的提示词,按照对你真正重要的维度打分:正确性、token 成本、延迟、重试率。在相同提示词、相同温度设置、相同工具定义的条件下,并排运行 GPT-5.4 和 GPT-5.5。LLM Stats 上发布的对比报告等独立基准测试显示,GPT-5.5 在 10 个共同基准测试中有 9 个取得了进步,但在 SWE-Bench Pro 上仅有微弱提升。结论是:升级是真实的,但并非全面领先。你的工作负载才是决定因素。
现在就确定好回退方案,不要等到第一个 429 错误出现再说。新模型发布后,历史上头 30 天的速率限制往往比较严格。在你切换哪怕一个生产请求之前,先把 GPT-5.4 作为回退方案接好。我亲眼看过两个团队跳过这一步,然后在上线日流量高峰时付出了代价。
采购、安全和工程团队需要回答的问题
以下是我本周不得不回答的几个问题:
- 定价翻倍了。 标准费率为每 100 万输入 token 5 美元、每 100 万输出 token 30 美元,见 OpenAI 官方定价页面。Pro 版为 30 美元 / 180 美元。Token 效率提升在 Codex 工作负载上能部分抵消这一涨幅,但在大多数其他工作负载上,预计账单会明显增加。
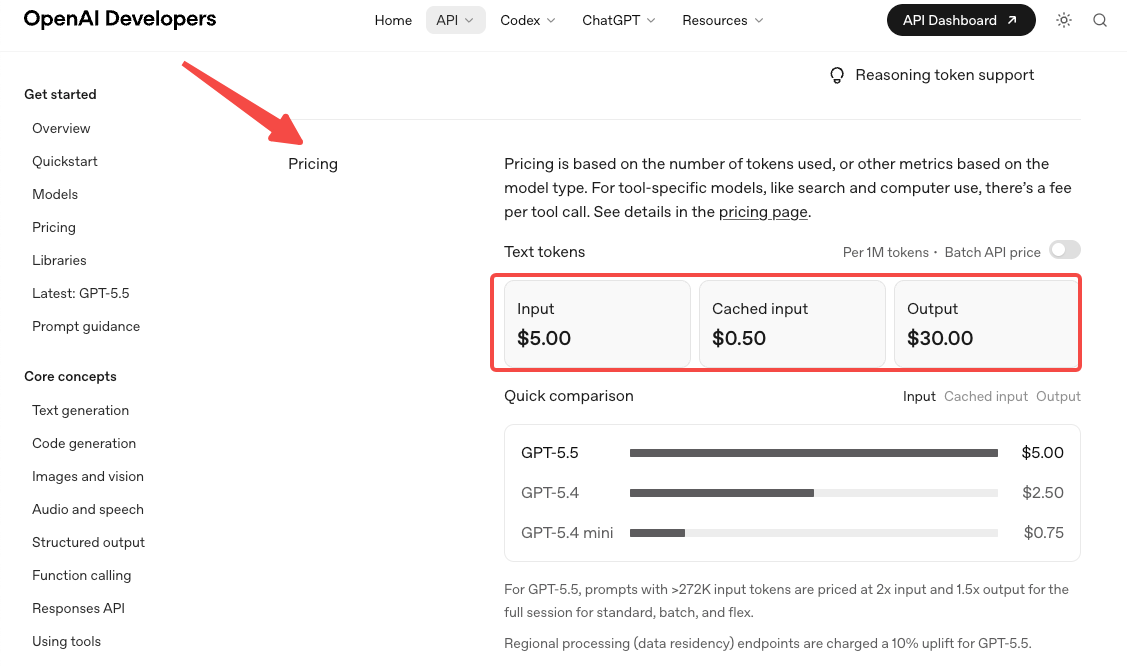
- 长上下文定价在 272K 处发生变化。 超过该阈值后,整个会话的输入价格翻倍、输出价格变为 1.5 倍。如果你的工作流经常超过 272K token,请分两次建模成本——一次在阈值以下,一次在阈值以上。这能帮助那些基于 GPT-5.4 层级结构构建、并假设新模型会沿用相同结构的团队提前发现问题。
- 安全团队需要阅读系统卡。 GPT-5.5 附带了更严格的网络安全分类器,已记录在 GPT-5.5 系统卡中。部分合法工作负载在 OpenAI 调整期间会被初步拦截。对于任何通过 API 运行安全工具、代码分析流水线或红队工作流的团队,这一点值得特别提醒。
上线前仍需验证的内容
模型 ID、速率限制、定价与工具支持
我会按以下顺序逐一验证:
1.模型 ID 与快照版本。 锁定到具体快照,而不是别名。别名会变,快照不会。在将任何内容硬编码到客户端之前,先在 GPT-5.5 模型页面上确认可用列表。
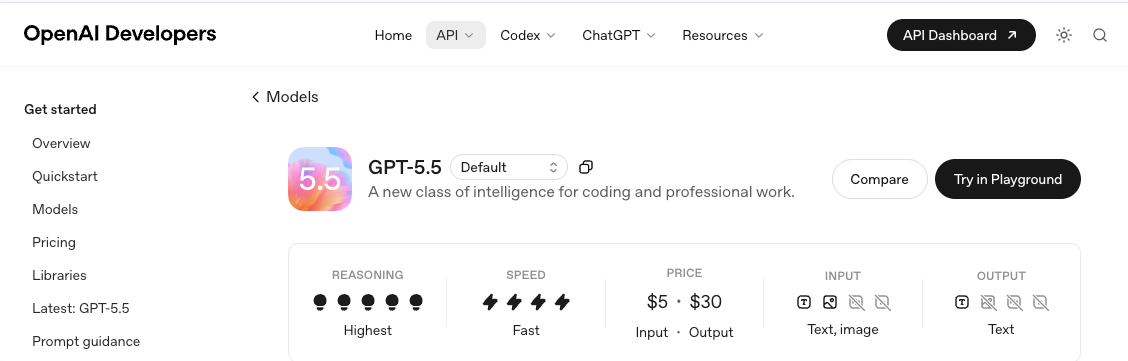
2.你所在层级的速率限制。 OpenAI 的层级系统会根据消费自动升级,但上线日的限制可能比 GPT-5.4 目前享有的更严格。我会先从 OpenAI 速率限制文档入手,并在假设有足够余量之前,对你当前层级进行一次合成突发测试。
3.工具与结构化输出行为。 函数调用、网络搜索和结构化输出都可以使用,但确切的 schema 和推理模式的交互方式需要针对你的实际工具定义进行冒烟测试。我见过推理努力设置以某些方式改变重试行为,而这些变化在触及生产流量之前根本不会显现。
吞吐量与企业级部署细节
对于处理大规模请求量的团队:批量模式(Batch)和弹性模式(Flex)的费率为标准费率的一半,优先模式(Priority)为 2.5 倍。结论是:如果你的工作可以接受异步处理,GPT-5.5 批量模式的每 token 成本与 GPT-5.4 标准模式相同。 这是本次发布中隐藏的真正套利机会,我接触的几乎所有人都还没把这一点纳入考量。apidog 上的 GPT-5.5 定价详解通过实际案例对此有比我更详尽的说明。
直接对接供应商 vs 平台化接入的规划对比
我在一个聚合模型访问的平台工作,所以我的立场摆在这里。但无论你使用谁的平台,结构性论点都是一样的:当单一供应商在第一天就发布一个价格翻倍的模型时,路由逻辑的价值只会更大,而不是更小。
直接对接供应商的流程是这样的:重写客户端,重新测试提示词,重建成本模型,每换一个供应商重复一遍。多模型平台——包括 WaveSpeedAI,也包括其他平台——允许你通过修改配置来切换模型。代价是你在自己和数据源之间增加了一个中间层。对于每天高频发布的团队来说,这个中间层通常值得换取这层抽象。对于在单一工作负载上低频运行一个模型的团队来说,则未必值得。
无论如何,我都建议规划路由架构。高价值请求走 GPT-5.5,常规流量走 GPT-5.4 或其他前沿模型——仅这一模式,就能比单模型默认方案节省 40–60% 的费用,无论你以哪家供应商为核心。
常见问题
GPT-5.5 的 API 是否已经上线?
是的,自 2026 年 4 月 24 日起已上线。4 月 23 日的发布仅覆盖 ChatGPT 和 Codex;API 在一天后跟进。gpt-5.5 和 gpt-5.5-pro 均可通过 Responses 和 Chat Completions 端点访问,上下文窗口为 100 万 token。
团队在开始集成工作之前应该验证哪些内容?
评估真实 token 使用组合下的定价影响、当前层级的速率限制上限、GPT-5.4 回退方案的接入与测试,以及一个对比两个模型在实际工作负载上表现的简短评估框架。锁定快照 ID,而不是别名。
与其使用 GPT-5.4,等待是否更值得?
取决于工作负载。对于代理式编程和计算机操作任务,GPT-5.5 有明显提升,TechCrunch 的发布报道对此有所记录。对于 GPT-5.4 已经满足质量要求的工作负载,在没有可量化提升的情况下,每 token 价格翻倍很难说值得。
团队应如何为快速 API 上线做准备?
现在就搭建评估框架,如果还没有的话通过抽象层进行路由,并预设速率限制会先收紧再放开。不要预付大额信用额度——这一代模型的定价仍在变动中。
价格翻倍是否意味着账单也翻倍?
不完全是,但差距不大。Codex 工作负载上的 token 效率提升能让实际账单控制在 2 倍以下。其他工作负载则接近标价。批量处理以半价计费,是首先值得尝试的杠杆。
结语
API 已上线。定价已变更。速率限制仍在调整中。这一切都不意味着你应该急于行动。 它意味着大多数团队原本期待的规划窗口比预期关闭得更快,而现在的工作是验证,而不是等待。
我自己的迁移计划在未来两周内进行。GPT-5.5 在那之后是否会留在我的默认路由中——我还不知道。这正是评估的意义所在。
后续内容持续更新。




