Disponibilidade da API GPT-5.5: O Que as Equipes Devem Planejar
O GPT-5.5 foi anunciado, mas o acesso à API ainda não está totalmente disponível. Veja o que as equipes podem planejar agora e o que ainda precisa ser verificado.

Passei a última sexta-feira redirecionando um fluxo de trabalho do Codex para o GPT-5.5, e depois passei a segunda-feira explicando a dois clientes por que a decisão de implementação é mais complicada do que as manchetes de lançamento sugerem. Meu nome aparece em muitos documentos de “devemos migrar?” na WaveSpeedAI, então eu sou a Dora — a pessoa que faz as equipes esperarem duas semanas antes de aprovar uma troca de modelo. A API está no ar. Essa é a parte que a maioria das coberturas acerta e para por aí. O que eu quero escrever é sobre os dez dias após o lançamento, quando “disponível” se transforma em “realmente integrado”, e onde a maioria das equipes com as quais trabalho está encontrando dificuldades.
Esta é uma nota de planejamento, não um tutorial. Se você veio em busca de exemplos com curl, a documentação oficial faz isso melhor do que eu faria.
Onde o GPT-5.5 Está Disponível Hoje
Status de implementação no ChatGPT e no Codex
O GPT-5.5 entrou em operação em 23 de abril de 2026 para usuários Plus, Pro, Business e Enterprise dentro do ChatGPT e do Codex, com o GPT-5.5 Pro restrito aos planos Pro, Business e Enterprise. No Codex especificamente, o modelo vem com uma janela de contexto de 400K e um modo Rápido que opera 1,5x mais veloz a 2,5x o custo — detalhes que o anúncio oficial de lançamento do GPT-5.5 na OpenAI apresenta de forma clara. O lançamento cobriu apenas as superfícies para consumidores no primeiro dia. Quero destacar isso porque metade dos chamados que vi na semana passada pressupunha paridade com a API desde o início.
O que a OpenAI diz sobre a disponibilidade da API
A parte que o ciclo de imprensa inicial perdeu: o acesso à API chegou um dia depois, em 24 de abril de 2026. Tanto gpt-5.5 quanto gpt-5.5-pro estão agora expostos nas APIs de Respostas e Completions de Chat, confirmado na própria documentação de modelos GPT-5.5 da OpenAI. A janela de contexto é de 1M de tokens na superfície da API, distinta do limite de 400K do Codex. Duas superfícies, dois limites — fácil de confundir, e vale a pena anotar antes que seus engenheiros o façam. Portanto, a questão não é mais “quando minha equipe pode usar isso”. É “devemos usar, e o que verificamos primeiro?”
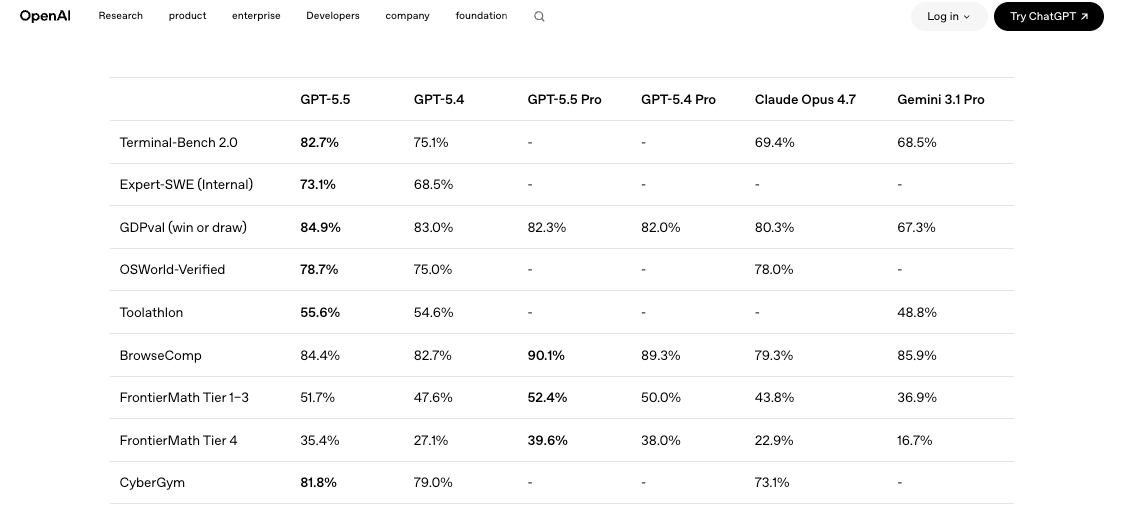
O que as Equipes Podem Planejar com Segurança Antes da Integração com a API
Critérios de avaliação e preparação para migração
Não recomendo uma migração no mesmo dia. Aqui está o que eu consolidaria primeiro.
Construa um pequeno conjunto de avaliação comparado ao seu modelo atual. Cinco a dez prompts representativos da sua carga de trabalho real, pontuados nas dimensões que realmente importam para você: precisão, custo em tokens, latência, taxa de retentativas. Execute o GPT-5.4 e o GPT-5.5 lado a lado, mesmos prompts, mesmas configurações de temperatura, mesmas definições de ferramentas. Benchmarks independentes como a comparação publicada no LLM Stats mostram o GPT-5.5 ganhando em 9 dos 10 benchmarks compartilhados, mas obtendo apenas ganhos marginais no SWE-Bench Pro. Tradução: a atualização é real, mas não é uniformemente melhor. Sua carga de trabalho decide.
Defina agora o seu caminho de fallback, não depois do primeiro erro 429. Novos lançamentos de modelos historicamente chegam com limites de taxa mais restritos nos primeiros 30 dias. Tenha o GPT-5.4 configurado como fallback antes de redirecionar uma única requisição de produção. Já vi duas equipes pularem essa etapa no passado e pagarem caro durante um pico de tráfego no dia do lançamento.
Perguntas para aquisição, segurança e engenharia
Algumas que tive que responder esta semana:
- O preço dobrou. A taxa padrão é de $5 por 1M de tokens de entrada e $30 por 1M de saída, conforme a página oficial de preços da OpenAI. O plano Pro é $30 / $180. As alegações de eficiência de tokens compensam parcialmente isso em cargas de trabalho do Codex, mas na maioria das outras cargas, espere que sua conta aumente materialmente.
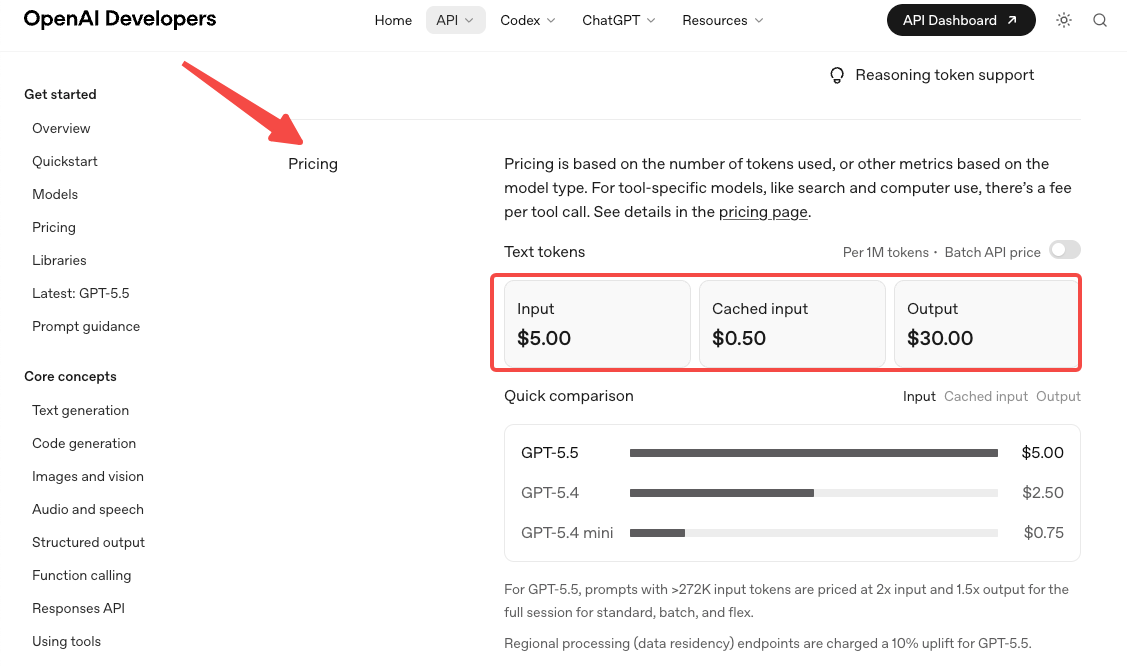
- Os preços de contexto longo mudam a partir de 272K. Acima desse limite, a entrada é 2x e a saída é 1,5x para toda a sessão. Se o seu fluxo de trabalho regularmente ultrapassa 272K tokens, modele seu custo duas vezes — uma abaixo do limite, uma acima. Isso pega as equipes que construíram em torno da estrutura de níveis do GPT-5.4 e assumiram que o novo modelo a herdaria.
- A segurança precisa ler o cartão do sistema. O GPT-5.5 vem com classificadores cibernéticos mais rígidos, documentados no cartão do sistema do GPT-5.5. Algumas cargas de trabalho legítimas serão bloqueadas inicialmente enquanto a OpenAI as ajusta. Vale a pena sinalizar para qualquer pessoa que execute ferramentas de segurança, pipelines de análise de código ou fluxos de trabalho de red-team pela API.
O que Ainda Precisa de Verificação Antes do Uso em Produção
IDs de modelos, limites de taxa, preços e suporte a ferramentas
Eu verificaria nesta ordem:
1.IDs de modelos e snapshots. Bloqueie em um snapshot, não no alias. Aliases mudam; snapshots não mudam. Verifique a lista disponível na página de modelos do GPT-5.5 antes de codificar qualquer coisa diretamente no seu cliente.
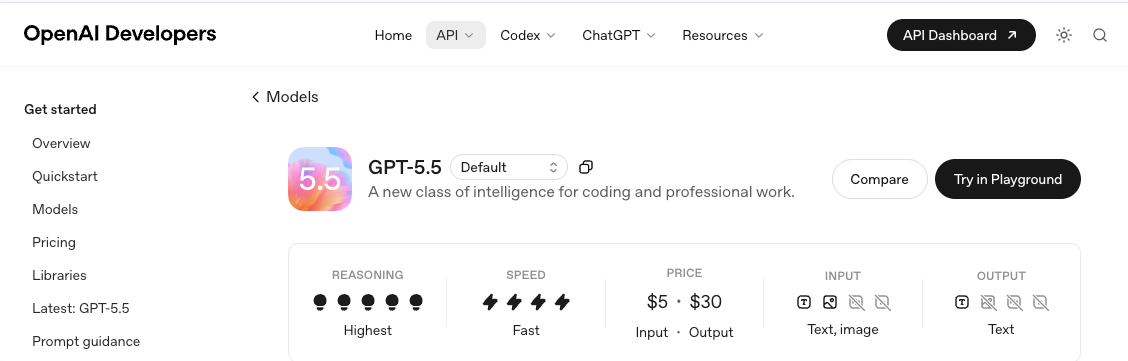
2.Os limites de taxa do seu plano. O sistema de níveis da OpenAI é promovido automaticamente com base nos gastos, mas os limites do dia do lançamento podem ser mais restritos do que os que o GPT-5.4 tem hoje. A documentação de limites de taxa da OpenAI é por onde eu começaria, e vale a pena executar um teste de rajada sintética no seu nível atual antes de presumir que há margem suficiente.
3.Comportamento de ferramentas e saída estruturada. Chamadas de função, pesquisa na web e saídas estruturadas funcionam, mas os esquemas exatos e as interações do modo de raciocínio precisam de um teste de fumaça em relação às suas definições de ferramentas reais. Já vi configurações de esforço de raciocínio alterarem o comportamento de retentativas de formas que não aparecem até você atingir o tráfego de produção.
Throughput e detalhes de implementação corporativa
Para quem executa volumes sérios: Batch e Flex funcionam à metade da taxa padrão, Priority a 2,5x. Tradução: se o seu trabalho tolera assincronicidade, Batch no GPT-5.5 custa o mesmo por token que o GPT-5.4 no padrão. Essa é a arbitragem real escondida neste lançamento, e quase ninguém com quem conversei considerou isso. A análise de preços do GPT-5.5 no apidog apresenta os exemplos práticos melhor do que eu faria aqui.
Planejamento Direto com o Provedor vs. Prontidão Baseada em Plataforma
Trabalho em uma plataforma que agrega acesso a modelos, então meu viés está claro. Mas o argumento estrutural é o mesmo independentemente de qual plataforma você use: quando um único provedor lança um modelo com preço 2x no primeiro dia, o argumento para lógica de roteamento fica mais forte, não mais fraco.
A integração direta com o provedor se parece com isso: reescreva seu cliente, reteste seus prompts, refaça seu modelo de custo, repita por provedor. Plataformas multi-modelo — incluindo a WaveSpeedAI, mas também outras — permitem trocar modelos com uma mudança de configuração. A contrapartida é que você está adicionando uma camada entre você e a fonte. Para equipes de alta frequência que lançam diariamente, essa camada geralmente vale a abstração. Para uma equipe que executa um modelo em uma carga de trabalho a baixo volume, não vale.
Eu planejaria uma configuração de roteamento de qualquer forma. Consultas premium para o GPT-5.5, tráfego rotineiro para o GPT-5.4 ou outro modelo de fronteira — esse padrão por si só tende a reduzir as contas em 40–60% em comparação com os padrões de modelo único, independentemente de qual provedor você centraliza.
Perguntas Frequentes
O GPT-5.5 já foi lançado na API?
Sim, a partir de 24 de abril de 2026. O lançamento em 23 de abril cobriu apenas o ChatGPT e o Codex; a API veio um dia depois. Tanto gpt-5.5 quanto gpt-5.5-pro estão acessíveis nos endpoints de Respostas e Completions de Chat com uma janela de contexto de 1M de tokens.
O que as equipes devem verificar antes de começar o trabalho de integração?
Impacto nos preços na sua combinação real de tokens, limites máximos de taxa no seu nível atual, fallback para o GPT-5.4 configurado e testado, e um pequeno conjunto de avaliação comparando os dois modelos na sua carga de trabalho real. Bloqueie em um ID de snapshot, não no alias.
Vale a pena esperar em vez de usar o GPT-5.4?
Depende da carga de trabalho. Para tarefas de codificação agêntica e uso de computador, o GPT-5.5 mostra ganhos significativos, conforme documentado na cobertura de lançamento do TechCrunch. Para cargas de trabalho onde o GPT-5.4 já atende ao seu padrão de qualidade, o preço por token dobrado é difícil de justificar sem um ganho mensurável.
Como as equipes devem se preparar para uma implementação rápida da API?
Construa o conjunto de avaliação agora, roteie por uma camada de abstração se ainda não o fizer, e assuma que os limites de taxa vão apertar antes de afrouxar. Não pré-pague grandes saldos de crédito — os preços nesta geração ainda estão mudando.
O preço dobrado significa realmente contas dobradas?
Não, mas perto disso. Os ganhos de eficiência de tokens nas cargas de trabalho do Codex trazem as contas reais para abaixo de 2x. Em outras cargas de trabalho, espere algo mais próximo do valor nominal. O processamento em lote à metade da taxa é a alavanca que vale a pena usar primeiro.
Conclusão
A API está no ar. Os preços mudaram. Os limites de taxa ainda estão se estabilizando. Nada disso significa que você deve se apressar. O que isso significa é que a janela de planejamento que a maioria das equipes esperava fechou mais rápido do que o esperado, e o trabalho agora é de verificação, não de espera.
Estou executando minha própria migração nas próximas duas semanas. Se o GPT-5.5 permanecerá no meu roteamento padrão após esse período — ainda não sei. É para isso que serve a avaliação.
Mais atualizações em breve.
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado

API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção

Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída

API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber
