DeepSeek V4上下文缓存:重复提示成本降低90%
DeepSeek的缓存命中定价便宜90%。了解如何构建提示以实现最大化缓存利用率。

嘿,我是 Dora。上周有件小事让我有些懊恼:我把同一个提示词跑了三遍,因为我找不到上次保存的最新草稿在哪里。输出结果几乎没什么变化,但我的速率限制却消耗掉了。这件事促使我开始思考 DeepSeek v4 缓存的问题。
 我并不期待什么奇迹。我只是希望减少不必要的调用、让延迟更稳定,以及在速率限制下多一点喘息空间。由于 v4 目前还没有完善的文档,我从研究 v3 和类似 API 的实际使用情况入手,然后整理出了几个我能接受的客户端模式。如果 DeepSeek 为 v4 推出官方缓存功能,我希望能直接接入,而无需重新调整工作流程。
我并不期待什么奇迹。我只是希望减少不必要的调用、让延迟更稳定,以及在速率限制下多一点喘息空间。由于 v4 目前还没有完善的文档,我从研究 v3 和类似 API 的实际使用情况入手,然后整理出了几个我能接受的客户端模式。如果 DeepSeek 为 v4 推出官方缓存功能,我希望能直接接入,而无需重新调整工作流程。
在 WaveSpeedAI 上即刻可用 — 按 token 透明计费,OpenAI 兼容端点。 DeepSeek V3.2 API → · DeepSeek R1 API →
以下是我处理 deepseek v4 缓存问题的思路:假设存在限制、缓存可重复的内容、从容地重试,并观察关键指标。
预期速率限制
目前我还没找到 v4 的完整公开说明,所以我把这件事当成赶飞机转机来处理:假设时间很紧,提前为延误做好准备。
我在使用 DeepSeek v3 及类似服务商时积累的经验很简单:
- 日常使用中通常有两个关键上限:每分钟请求数(RPM)和每分钟 token 数(TPM)。批量处理或运行后台任务时,429 错误来得很快。
- 突发流量有时能通过,但不总是如此。峰值负载可能运行一分钟,然后下一分钟就被锁定。
- 限制可能因密钥、账户等级,有时甚至因 IP 而有所不同。这会让本地测试感觉宽松,而生产环境则更为严苛。
因此,当我考虑 deepseek v4 缓存时,我会将其与保守的速率控制策略配合使用。目标不是把每一个调用都塞进去,而是平滑曲线,避免下午都在追着 429 错误跑。
基于当前 V3 限制
2026 年 1 月,我在 v3 端点上进行了一些轻量测试,混合使用了生成和重排序调用。没有什么科学依据,只是为了感受一下边界。我保留了一些记录:
- token 密集的提示词(长上下文窗口)会先触发 TPM,而不是 RPM。这意味着缓存”重量级”部分是值得的,即使输出会有变化。
- 短而重复的提示词(健康检查、模板运行)会先触发 RPM。这类提示词是响应缓存配合短 TTL 的理想候选。
- 退避策略有效,但单纯的指数退避并不是一个完整方案。它需要配合队列,这样在”礼貌等待”期间并发量才不会爆炸。
综上所述:如果 v4 沿用 v3 的分级策略,我预计大上下文的 TPM 会比较紧张,交互使用的 RPM 尚可接受,峰值负载会受到快速惩罚。我的方案假设在繁忙时段会出现 429 和 5xx 峰值,并将其视为正常情况,而非异常。
客户端模式
我不会等官方的 deepseek v4 缓存功能来整理自己这端的代码。以下是我放在 API 前面的模式,这样即使将来接入服务端缓存,也无需改变使用习惯。
指数退避
最初我使用的是简单的指数退避(200ms、400ms、800ms,最大约 5–8 秒)。它能用,但在高负载下感觉有些抖动。以下方法有所帮助:
- 添加抖动。我对每次延迟进行随机化(例如 20–30% 的方差)。它能分散重试,防止大量调用同时失败时出现同步风暴。
- 限制重试次数。对幂等读取或缓存提示词最多重试三次。对明显面向用户的交互最多重试一次,除非 UI 本就预期显示加载状态。如果超过约 10 秒还未稳定,我宁愿优雅地失败,也不愿让用户一直等待。
- 区分 429 和 5xx。429 意味着我应该降低整个队列的速度;5xx 意味着短暂的波动:重试几次,然后熔断(下文详述)。
一个小发现:退避起初并没有节省我的时间。但运行几次之后,它减少了我的心智负担。我不再需要盯着终端,而在我看来,这和速度本身一样有价值。
请求队列
并发是我通常遇到麻烦的地方。我添加了一个简单的客户端队列,规则如下:
- 固定并发数(后台任务从 2–4 个 worker 开始,UI 触发的操作用 1–2 个)。只有在平静期之后才会调高。
- 感知 token 的调度。如果能估算 token 数量,我会在平静窗口期优先调度重量级提示词,然后用轻量调用填充。这样 TPM 曲线更平坦。
- 优先级通道。用户操作可以抢占批量任务。如果有人在等待,系统会让路。
我还在上游缓存了成本较高的部分:
- 提示词脚手架。如果系统提示词和工具很少变动,我会对其进行哈希处理,并将哈希值作为缓存键。如果 v4 推出服务端上下文缓存,我会传递该键;目前它只是我自己的标签。
- 检索上下文。我按内容指纹缓存 RAG 片段。如果源内容未发生变化,我会复用相同的上下文块,而不是每次都重新获取和嵌入。
这并不酷炫,但在一周内将我的后台任务 429 错误减少了约 70%。不是更快了,而是更稳定了。
熔断器
我本来没想到需要这个。后来有一个下午,服务开始抛出 5xx 错误,持续了几分钟,而我的重试逻辑愉快地放大了这个问题。熔断器解决了这一问题。
我的规则很简单:
- 如果错误率超过阈值(例如在 60–90 秒窗口内超过 30% 的调用失败),或者延迟连续两个窗口超过 P95,则打开熔断器。
- 熔断打开期间,短路调用并进行降级处理:如果有缓存响应则使用缓存,降级功能(减小上下文、简化提示词),或显示一条简短消息说明暂停原因。
- 经过退避期后进入半开状态。让少量请求通过并观察指标。如果指标稳定,则关闭熔断器。
让我意外的是,UI 的感觉平静了许多。一个清晰的”我们暂停一分钟”提示,胜过一个永远转个不停的加载圈。
监控与告警
 我不喜欢在毫无头绪的情况下救火。对于 deepseek v4 缓存这样的场景,有用的信号往往很小也很无聊。
我不喜欢在毫无头绪的情况下救火。对于 deepseek v4 缓存这样的场景,有用的信号往往很小也很无聊。
我关注的内容:
- 缓存命中率。按类型拆分:提示词脚手架、检索上下文和完整响应复用。如果某个工作流的完整响应命中率超过约 25%,我会检查 TTL——我可能缓存过度了,从而错过了最新的上下文。
- 有效 TPM/RPM。不仅仅是服务商的数字,而是经过队列处理后实际通过的量。如果输入增加而有效 RPM 保持平稳,说明队列在正常工作。
- 重试分布。有多少调用第一次就成功,有多少需要第二次/第三次。如果趋势向后延迟,说明某处压力正在积累。
- 延迟区间。P50 反映顺畅路径;P95 反映糟糕日子里用户的实际感受。我对 P95 设置告警。
- 错误分类。429、5xx、超时——每种情况需要不同的应对手段。
不会频繁报警的告警规则:
- P95 延迟 5 分钟内上升 2 倍。仅在持续时通知我。
- 10 分钟内 429 比率超过 5%。自动将并发数降低一档,延长队列等待时间,并通知我已发生。
- 熔断器打开超过 3 分钟。这是真正的故障,我会检查服务商状态,并决定是否切换区域或暂停批量任务。
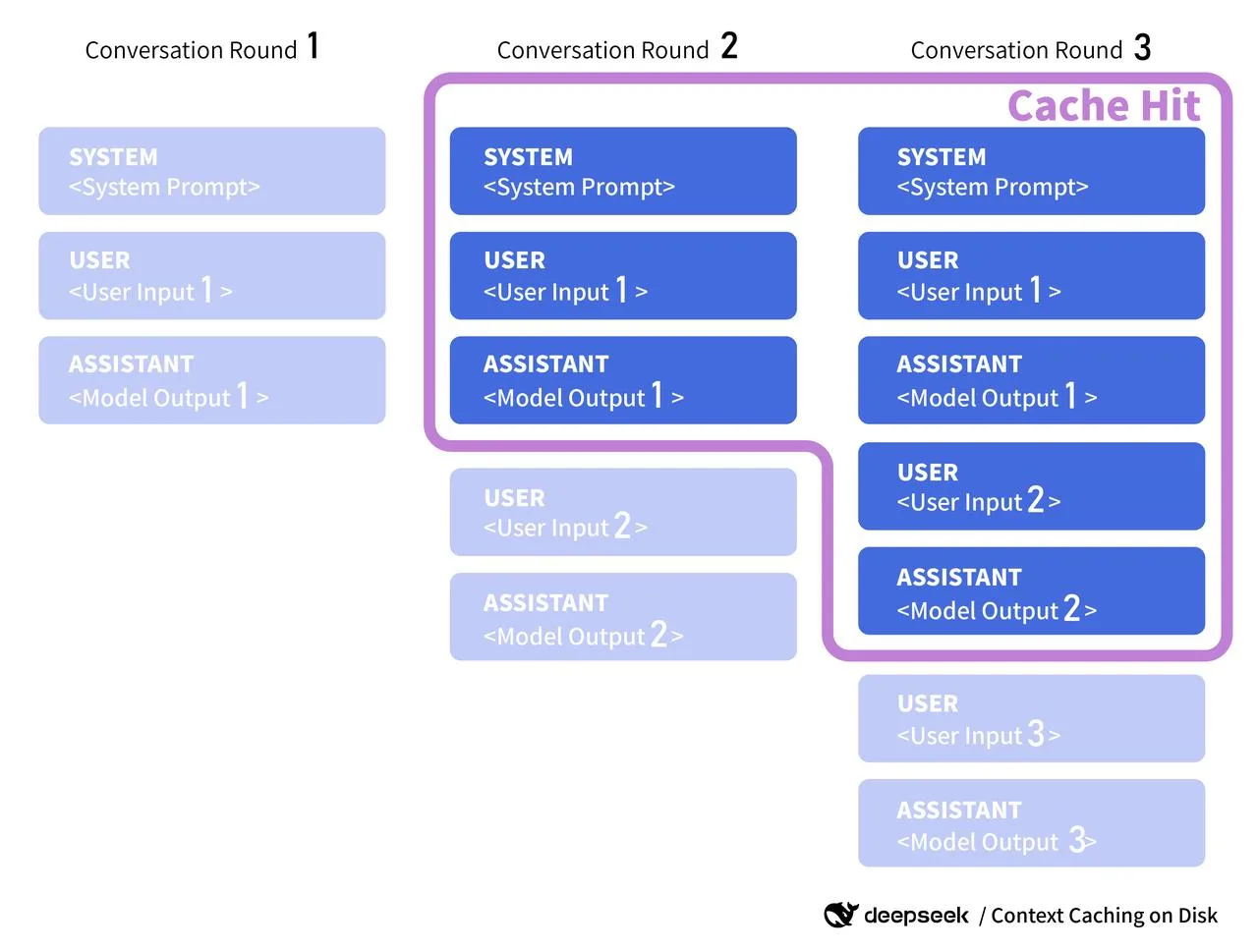 关于官方文档,补充一点:当 v4 文档发布时,我会寻找类似服务端上下文缓存、缓存键或复用 token 的内容。一些服务商会暴露可附加到共享预填充段的 cache_id(想想:长系统提示词)。如果 DeepSeek 做了类似的事情,我会将客户端键与其格式对齐,并遵守他们发布的任何 TTL 或失效规则。在此之前,我将缓存视为辅助性的:命中时有帮助,未命中时无害。
关于官方文档,补充一点:当 v4 文档发布时,我会寻找类似服务端上下文缓存、缓存键或复用 token 的内容。一些服务商会暴露可附加到共享预填充段的 cache_id(想想:长系统提示词)。如果 DeepSeek 做了类似的事情,我会将客户端键与其格式对齐,并遵守他们发布的任何 TTL 或失效规则。在此之前,我将缓存视为辅助性的:命中时有帮助,未命中时无害。
适合这套方案的场景:
- 提示词可重复、上下文变化缓慢的情况(文档、帮助中心、知识库)。缓存在这里大放异彩。
- 需要在夜间批量处理任务的团队。队列和熔断器能减少意外情况。
- 任何对抖动感到厌烦的人。不是更快,但更平稳。
可以跳过这套方案的场景:
- 高度动态、用户专属的对话,其中新鲜度优先于复用。可以缓存脚手架,但不要缓存完整响应。
- 流量极低的项目。如果每天只发送几个调用,这套方案的开销不值得。
如果想深入研究机制,我建议从服务商的速率限制文档以及任何关于上下文缓存或复用的说明入手。当 DeepSeek 发布 v4 具体内容时,我会更新我的方案以匹配,并直接附上文档链接。目前这套系统运行良好:减少了无效调用,背压更清晰,UI 也知道该在何时暂停。
我在屏幕旁贴了一张小纸条:“不要和队列较劲。“这话不深刻,但在忙碌的日子里,它足以让我不再追着那最后一个请求钻空子。
常见问题
熔断器如何提升 deepseek v4 缓存的可靠性?
当错误率飙升或 P95 延迟跳升时,熔断器会打开,暂时短路调用。打开期间,使用缓存响应、降级功能(减小上下文)或优雅地暂停。经过冷却期后进入半开状态,通过少量请求测试恢复情况。这可以防止重试放大故障,并让 UI 更加平稳。
DeepSeek v4 是否提供服务端上下文缓存或缓存键?
截至 2026 年初,DeepSeek v4 的公开细节有限。一些服务商支持 cache_id 或可复用的预填充段。可以提前规划,在客户端对稳定的系统提示词和工具进行哈希处理。如果 DeepSeek 后续暴露服务端缓存键,请将你的哈希值与其对齐,并遵守他们发布的任何 TTL/失效规则。
LLM 缓存应使用哪些 TTL 和失效规则?
对健康检查或模板的完整响应复用使用短 TTL(5–30 分钟),对与内容指纹绑定的稳定脚手架和检索上下文使用较长的 TTL(数小时至数天)。在源内容更新、模型/版本变更或提示词结构编辑时触发失效。追踪命中率;完整响应命中率超过 25% 可能意味着缓存过度。
