Доступность GPT-5.5 API: что нужно планировать командам
GPT-5.5 объявлен, но доступ к API ещё не полностью открыт. Вот что команды могут планировать уже сейчас и что ещё требует проверки.

Прошлую пятницу я потратила на переключение рабочего процесса Codex на GPT-5.5, а в понедельник объясняла двум клиентам, почему решение о переходе сложнее, чем предполагают заголовки релиза. Моё имя фигурирует во многих документах «стоит ли мигрировать?» в WaveSpeedAI, так что я — Дора, тот человек, который заставляет команды ждать две недели перед тем, как одобрить замену модели. API работает. Это та часть, которую большинство материалов освещает правильно — и на этом останавливается. Я хочу написать о десяти днях после запуска, когда «доступно» превращается в «реально интегрировано», и о том, на чём спотыкается большинство команд, с которыми я работаю.
Это заметка для планирования, а не туториал. Если вы пришли за примерами curl — официальная документация справится с этим лучше меня.
Где сегодня доступен GPT-5.5
Статус развёртывания в ChatGPT и Codex
GPT-5.5 стал доступен 23 апреля 2026 года для пользователей Plus, Pro, Business и Enterprise в ChatGPT и Codex, при этом GPT-5.5 Pro ограничен уровнями Pro, Business и Enterprise. В Codex модель поставляется с контекстным окном 400K токенов и режимом Fast, который работает в 1,5 раза быстрее при стоимости в 2,5 раза выше — подробности чётко изложены в официальном объявлении о запуске GPT-5.5 на OpenAI. В первый день запуск охватил только пользовательские поверхности. Хочу это подчеркнуть, потому что половина тикетов, которые я видела на прошлой неделе, с самого начала предполагала паритет с API.
Что OpenAI говорит о доступности API
Часть, которую ранний пресс-цикл упустил: доступ к API появился на день позже — 24 апреля 2026 года. Обе модели — gpt-5.5 и gpt-5.5-pro — теперь доступны в API Responses и Chat Completions, что подтверждено в собственной документации модели GPT-5.5 от OpenAI. Контекстное окно на поверхности API составляет 1M токенов, что отличается от потолка Codex в 400K. Две поверхности, два ограничения — легко перепутать, и стоит записать это до того, как ваши инженеры успеют. Так что вопрос больше не «когда моя команда сможет использовать это». Он звучит так: «стоит ли нам это делать, и что нужно проверить в первую очередь».
Что команды могут безопасно планировать до интеграции API
Критерии оценки и подготовка к миграции
Я не рекомендую миграцию в тот же день. Вот что я бы зафиксировала первым делом.
Создайте небольшой тестовый стенд для вашей текущей модели. Пять-десять репрезентативных промптов из реальной рабочей нагрузки, оценённых по параметрам, которые действительно важны для вас: корректность, стоимость токенов, задержка, частота повторных запросов. Запустите GPT-5.4 и GPT-5.5 параллельно с одними и теми же промптами, одинаковыми настройками температуры и одинаковыми определениями инструментов. Независимые бенчмарки, такие как сравнение, опубликованное на LLM Stats, показывают, что GPT-5.5 опережает на 9 из 10 общих тестов, но показывает лишь незначительный выигрыш на SWE-Bench Pro. Вывод: обновление реально, но не даёт равномерного улучшения. Ваша рабочая нагрузка решает.
Определите резервный сценарий сейчас, а не после первого 429-го. Исторически новые релизы моделей выходят с более жёсткими ограничениями по скорости в первые 30 дней. Подключите GPT-5.4 в качестве резерва до того, как переключите хотя бы один производственный запрос. Я видела, как две команды пропустили этот шаг и поплатились за это во время всплеска трафика в день запуска.
Вопросы для закупок, безопасности и разработки
Несколько вопросов, на которые мне пришлось отвечать на этой неделе:
- Цена выросла вдвое. Стандартная ставка составляет $5 за 1M входных токенов и $30 за 1M выходных, согласно официальной странице цен OpenAI. Pro — $30 / $180. Заявления об эффективности токенов частично компенсируют это на рабочих нагрузках Codex, но на большинстве других рабочих нагрузок ожидайте ощутимого роста расходов.
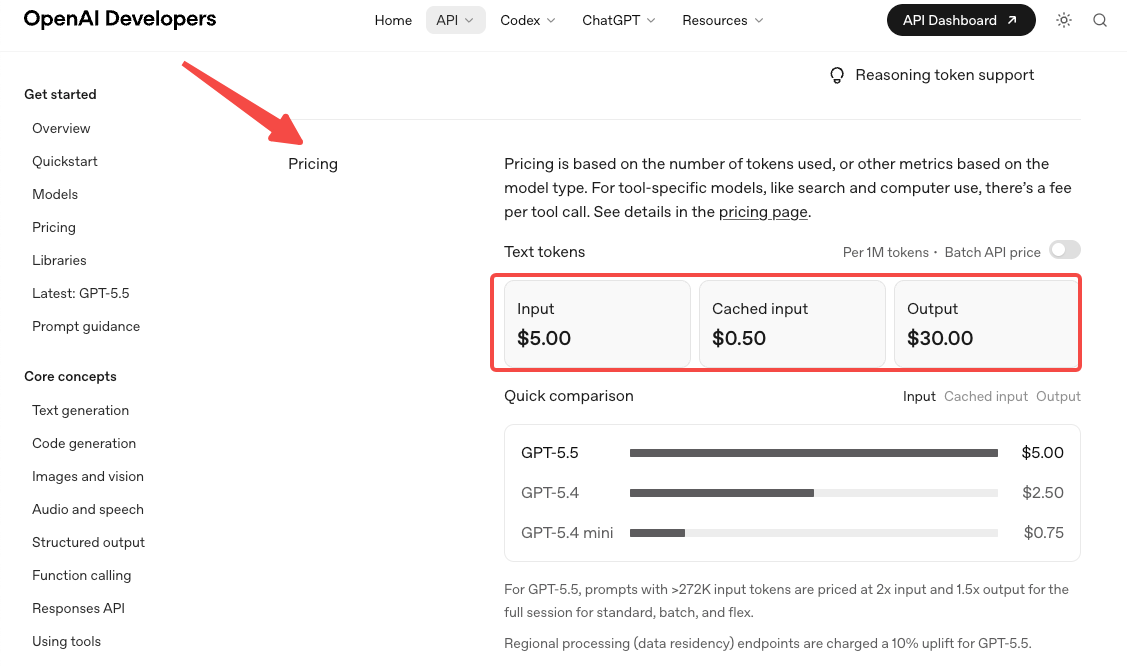
- Ценообразование для длинного контекста меняется при 272K. Выше этого порога входные данные стоят в 2 раза дороже, а выходные — в 1,5 раза для всей сессии. Если ваш рабочий процесс регулярно превышает 272K токенов, рассчитайте стоимость дважды — один раз ниже порога, один раз выше. Это помогает выявить команды, которые строились вокруг уровневой структуры GPT-5.4 и предполагали, что новая модель её унаследует.
- Службе безопасности необходимо прочитать системную карту. GPT-5.5 поставляется с более строгими классификаторами кибербезопасности, задокументированными в системной карте GPT-5.5. Некоторые легитимные рабочие нагрузки будут первоначально блокироваться, пока OpenAI их настраивает. Стоит сообщить об этом всем, кто запускает инструменты безопасности, конвейеры анализа кода или рабочие процессы red-team через API.
Что ещё необходимо проверить перед использованием в продакшне
Идентификаторы моделей, ограничения скорости, цены и поддержка инструментов
Я бы проверяла в следующем порядке:
1.Идентификаторы моделей и снимки. Зафиксируйтесь на снимке, а не на псевдониме. Псевдонимы меняются; снимки — нет. Проверьте доступный список на странице модели GPT-5.5 перед тем, как жёстко прописывать что-либо в клиенте.
2.Ограничения скорости для вашего уровня. Система уровней OpenAI повышает уровень автоматически на основе расходов, но ограничения в день запуска могут быть жёстче, чем те, которыми сегодня пользуется GPT-5.4. Я бы начала с документации OpenAI по ограничениям скорости и перед тем, как предполагать наличие запаса, стоит провести синтетический нагрузочный тест на вашем текущем уровне.
3.Поведение инструментов и структурированного вывода. Вызов функций, веб-поиск и структурированные выходные данные работают, но точные схемы и взаимодействия с режимом рассуждений требуют дымового теста на ваших реальных определениях инструментов. Я наблюдала, как настройки усилий рассуждений меняют поведение при повторных запросах так, что это не проявляется до тех пор, пока вы не столкнётесь с производственным трафиком.
Пропускная способность и детали корпоративного развёртывания
Для тех, кто работает с серьёзными объёмами: Batch и Flex работают по половинной стандартной ставке, Priority — по 2,5-кратной. Вывод: если ваша работа допускает асинхронность, Batch на GPT-5.5 стоит столько же за токен, сколько GPT-5.4 по стандарту. Это и есть реальный арбитраж, скрытый в этом релизе, и почти никто из тех, с кем я разговаривала, ещё не учёл его. Разбивка цен GPT-5.5 на apidog разбирает рабочие примеры лучше, чем я здесь смогу.
Прямая интеграция с провайдером vs готовность на основе платформы
Я работаю на платформе, которая агрегирует доступ к моделям, так что моя предвзятость очевидна. Но структурный аргумент остаётся тем же вне зависимости от того, чью платформу вы используете: когда один провайдер выпускает модель с удвоенной ценой в первый же день, аргументы в пользу логики маршрутизации становятся сильнее, а не слабее.
Прямая интеграция с провайдером выглядит так: переписать клиент, перетестировать промпты, пересчитать модель затрат — и повторить для каждого провайдера. Платформы с несколькими моделями — включая WaveSpeedAI, но и другие тоже — позволяют менять модели одним изменением конфигурации. Компромисс в том, что вы добавляете слой между собой и источником. Для высокочастотных команд, выпускающих продукт ежедневно, этот слой обычно стоит абстракции. Для команды, запускающей одну модель на одной рабочей нагрузке с малым объёмом — нет.
В любом случае я бы планировала настройку маршрутизации. Премиальные запросы — к GPT-5.5, стандартный трафик — к GPT-5.4 или другой фронтирной модели. Этот паттерн сам по себе обычно снижает расходы на 40–60% по сравнению с настройками по умолчанию с одной моделью, независимо от того, на каком провайдере вы сосредоточены.
Часто задаваемые вопросы
Запущен ли GPT-5.5 в API?
Да, начиная с 24 апреля 2026 года. Запуск 23 апреля охватил только ChatGPT и Codex; API появился на день позже. Обе модели — gpt-5.5 и gpt-5.5-pro — доступны в эндпоинтах Responses и Chat Completions с контекстным окном 1M токенов.
Что командам следует проверить перед началом интеграции?
Влияние на цену при вашем реальном соотношении токенов, потолки ограничений скорости на вашем текущем уровне, подключённый и протестированный откат на GPT-5.4, а также короткий тестовый стенд, сравнивающий две модели на вашей реальной рабочей нагрузке. Зафиксируйтесь на ID снимка, а не на псевдониме.
Стоит ли подождать вместо использования GPT-5.4?
Зависит от рабочей нагрузки. Для агентных задач кодирования и работы с компьютером GPT-5.5 показывает значительный прирост, как задокументировано в материале TechCrunch о запуске. Для рабочих нагрузок, где GPT-5.4 уже соответствует вашей планке качества, удвоенная цена за токен трудно оправдывается без измеримого улучшения.
Как командам подготовиться к быстрому развёртыванию API?
Создайте тестовый стенд сейчас, маршрутизируйте через слой абстракции, если ещё не сделали этого, и исходите из того, что ограничения скорости будут ужесточаться прежде, чем ослабнут. Не пополняйте большие кредитные балансы заранее — цены на это поколение ещё меняются.
Означает ли удвоенная цена удвоение счетов?
Нет, но близко к тому. Прирост эффективности токенов на рабочих нагрузках Codex снижает реальные счета до уровня ниже 2x. На других рабочих нагрузках ожидайте значений, близких к номинальным. Пакетная обработка по половинной ставке — это рычаг, который стоит задействовать в первую очередь.
Заключение
API работает. Цены изменились. Ограничения скорости ещё устанавливаются. Всё это не означает, что нужно торопиться. Это означает, что окно для планирования, на которое рассчитывало большинство команд, закрылось быстрее, чем ожидалось, и теперь задача — верификация, а не ожидание.
Я провожу собственную миграцию в течение следующих двух недель. Останется ли GPT-5.5 в моём маршрутизации по умолчанию после этого — пока не знаю. Для этого и нужен тестовый стенд.
Продолжение следует.
Похожие статьи
Представляем ByteDance Seedance 2.0 Mini на WaveSpeedAI

Claude Fable 5: резервный переход на Opus 4.8 — объяснение

GLM-5.2 API: цены, контекст 1M и маршрутизация в продакшене

Цены на GPT-5.4 Mini: стоимость входных, кэшированных и выходных токенов

MAI-Image-2.5 API: что нужно знать разработчикам
