Claude Mythos 与 Claude Opus 4.6 对比:泄露信息揭示了什么
Claude Mythos 与 Opus 4.6 对比:泄露信息揭示了两者的能力差距,以及开发者应该等待还是立即开始构建。

上周我正在全力冲刺一个 Claude Code 集成 项目,Mythos 泄露消息突然出现在我的信息流里。十分钟内,Slack 上连续来了三条消息,都是同一个问题的变体:“我们要暂停构建吗?” 我是 Dora,一个热衷于 AI 的人,从那以后一直在密切跟踪这个故事——我认为答案比炒作更加微妙。
在 WaveSpeedAI 上运行 Claude Opus 4.6(以及更新的 Opus 4.7) —— 按 token 计费,兼容 OpenAI。Claude Opus 4.6 API → · Claude Opus 4.7 API → · 打开 Playground →
让我来梳理一下泄露内容的实际含义、Opus 4.6 目前能提供什么,以及如何就时机做出真正的决策。
基准线:Claude Opus 4.6 目前为开发者提供了什么
在深入 Mythos 猜测之前,先锚定一下今天真正可用且有文档记录的内容。
编程与智能体任务性能
Claude Opus 4.6 在 Terminal-Bench 2.0 上达到 65.4%,在 OSWorld 上达到 72.7%,使其成为 Anthropic 目前公开可用的最强编程和计算机使用任务模型。Terminal-Bench 这个数字不仅仅是一个基准奖杯——它代表着真实的智能体能力:多步调试、大规模重构,以及跨扩展工作流的自主工具链。
该模型专为在整个工作流(而非单个提示词)上运行的智能体而构建,使其在大型代码库、复杂重构和随时间展开的多步调试中尤为有效。如果你在构建编程智能体或智能体流水线,这个模型真的能关闭 issue 并以生产质量交付代码。
在操作层面最重要的是:Opus 4.6 能将复杂任务分解为独立子任务,并行运行工具和子智能体,并以真正的精确度识别阻塞点。这种行为才是在真实 CI/CD 相邻自动化中发挥作用的关键,而不只是演示环境。
API 可用性、定价与文档
这是对你决策时间线真正重要的部分。Claude Opus 4.6 以每百万 token 输入 $5 / 输出 $25 的价格提供最先进的推理能力——相比 Opus 4.1 时代的 $15/$75 降低了 67%。完整的 Claude API 文档 已公开、有版本控制且稳定。你今天就可以通过 claude-opus-4-6 访问它。
4.6 代的一个突出特性是完整的 100 万 token 上下文窗口已包含在标准定价中,消除了早期模型中适用的长上下文溢价费用。对于需要处理大型代码库摄入或长研究工作流的团队,与之前的版本相比,这是一次有意义的成本降低。
当前完整记录且可用的成本优化手段:
Claude Mythos 泄露揭示了什么差距
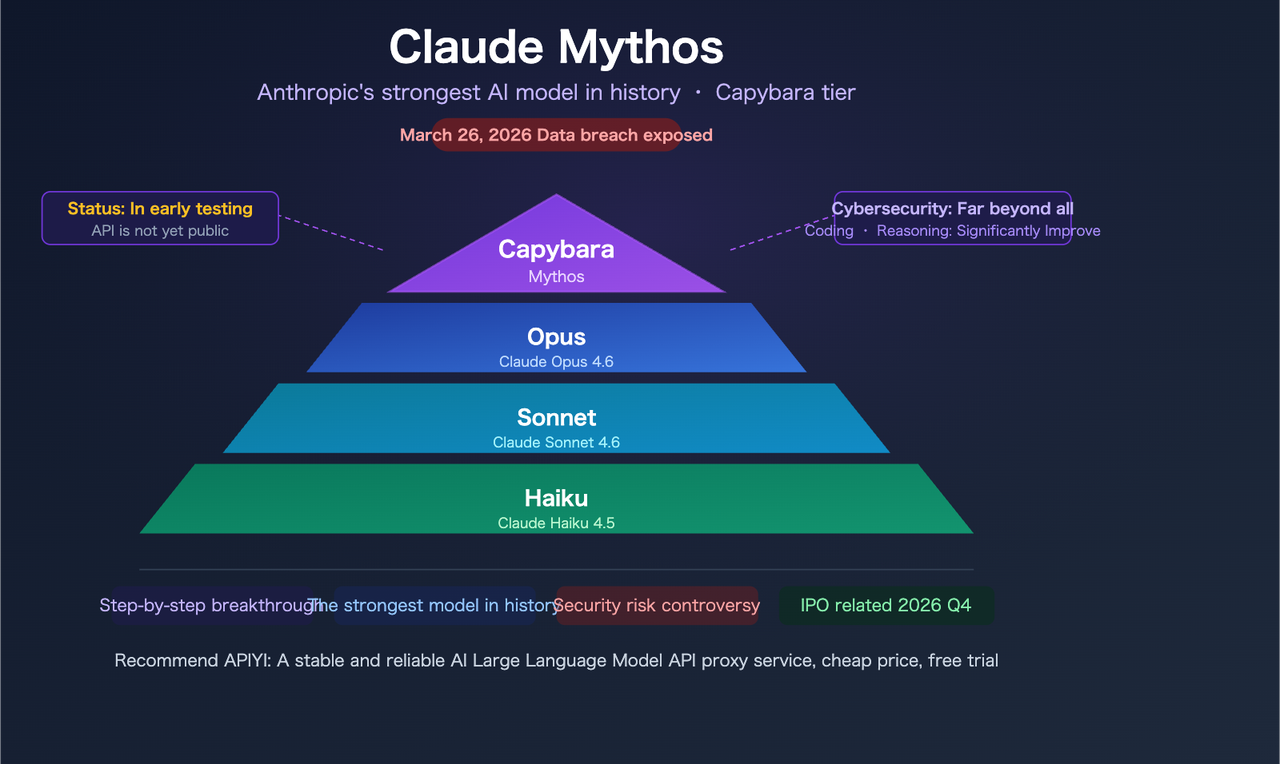
本月早些时候,《财富》杂志报道 Anthropic 在一个配置错误的公开可搜索数据存储中意外暴露了近 3000 个内部文件。其中包括:一篇关于名为 Claude Mythos 的模型的博客草稿——内部代号也叫”Capybara”。
深入之前的重要背景:以下所有内容均来自未经验证的草稿文件,而非官方发布。 没有公开基准测试,没有 API 访问权限,没有定价页面。Anthropic 已确认该模型存在并处于有限测试中。其他一切仍是草稿。
编程——“大幅更高的分数”解读
泄露的博客写道:“与我们之前最好的模型 Claude Opus 4.6 相比,Capybara 在软件编程、学术推理和网络安全等测试中获得了大幅更高的分数。“这是内部文件中有分量的措辞——“大幅更高”不是含糊的营销话术,而是强烈的内部声明。
我们没有的是:具体数字。除了草稿中的定性表述外,没有发布任何具体分数。任何现在引用 Mythos 确切基准数字的人都是在捏造。诚实的解读是:Anthropic 的内部评估显示差距大到足以建立新的产品层级——这本身就是重要信号,但与拥有经过验证的数据不同。

学术推理改进
泄露草稿将学术推理与编程并列,作为关键差异化能力。Anthropic 将 Mythos 描述为”在推理、编程和网络安全方面取得有意义进步的通用模型”。对于构建研究助手、文档分析流水线或法律/金融推理工作流的开发者来说,这值得关注——Opus 4.6 已经在 BigLaw Bench 上达到 90.2%,如果 Mythos 进一步突破这个边界,用例范围将显著扩大。
网络安全能力:新领土
这是获得最多关注的能力维度——有充分理由。泄露草稿描述该模型”目前在网络安全能力方面远超任何其他 AI 模型”,并警告它”预示着即将到来的一波能够以远超防御者努力的方式利用漏洞的模型”。
泄露的内部文件警告,该模型可能通过快速发现和利用软件漏洞显著加剧网络安全风险,可能加速网络军备竞赛。这就是为什么 Anthropic 的初始推出仅限于专注于网络防御的组织——这一不寻常的举措表明了对滥用的真实担忧,而不仅仅是例行的安全姿态。
这里的双重用途张力是真实存在的。Anthropic 目前的 Opus 4.6 已经展示了在生产代码库中发现此前未知漏洞的能力,该公司承认这是双重用途的——同时帮助黑客和防御者。Mythos 似乎将这种能力推进得更远,这解释了为何采取谨慎推出的方式。
这是新层级,而非版本升级——为何重要
结构上 Capybara 高于 Opus
泄露草稿声明:“Capybara 是新名称,代表新的模型层级:比我们的 Opus 模型更大、更智能——而 Opus 模型直到现在都是我们最强大的。“这在结构上不同于 Opus 4.5 → Opus 4.6。Anthropic 目前有三个层级:Haiku、Sonnet、Opus。Capybara 将在所有层级之上新增第四个层级。
这影响你如何设计系统架构。如果你的构建假设 Opus 始终是上限,那么在其之上新增一个层级意味着潜在的能力升级——不仅仅是增量微调改进,而是代表不同类别的任务成功率。
定价:设计上更昂贵
目前还没有官方定价,但结构信号很明确。草稿博客指出该模型运行成本高昂,尚未准备好公开发布。鉴于 Capybara 在新层级中位于 Opus 之上,预计定价将高于 Opus 4.6 目前的 $5/$25 每百万 token。高出多少尚不清楚——但要做好它会明显更高而非小幅增加的准备。
这不一定是坏消息。从 Opus 4.1 到 Opus 4.6 降价 67% 表明 Anthropic 已学会跨代降低旗舰定价。Capybara 今天以高价发布并不意味着 12 个月后仍维持该价格。这种模式表明,真正的 ROI 问题在于能力提升是否在你的具体任务分布上值得付出成本。

你的团队应该等待 Claude Mythos 吗?
这才是你真正想要的决策。以下是诚实的框架。
如果你在构建编程智能体或智能体工作流
现在就用 Opus 4.6 构建。 能力差距可能是真实的,但等待一个没有公开时间表的未发布模型不是产品策略。Opus 4.6 已经是公开可用的最强智能体编程模型——Terminal-Bench 2.0 的 65.4% 是支持今天生产用例的有意义基准线。
更重要的一点:你现在做出的架构决策——提示词缓存策略、子智能体编排、工具使用模式——将在 Mythos 发布时直接迁移过去。在 Opus 4.6 上构建,设计模型无关的路由,当 Mythos 发布时,你的迁移准备将远优于那些等待后从头开始的团队。
如果你的优先级是规模化成本效率
一定要现在就构建。 Mythos 预计比 Opus 4.6 更贵,且没有迹象表明发布时会有等效的经济型层级。如果你正在运行高容量工作负载,其中每百万 token $5/$25 已经需要通过批处理和提示词缓存进行仔细优化,那么即使在公开可用后,Mythos 也不太可能成为你的默认模型。利用这段时间优化你的 Opus 4.6 工作流;这些节省是真实且当下可获得的。
值得做的计算:一个每月在标准 Opus 4.6 上花费 $2500 的团队,通过模型混合、批处理和缓存,现实中可以降至约 $250/月。在你等待的这几个月里,这 90% 的降幅会显著复利增长。
如果你的用例涉及漏洞研究或安全
这是唯一一个等待说得通的情况——但你可能没有选择权。 Mythos 的初始访问群体专注于安全研究人员和防御者——目标是在模型的攻击性能力广泛可用之前准备好防御措施。如果你的团队从事进攻性安全研究或防御性工具开发,正确的做法是通过 Anthropic 渠道申请早期访问,同时继续在 Opus 4.6 上构建。
对于一般企业安全工具(代码扫描、合规、漏洞分类),Opus 4.6 已经足够强大且完全可用。Mythos 可能延伸的是上限,而不是下限。
Mythos 尚未公开时该做什么
具体来说,以下是如何避免浪费精力同时保持高效采用 Mythos 的准备:
设计模型无关的路由。 在路由层后面抽象你的模型调用,这样将 claude-opus-4-6 替换为未来的 claude-capybara-* 模型字符串只是配置更改,而不是架构重写。无论 Mythos 如何,这都是好的实践——它还能让你今天将成本敏感的任务路由到 Sonnet 4.6。
# 示例:模型无关路由封装
import anthropic
MODEL_CONFIG = {
"flagship": "claude-opus-4-6", # Mythos 发布时在这里替换
"balanced": "claude-sonnet-4-6",
"fast": "claude-haiku-4-5-20251001"
}
def call_claude(task_tier: str, messages: list, **kwargs):
client = anthropic.Anthropic()
return client.messages.create(
model=MODEL_CONFIG[task_tier],
max_tokens=1024,
messages=messages,
**kwargs
)现在就实施提示词缓存。 根据 Anthropic 的提示词缓存文档,缓存写入在首次命中时会产生 25% 的附加费,但在后续命中时以 90% 的折扣读取。对于具有重复系统提示词或大型上下文块的智能体工作流,这是当前可用的单一最高杠杆成本优化手段——而且在 Mythos 上也将以同样的方式工作。
追踪官方发布节奏。 Anthropic 已确认正在与早期访问客户进行测试。Anthropic 使用的分阶段推出模型——先安全合作伙伴,然后更广泛访问——表明通用 API 可用性可能在数周到数月后,而不是几天内。
诚实评估你的任务分布。 如果你 80% 的 API 调用是文档摘要、问答或结构化提取,Mythos 在编程和网络安全方面的进步可能对你影响不大。Opus 4.6 在这些工作负载上已经足够强大。把你的 Mythos 评估留给那些你目前正在触及 Opus 上限的任务。
常见问题
Q:我今天可以使用 Claude Mythos 吗?
不能。截至 2026 年 3 月下旬,Claude Mythos(Capybara)仅对一小群早期访问客户开放,特别是那些从事网络防御应用的客户。没有公开 API,没有文档,也没有公布的发布日期。Claude Opus 4.6 通过 Anthropic API 上的 claude-opus-4-6 访问,仍是公开可用的最强模型。
Q:Opus 4.6 仍然是最好的公开 Claude 模型吗?
是的。Claude Opus 4.6 和 Sonnet 4.6 仍然是公开可用的最强大 Claude 模型——而且它们在编程、推理和复杂任务上已经非常强大。Opus 4.6 在智能体编程公开排行榜上位居榜首,并通过 Anthropic 平台、AWS Bedrock、Google Vertex AI 和 Microsoft Foundry 提供完整记录的稳定 API 访问。
Q:Claude Mythos 会贵多少?
未知。泄露草稿确认该模型”运行成本高昂”,而位于 Opus 之上的新 Capybara 层级在结构上意味着高于 Opus 4.6 目前每百万 token $5/$25 的价格溢价。没有发布官方定价。历史先例表明 Anthropic 确实会跨模型代际降低旗舰定价,因此早期发布定价可能不反映长期成本。
Previous Posts:




