Claude Code Agent Harness:架构解析
Claude Code 如何连接工具、管理权限并协调 Agent 会话——面向构建者的技术深度解析。

在构建自己的工具调用系统时,我反复遇到同一个问题:为什么工具接线比写提示词难这么多?
模型这部分很快就搞定了。但当我需要它真正去做事情——读取文件、执行 shell 命令、与外部服务通信——每一个决策都感觉可能会破坏什么。权限边界、上下文限制、工具调度。
然后,在 2026 年 3 月下旬,Claude Code 的源代码因 npm 源映射问题在 2.1.88 版本中意外泄露。超过 50 万行 TypeScript 代码在数小时内被镜像。Anthropic 确认这是一次打包错误——未涉及任何客户数据——并开始发出 DMCA 删除通知。
但其架构已成为公开知识。它所揭示的不是模型本身,而是运行框架(harness)。
关于信息来源的说明:本文内容来自社区分析、开源复现以及 Anthropic 的公开文档和工程博客——并非泄露代码本身。不确定的细节均有标注。
什么是 Agent Harness?
定义及其在智能体系统中的作用
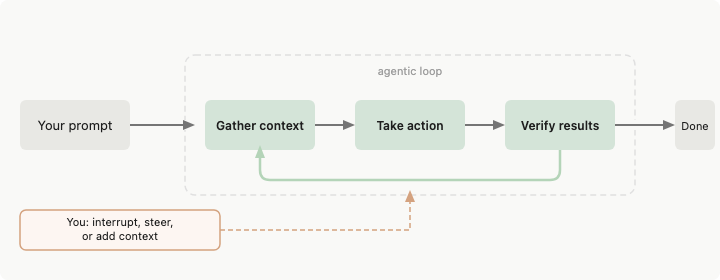
Agent harness 是语言模型与真实世界之间的一切。模型生成文本,harness 决定这些文本能触及什么。
Anthropic 的 Claude Code 文档直接说明了这一点:Claude Code”提供工具、上下文管理和执行环境,将语言模型转变为一个有能力的编程智能体。“模型负责推理,harness 负责行动。
当你的智能体读取一个文件时,harness 决定读取是否被允许、结果如何处理,以及有多少响应内容能放入下一个提示词。模型从不直接接触文件系统。
为什么 harness 设计对生产环境至关重要
大多数智能体演示都跳过了这部分。你看到模型调用一个函数、获得结果、再调用另一个。看起来很简洁。然后你在真实代码库上跑了 45 分钟,事情就悄悄崩掉了——上下文溢出、权限要么太宽松要么太烦人、工具结果被截断而模型毫不知情。
Anthropic 的工程团队写过这方面的内容:即使是前沿模型在多个上下文窗口中循环运行,如果没有精心设计的 harness,也会表现不佳。智能体会试图同时做太多事,或过早宣告任务完成。harness 对这种倾向施加了结构性约束。

Claude Code 的工具接口
核心工具分类
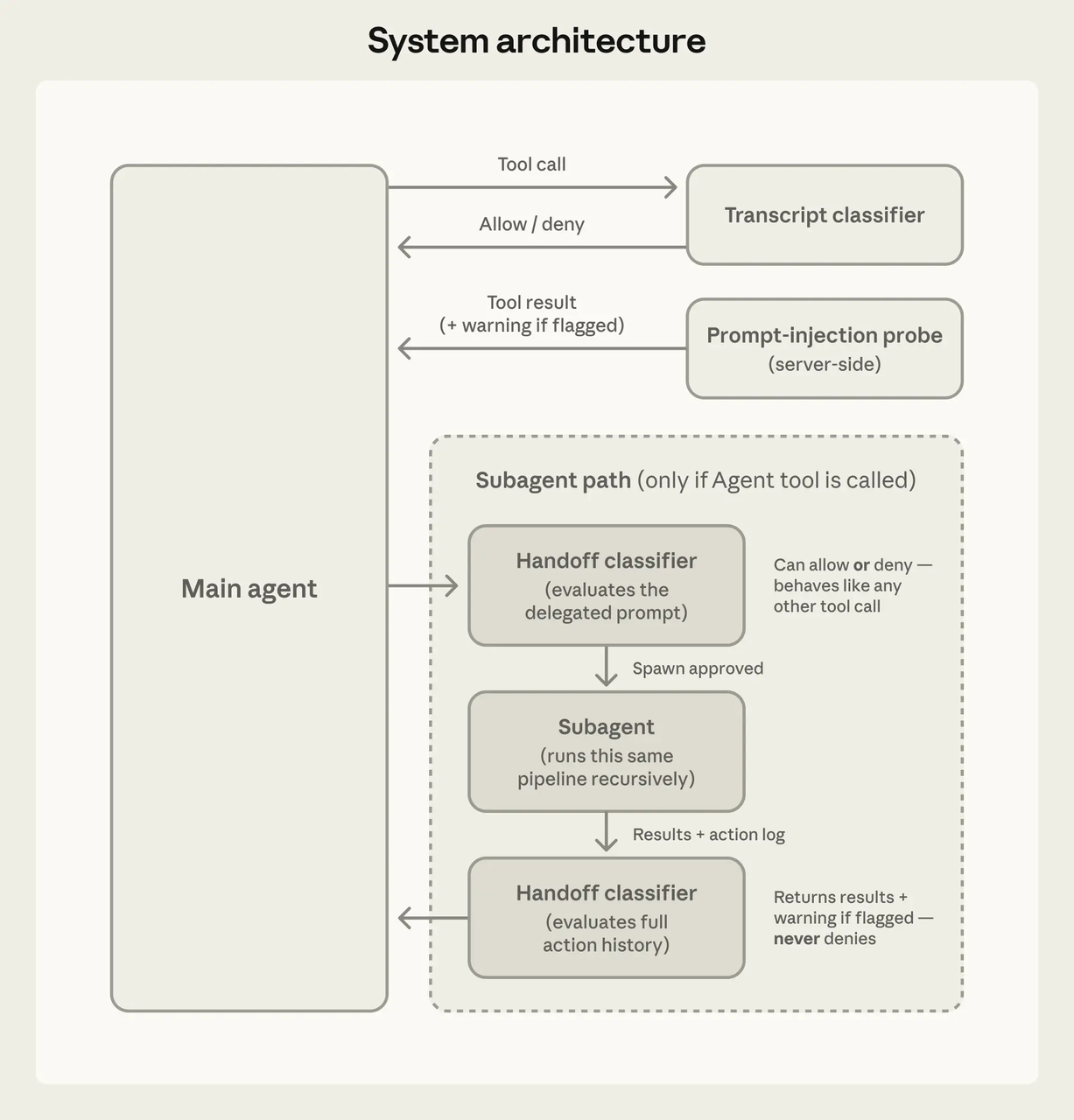
根据 Claude Code 官方文档和公开分析,Claude Code 暴露了大约 19 个受权限控制的工具。主要类别包括:文件读取与编辑、shell 执行(Bash)、Git 操作、网页获取、Notebook 编辑,以及 MCP 工具调用。社区分析显示,如果加上 LSP 集成、子智能体生成和内部协调工具,数量可能接近 40 个。
每个工具都独立沙箱化。并不是”智能体拥有文件系统访问权限”——而是”智能体可以使用 Read 工具,而 Read 有自己的权限门控,在任何执行之前会检查规则管道。“
工具如何注册和调度
模型决定要尝试什么,工具系统决定是否被允许。两者在架构上是分离的。
每次工具调用在执行前都经过权限检查。社区深度解析描述了一个核心函数,按 deny/ask/allow 的顺序评估规则——deny 永远优先。三种可能结果:静默执行、提示用户,或阻止执行。
一个被攻破的模型无法通过说服来绕过安全检查。harness 不在乎模型的论点,规则就是规则。
权限层级
Claude Code 的权限模型被多位社区分析人士描述为大致三个层级:
第一层——自动批准:只读或本质上安全的操作。文件读取、文本搜索、代码导航。这些不改变状态,因此无需中断即可运行。
第二层——需要确认:以受控方式修改状态的操作。文件编辑、某些 shell 命令。在自动模式(2026 年 3 月引入)下,运行在 Sonnet 4.6 上的后台分类器会评估这些操作是否可以无需询问即可执行。该分类器能看到用户的请求和工具调用,但看不到模型的散文输出——这是一个刻意的设计选择,防止模型用花言巧语通过权限门控。
 第三层——需要明确批准或直接阻止:高风险操作。可能以不可预测方式修改系统状态的 shell 命令、工作目录之外的操作、任何看起来像数据泄露的行为。
第三层——需要明确批准或直接阻止:高风险操作。可能以不可预测方式修改系统状态的 shell 命令、工作目录之外的操作、任何看起来像数据泄露的行为。
一个注意事项:三层框架来自社区分析,而非 Anthropic 的官方文档。官方系统使用 allow/ask/deny 规则和六种权限模式(default、acceptEdits、plan、auto、dontAsk、bypassPermissions)。“三层”是一个有用的心理模型,但只是简化版本。
会话与上下文管理
Claude Code 如何跟踪会话状态
Claude Code 在会话过程中积累上下文——读取的文件、运行的命令、grep 结果、diff、错误输出。这一切都堆叠进一个不断增长的提示词。与聊天界面中每条消息相对独立不同,Claude Code 会话是连续的工作内存。
会话保存在本地。每条消息、工具使用和结果都被存储,支持回退、恢复和分叉。在代码变更之前,harness 会对受影响的文件进行快照,以便你可以还原。
输出截断与 token 成本处理
大型工具输出是一个真实存在的问题。Claude Code 为 MCP 工具输出设置了默认最大值 25,000 个 token,并在 10,000 个 token 时发出警告。服务器作者可以注释工具以允许更大的结果(最多 500,000 个字符),这些结果会持久化到磁盘而不是保留在上下文中。
这种事情你不会想到,直到你的智能体因为工具结果被截断而悄悄丢失信息。明确的、可配置的限制加上基于磁盘的回退——值得借鉴。
压缩行为
这个问题曾经困扰过我,直到我理解它为止。当 token 使用量达到上下文窗口的约 98% 时,Claude Code 会自动压缩:它会总结早期历史以释放空间。关键元数据被保留,图像和 PDF 被剥离。
棘手之处在于:压缩可能丢失重要细节。实际的解决方法是:将所有关键内容放入 CLAUDE.md,harness 每次轮次都会重新读取它。
Anthropic 关于 harness 设计的研究发现,对于长时间会话,完整的上下文重置——让新的智能体实例从交接产物中接手——有时比压缩效果更好。编排复杂度更高,但上下文保真度更好。
MCP 集成层
Claude Code 如何连接到 MCP 服务器
 MCP(模型上下文协议) 是连接 AI 工具与外部服务的开放标准。Claude Code 支持三种传输模式:HTTP(推荐用于远程服务器)、stdio(用于本地进程)和 SSE。
MCP(模型上下文协议) 是连接 AI 工具与外部服务的开放标准。Claude Code 支持三种传输模式:HTTP(推荐用于远程服务器)、stdio(用于本地进程)和 SSE。
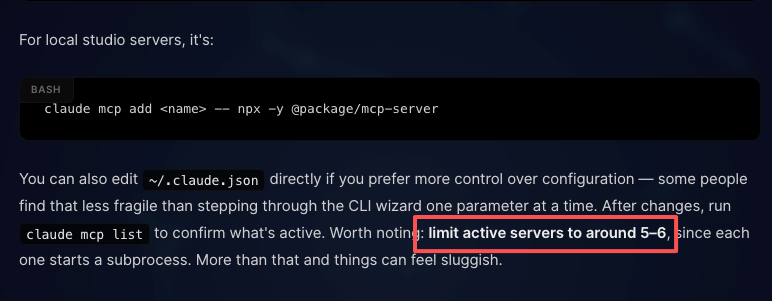
添加服务器只需一条命令:claude mcp add server-name --transport http "URL"。之后,该服务器的工具会作为可调用工具出现在会话中,受与内置工具相同的权限管道约束。
工具发现与认证流程
有一个细节让我印象深刻:工具搜索。当你连接 MCP 服务器时,Claude Code 不会在会话开始时就将所有工具 schema 加载到上下文中。它只在会话开始时加载工具名称,然后在任务实际需要时使用搜索机制发现相关工具。只有 Claude 使用的工具才进入上下文。
这使 MCP 开销保持较低。认证流程取决于服务器——OAuth、API 密钥、请求头。Claude Code 要求用户对新 MCP 服务器进行明确批准。
生产就绪 vs. 仍在演进
MCP 集成功能完善且被积极使用,但有一些值得了解的实际限制:
推荐的上限约为 5-6 个活跃 MCP 服务器,因为每个服务器都会启动一个子进程。工具搜索有助于控制上下文开销,但超过这个数量后延迟仍会增加。
 大型 MCP 响应需要谨慎处理。 25K token 的默认限制适用于大多数用例,但对于数据库 schema 来说会比较紧张。持久化到磁盘的回退有帮助,但模型在上下文中只获得引用而非完整结果。
大型 MCP 响应需要谨慎处理。 25K token 的默认限制适用于大多数用例,但对于数据库 schema 来说会比较紧张。持久化到磁盘的回退有帮助,但模型在上下文中只获得引用而非完整结果。
社区构建的 MCP 服务器质量参差不齐。Anthropic 的文档明确指出,第三方服务器可能是提示注入的攻击向量。权限系统有所帮助,但信任仍然取决于你自己。
构建者的经验教训
这个架构揭示了生产级智能体系统的什么规律
以下是 Claude Code 设计中我认为具有普遍意义的几个模式:
将推理与权限执行分离。 模型决定它想做什么,另一个系统决定是否被允许。一个被攻破的模型无法覆盖安全检查,因为那根本就是不同的代码路径。
明确管理上下文。 压缩、截断限制、工具搜索、磁盘持久化——这些都是主动管理模型所见内容的机制。大多数业余智能体项目把上下文当作无底洞,其实并非如此。
为会话连续性而设计。 快照、可还原的文件更改、CLAUDE.md 作为持久锚点。长时间运行的智能体需要能在上下文压缩后仍然存活的记忆。
权限粒度是值得的。 按工具、按模式、按目录设置规则,优先评估 deny。比一个”允许一切”的标志要费更多工夫,但这就是演示产品与可部署系统之间的区别。
何时自己构建 harness,何时使用托管层
任务范围窄、定义明确——比如运行测试并发布结果的 CI 机器人——你可以自己接一个最小化的 harness。几个工具、简单的权限检查、固定的上下文窗口。
长时间会话、跨上下文重置的状态、不可信的工具输出、数十个工具——那就基于现有 harness 构建,或者仔细研究一个。Claude Agent SDK、OpenAI 的 Codex 架构、LangGraph 都已经解决了你最终会遇到的问题。
大多数团队低估了 harness 的复杂性,我当时也是。模型才是简单的那部分。
常见问题
Claude Code 的 agent harness 是什么?
它是 Claude 模型与真实世界之间的基础设施层——工具调度、权限、上下文管理、会话状态、MCP 连接。Anthropic 将其描述为”将语言模型转变为有能力的编程智能体”的东西。
Claude Code 如何处理工具权限?
基于规则的管道评估每次工具调用:allow、ask 或 deny,deny 永远优先。在自动模式下,运行在独立模型实例上的后台分类器评估模糊情况——并且刻意不查看智能体的散文输出,以防止提示注入。
Claude Code 的 MCP 集成是否已生产就绪?
功能完善且被积极使用,但在服务器数量、响应大小和第三方信任方面存在实际限制,并且仍在快速演进中。
我能用相同的模式构建自己的 harness 吗?
可以。Claude Agent SDK 暴露了相同的权限模式、钩子和上下文管理。社区项目 Everything Claude Code 也记录了可复用的模式。
spec 对等和行为对等有什么区别?
Spec 对等意味着支持相同的工具和配置。行为对等意味着以相同方式处理边缘情况——压缩丢失关键规则、工具返回 10 万个 token、模型试图绕过权限。匹配规格很简单,匹配行为需要数月时间。
有一件事让我久久不忘:harness 才是难点所在。每个人都认为模型是竞争优势所在。确实如此——直到你试图让它在五分钟以上可靠地做事。那才是工程真正所在之处。
往期文章:




