Кэширование контекста DeepSeek V4: сократите расходы на 90% при повторяющихся запросах
Цены DeepSeek при попадании в кэш на 90% ниже. Узнайте, как структурировать запросы для максимального использования кэша.

Привет, я Дора. На прошлой неделе меня подвела одна мелочь: я запустила один и тот же промпт три раза, потому что не могла вспомнить, где оставила последний черновик. Результат почти не изменился, зато лимит запросов сократился. Именно это подтолкнуло меня к идее DeepSeek v4 кэша.
 Я не жду чудес. Мне просто нужно меньше лишних вызовов, стабильная задержка и небольшой запас под лимитами. Поскольку v4 пока слабо задокументирован, я начала с того, что изучила практику работы с v3 и похожими API, а затем выработала несколько клиентских паттернов, которые мне подходят. Если DeepSeek выпустит официальный кэш для v4, я хочу быть готова подключить его, не переделывая весь рабочий процесс.
Я не жду чудес. Мне просто нужно меньше лишних вызовов, стабильная задержка и небольшой запас под лимитами. Поскольку v4 пока слабо задокументирован, я начала с того, что изучила практику работы с v3 и похожими API, а затем выработала несколько клиентских паттернов, которые мне подходят. Если DeepSeek выпустит официальный кэш для v4, я хочу быть готова подключить его, не переделывая весь рабочий процесс.
Доступно на WaveSpeedAI — прозрачная цена за токен, OpenAI-совместимый endpoint. DeepSeek V3.2 API → · DeepSeek R1 API →
Вот как я подхожу к вопросу кэша deepseek v4: исходить из наличия лимитов, кэшировать то, что повторяется, спокойно делать повторные попытки и следить за нужными метриками.
Ожидаемые лимиты запросов
Чёткой публичной таблицы по v4 я пока не нашла, поэтому отнеслась к этому как к пересадке в аэропорту: рассчитывать на жёсткое расписание и готовиться к задержкам.
Из работы с DeepSeek v3 (и похожими провайдерами) я знаю несколько простых вещей:
- Обычно есть два ограничения, которые важны на практике: запросы в минуту (RPM) и токены в минуту (TPM). Ошибки 429 появляются быстро при пакетной обработке или фоновых задачах.
- Всплески иногда проходят — до поры до времени. Пиковые нагрузки могут работать минуту, а потом намертво заблокировать следующую.
- Лимиты могут отличаться в зависимости от ключа, уровня аккаунта и иногда IP. Из-за этого локальные тесты кажутся щедрыми, а продакшн — менее прощающим.
Поэтому, думая о кэше deepseek v4, я сочетаю его с консервативной обработкой лимитов. Цель не в том, чтобы пропустить максимум вызовов, а в том, чтобы сгладить кривую и не тратить послеполудни в погоне за ошибками 429.
На основе текущих лимитов V3
В январе 2026 года я провела несколько лёгких тестов, смешивая вызовы генерации и ранжирования на эндпоинтах v3. Ничего научного — просто достаточно, чтобы почувствовать границы. Вот несколько заметок, которые я сохранила:
- Промпты с большим количеством токенов (длинные контекстные окна) упираются в TPM раньше, чем в RPM. Это значит, что кэширование тяжёлых частей окупается, даже если результаты меняются.
- Короткие повторяющиеся промпты (проверки работоспособности, шаблонные запуски) упираются в RPM первыми. Это идеальные кандидаты для кэша ответов с коротким TTL.
- Бэкофф работает, но экспоненциальный бэкофф сам по себе — не план. Ему нужна очередь, чтобы не взрываться от параллельных запросов во время «вежливого ожидания».
Всё это к тому, что если v4 унаследует уровни v3, я ожидаю жёсткий TPM для больших контекстов, умеренный RPM для интерактивного использования и быстрые штрафы при пиковых нагрузках. Моя конфигурация предполагает, что во время загруженных периодов будут всплески 429 и 5xx, и относится к ним как к норме, а не к исключению.
Клиентские паттерны
Я не жду официального кэша deepseek v4, чтобы навести порядок на своей стороне. Вот паттерны, которые я поставила перед API, чтобы впоследствии можно было подключить кэш провайдера, не меняя своих привычек.
Экспоненциальный бэкофф
Первый вариант использовал простой экспоненциальный бэкофф (200 мс, 400 мс, 800 мс, максимум около 5–8 с). Работал, но под нагрузкой ощущался нервно. Что помогло:
- Добавить джиттер. Я немного рандомизирую каждую задержку (например, дисперсия 20–30%). Это распределяет повторные попытки и предотвращает синхронные шторма, когда сразу много вызовов дают сбой.
- Ограничить попытки. Три попытки для идемпотентных чтений или кэшированных промптов. Одна попытка для очевидно пользовательских взаимодействий, если только UI не ожидает спиннера. Если это занимает больше ~10 секунд, я предпочту изящно завершить с ошибкой, чем удерживать пользователя в заложниках.
- Различать 429 и 5xx. Ошибка 429 говорит о том, что нужно замедлить всю очередь. Ошибка 5xx указывает на кратковременный сбой: я сделаю пару повторных попыток, а потом разомкну цепь (об этом ниже).
Небольшое наблюдение: бэкофф поначалу не сэкономил мне время. Что он сделал после нескольких запусков — снизил умственную нагрузку. Я перестала следить за терминалом, а в моём мире это стоит столько же, сколько скорость.
Очередь запросов
Параллелизм — это то, где я обычно попадаю в беду. Я добавила простую клиентскую очередь со следующими правилами:
- Фиксированный параллелизм (начинать с 2–4 воркеров для фоновых задач, 1–2 для действий, инициированных пользователем). Увеличиваю только после тихого периода.
- Планирование с учётом токенов. Если я могу оценить количество токенов, то в спокойные периоды сначала планирую тяжёлые промпты, а потом заполняю лёгкими вызовами. Это сглаживает TPM.
- Приоритетные очереди. Действия пользователя могут вытеснять пакетные задания. Если кто-то ждёт, система уступает дорогу.
Я также кэширую дорогостоящие части выше по потоку:
- Каркасы промптов. Если системный промпт и инструменты меняются редко, я хеширую их и использую хэш как ключ кэша. Если v4 предоставит серверный кэш контекста, я передам этот ключ туда — а пока это просто мой собственный тег.
- Извлечённый контекст. Я кэширую чанки RAG по отпечатку содержимого. Если источник не изменился, я переиспользую тот же блок контекста, а не извлекаю и не встраиваю его каждый раз заново.
Это не гламурно, но за неделю снизило количество 429 при фоновых задачах примерно на 70%. Не быстрее, просто стабильнее.
Автоматический выключатель
Я не ожидала, что он понадобится. Но однажды днём сервис начал выдавать 5xx несколько минут, и моя логика повторных попыток радостно усилила это. Автоматический выключатель исправил ситуацию.
Мои правила просты:
- Разомкнуть цепь, если частота ошибок превышает порог (например, >30% вызовов завершаются ошибкой за 60–90 секунд) или если задержка превышает P95 в течение двух последовательных окон.
- Пока цепь разомкнута, короткое замыкание вызовов с откатом: отдавать кэшированные ответы, если доступны, деградировать функции (меньше контекста, более простые промпты) или показывать спокойное сообщение с объяснением паузы.
- Перейти в полузамкнутое состояние после периода бэкоффа. Пропустить небольшой поток запросов и следить за метриками. Если они стабильны — замкнуть цепь.
Меня удивило то, насколько спокойнее стал выглядеть интерфейс. Чёткое «мы делаем паузу на минуту» лучше, чем спиннер, который крутится вечно.
Мониторинг и алерты
 Мне не нравится бороться с пожарами вслепую. Для такой вещи, как кэш deepseek v4, полезные сигналы небольшие и скучные.
Мне не нравится бороться с пожарами вслепую. Для такой вещи, как кэш deepseek v4, полезные сигналы небольшие и скучные.
За чем я слежу:
- Процент попаданий в кэш. Разделённый по типам: каркас промпта, извлечённый контекст и повторное использование полного ответа. Если попадания для полных ответов превышают ~25% для рабочего процесса, я проверяю TTL — возможно, я кэширую слишком много и упускаю свежий контекст.
- Эффективный TPM/RPM. Не только числа провайдера, но и то, что проходит через очередь. Если эффективный RPM остаётся стабильным при росте входящего трафика, очередь делает своё дело.
- Распределение повторных попыток. Сколько вызовов успешно проходят с первой попытки, а сколько со второй/третьей. Смещение в сторону поздних повторных попыток означает, что где-то нарастает давление.
- Диапазоны задержек. P50 говорит мне о счастливом пути; P95 говорит, что чувствуют пользователи в плохой день. Я отправляю алерты по P95.
- Таксономия ошибок. 429 против 5xx против таймаутов. Каждую из них исправляют разные рычаги.
Алерты, которые не кричат:
- P95-задержка выросла в 2 раза за 5 минут. Уведомить только если это сохраняется.
- Частота 429 выше 5% за 10 минут. Автоматически снижаю параллелизм на один шаг и увеличиваю ожидание в очереди; сообщаю, что это произошло.
- Цепь разомкнута более 3 минут. Это настоящий инцидент. Я проверю статус провайдера и решу, стоит ли переключить регион или поставить пакетные задания на паузу.
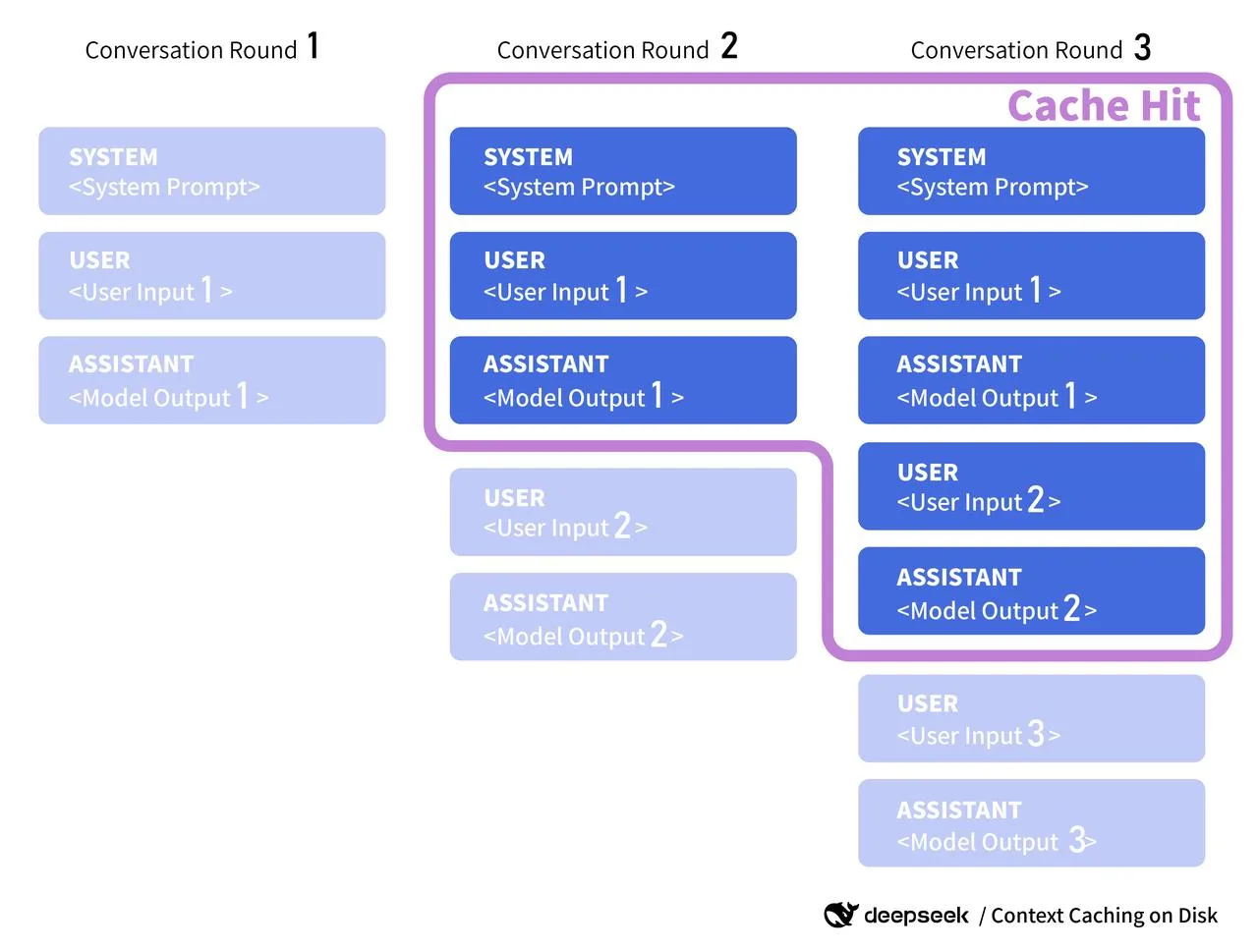 Несколько слов об официальной документации: когда появятся документы по v4, я буду искать что-то вроде серверного кэширования контекста, ключей кэша или токенов повторного использования. Некоторые провайдеры предоставляют cache_id, который можно прикрепить к общему сегменту предзаполнения (например, длинный системный промпт). Если DeepSeek сделает что-то подобное, я приведу свои клиентские ключи в соответствие с их форматом и буду соблюдать любые опубликованные правила TTL или инвалидации. До тех пор я считаю свой кэш рекомендательным: полезным при попаданиях, безвредным при промахах.
Несколько слов об официальной документации: когда появятся документы по v4, я буду искать что-то вроде серверного кэширования контекста, ключей кэша или токенов повторного использования. Некоторые провайдеры предоставляют cache_id, который можно прикрепить к общему сегменту предзаполнения (например, длинный системный промпт). Если DeepSeek сделает что-то подобное, я приведу свои клиентские ключи в соответствие с их форматом и буду соблюдать любые опубликованные правила TTL или инвалидации. До тех пор я считаю свой кэш рекомендательным: полезным при попаданиях, безвредным при промахах.
Для кого эта конфигурация:
- Люди с повторяющимися промптами и медленно меняющимся контекстом (документация, центры помощи, базы знаний). Кэш здесь себя проявляет ярко.
- Команды, запускающие пакетные задания ночью. Очередь и автоматический выключатель снижают количество неожиданностей.
- Все, кто устал от нестабильности. Не быстрее, но спокойнее.
Кому можно пропустить:
- Высокодинамичные, пользовательские чаты, где актуальность важнее повторного использования. Кэшировать каркасы — да, но не полные ответы.
- Проекты с очень низким трафиком. Если вы отправляете несколько вызовов в день, накладные расходы того не стоят.
Если хотите углубиться в механику, я бы начала с документации провайдера по лимитам запросов и любым упоминаниям кэширования контекста или повторного использования. Когда DeepSeek опубликует детали v4, я обновлю свою конфигурацию и приведу прямые ссылки на документацию. Пока система держится: меньше лишних вызовов, более чёткое обратное давление и интерфейс, который как будто знает, когда нужно сделать паузу.
Я держу у экрана небольшую записку: «Не борись с очередью». Это не глубокая мысль, но в загруженные дни её достаточно, чтобы не гнаться за ещё одним запросом через закрывающееся окно.
Часто задаваемые вопросы
Как автоматические выключатели повышают надёжность при использовании кэша deepseek v4?
Автоматический выключатель срабатывает при резком росте частоты ошибок или скачке P95-задержки, временно прерывая вызовы. Пока он разомкнут, отдавайте кэшированные ответы, деградируйте функции (меньший контекст) или делайте изящную паузу. После периода охлаждения переходите в полузамкнутое состояние с небольшим потоком для проверки восстановления. Это предотвращает усиление сбоев через повторные попытки и успокаивает интерфейс.
Предоставляет ли DeepSeek v4 серверное кэширование контекста или ключи кэша?
По состоянию на начало 2026 года публичные подробности о DeepSeek v4 ограничены. Некоторые провайдеры поддерживают cache_id или повторно используемые сегменты предзаполнения. Подготовьтесь заранее, хэшируя стабильные системные промпты и инструменты на стороне клиента. Если DeepSeek впоследствии предоставит серверные ключи кэша, приведите свои хэши в соответствие и соблюдайте любые опубликованные правила TTL и инвалидации.
Какие TTL и правила инвалидации следует использовать для кэширования LLM?
Используйте короткие TTL (5–30 минут) для повторного использования полных ответов при проверках работоспособности или шаблонах, и длинные TTL (часы–дни) для стабильных каркасов и извлечённого контекста, привязанного к отпечаткам содержимого. Инвалидируйте при обновлении источника, изменении модели/версии или редактировании схемы промпта. Отслеживайте процент попаданий; >25% попаданий для полных ответов может указывать на избыточное кэширование.
Похожие статьи
Представляем ByteDance Seedance 2.0 Mini на WaveSpeedAI

Claude Fable 5: резервный переход на Opus 4.8 — объяснение
GLM-5.2 API: цены, контекст 1M и маршрутизация в продакшене
Цены на GPT-5.4 Mini: стоимость входных, кэшированных и выходных токенов
MAI-Image-2.5 API: что нужно знать разработчикам