Capacidades de Cibersegurança do Claude Mythos: O Que Equipes de Desenvolvimento e Segurança Precisam Saber
O Claude Mythos levantou sérias preocupações de cibersegurança. Veja o que as alegações vazadas significam para equipes de desenvolvimento e segurança que avaliam este modelo.

“Devemos estar preocupados com isso?” A mensagem da equipe de segurança do cliente chegou no Slack enquanto eu estava revisando opções internas de ferramentas de IA e a história do vazamento da Anthropic apareceu no meu feed.
Disponível na WaveSpeedAI — preços transparentes por token, endpoint compatível com OpenAI. Claude Opus 4.7 API → · Abrir Playground →
Essa pergunta continuou surgindo nas próximas 48 horas. Não de entusiastas de IA, mas de CISOs, líderes de segurança e desenvolvedores que constroem sobre infraestrutura de IA e de repente se encontraram em uma conversa para a qual não estavam preparados.
A história do Mythos não é apenas um anúncio de produto de IA. É um sinal sobre para onde o ambiente de ameaças está se encaminhando, e entender o que está realmente confirmado versus o que é especulação importa mais do que o habitual quando um novo modelo é lançado. E neste artigo, vamos explorar juntos a resposta a essa pergunta.
O Que o Rascunho Vazado Revelou Sobre as Capacidades de Cibersegurança do Mythos
O rascunho do post de blog vazado — parte de quase 3.000 ativos internos expostos — continha duas afirmações marcantes sobre cibersegurança que foram amplamente citadas. As próprias palavras da Anthropic, escritas internamente antes de qualquer anúncio público, descreviam o modelo não lançado (internamente ligado ao nível “Capybara” e referido como Claude Mythos) como “atualmente muito à frente de qualquer outro modelo de IA em capacidades cibernéticas.” Alertava ainda que o modelo “pressagia uma onda iminente de modelos que podem explorar vulnerabilidades de maneiras que superam em muito os esforços dos defensores.”
Uma segunda passagem importante demonstrou cautela incomum: “Ao nos preparar para lançar o Claude Mythos, queremos agir com cautela extra e entender os riscos que ele representa — mesmo além do que aprendemos em nossos próprios testes. Em particular, queremos entender os riscos potenciais de curto prazo do modelo no âmbito da cibersegurança — e compartilhar os resultados para ajudar os defensores cibernéticos a se prepararem.”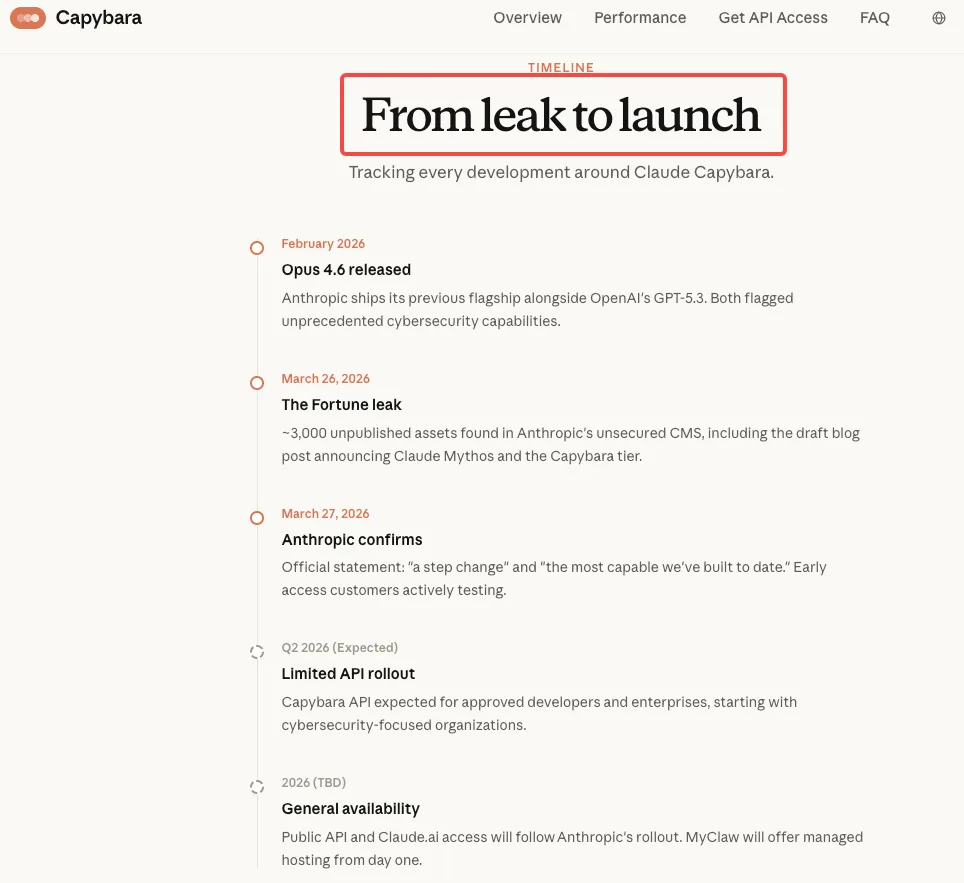
Esse enquadramento trata o risco de cibersegurança não como uma limitação gerenciável, mas como uma externalidade significativa que requer compartilhamento proativo com os defensores. É uma postura notavelmente diferente dos lançamentos anteriores da Anthropic.
O que está faltando no vazamento? Números específicos de benchmark, categorias de exploits ou metodologia detalhada. Afirmações de “pontuações dramaticamente mais altas em testes de cibersegurança” representam a extensão completa da capacidade divulgada. Qualquer coisa mais específica circulando online é extrapolação.
Por Que a Anthropic Está Tratando Isso Como um Risco Sem Precedentes
O Que “Muito à Frente de Qualquer Outro Modelo de IA em Capacidades Cibernéticas” Realmente Significa
Essa afirmação ganha outro peso se você entender o que o Opus 4.6 — a linha de base atual — já é capaz de fazer. O Mythos não está superando uma barra baixa.
Usando o Claude Opus 4.6, a Equipe Red da Frontier da Anthropic encontrou e validou mais de 500 vulnerabilidades de alta gravidade em bases de código open-source de produção — bugs que haviam passado despercebidos por décadas, apesar de anos de revisão especializada. A equipe não usou instruções especializadas ou estrutura personalizada, confiando apenas nas capacidades nativas do modelo.
Um caso notável: o Opus 4.6 identificou uma injeção SQL cega no Ghost CMS (uma plataforma com mais de 50.000 estrelas no GitHub e um histórico de segurança anteriormente impecável) em aproximadamente 90 minutos.
A diferença estrutural entre a descoberta de vulnerabilidades impulsionada por IA e o fuzzing tradicional é um contexto importante aqui. Os fuzzers alimentam entradas no código até que algo quebre. O Claude raciocina sobre o código: rastreando a lógica entre componentes, lendo históricos de commits para encontrar variantes não corrigidas de bugs corrigidos e avaliando quais caminhos de código são inerentemente arriscados em vez de estudar cada entrada possível. O Mythos, de acordo com a própria avaliação interna da Anthropic, faz isso melhor do que qualquer outra coisa atualmente disponível — por uma margem significativa.
O Problema do Déficit dos Defensores: Por Que o Ataque Pode Superar a Defesa
A percepção mais importante do rascunho não foi catalogar novos tipos de ataque. Foi articular por que a assimetria atacante-defensor existe em primeiro lugar. Os atacantes precisam encontrar uma fraqueza. Os defensores precisam cobrir tudo. Um modelo de IA que pode raciocinar sobre código, identificar padrões potenciais de vulnerabilidade e auxiliar no refinamento de exploits comprime o tempo de “ideia” para “ataque funcional.”
A Anthropic supostamente alertou altos funcionários do governo de que o Mythos poderia tornar ataques cibernéticos em grande escala mais prováveis em 2026, habilitando agentes autônomos altamente sofisticados. Uma pesquisa da Dark Reading do início de 2026 descobriu que 48% dos profissionais de cibersegurança agora classificam a IA agêntica como o principal vetor de ataque do ano — à frente de deepfakes e engenharia social.
Este não é um problema que o Mythos cria do zero; é um acelerador. Os adversários já usam IA sem hesitação ou fricção de conformidade. Os defensores que restringem o acesso a modelos de fronteira correm o risco de ceder terreno crítico.
Aplicações Defensivas vs. Ofensivas: Onde Está a Linha
Casos de Uso Legítimos: Varredura de Vulnerabilidades, Red Teaming, Hardening de Código
As aplicações defensivas das capacidades do Mythos são genuinamente significativas — e são a principal razão pela qual a Anthropic está construindo e lançando isso.
O Claude Code Security, uma nova capacidade integrada ao Claude Code, verifica bases de código em busca de vulnerabilidades de segurança e sugere patches de software direcionados para revisão humana, permitindo que as equipes encontrem e corrijam problemas de segurança que os métodos tradicionais costumam perder. Nada é aplicado sem aprovação humana: o Claude Code Security identifica problemas e sugere soluções, mas os desenvolvedores sempre tomam a decisão.
A capacidade de nível Mythos aplicada a esse fluxo de trabalho significaria encontrar classes de vulnerabilidade que até mesmo o Opus 4.6 perde — falhas dependentes de contexto na lógica de negócios, padrões de interação de múltiplos componentes, bypasses de autenticação que exigem entender a arquitetura do sistema em vez de padrões de código. Para equipes de segurança que atualmente pagam por testes de penetração manuais em um ciclo trimestral, a varredura contínua impulsionada por IA na qualidade de raciocínio de nível Mythos representa uma mudança significativa no que é operacionalmente alcançável.
Para equipes de red team, o mesmo poder exige escopo e autorização rigorosos. O modelo em si não distingue entre testes autorizados e uso malicioso — essa responsabilidade permanece com seus processos e salvaguardas.
O Que a Anthropic Está Fazendo para Limitar o Uso Indevido
Junto com o Opus 4.6, a Anthropic implantou sondas de nível de ativação para detectar e bloquear o uso indevido cibernético em tempo real, reconhecendo o potencial de fricção para pesquisas de segurança legítimas. “Isso criará fricção para pesquisas legítimas e algum trabalho defensivo, e queremos trabalhar com a comunidade de pesquisa de segurança para encontrar maneiras de lidar com isso à medida que surgir,” alertou a empresa.
Para o Mythos especificamente, os controles são estruturais e não apenas técnicos. Com base nos documentos vazados e nas declarações públicas da Anthropic, o acesso inicial é restrito a pesquisadores de segurança e defensores verificados — o objetivo é construir ferramentas defensivas antes que as capacidades ofensivas estejam amplamente disponíveis. Isso espelha o tratamento da Anthropic de lançamentos anteriores de alto risco e está alinhado com as práticas recomendadas pelo AI Risk Management Framework do NIST, que defende a implantação em estágios com monitoramento contínuo para sistemas de IA de duplo uso.
Vale a pena revisar a seção de táticas de IA adversarial do framework MITRE ATT&CK para qualquer equipe de segurança tentando modelar a superfície de ameaça aqui. As táticas documentadas assumem modelos significativamente menos capazes do que o que o Mythos representa.
O Que os Clientes de Segurança de Acesso Antecipado Estão Avaliando
O rascunho vazado foi explícito sobre a prioridade de lançamento da Anthropic: “Vamos expandir gradualmente o acesso ao Claude Mythos para mais clientes usando a API Claude nas próximas semanas. Como estamos particularmente interessados em usos de cibersegurança, é para isso que pretendemos expandir o EAP inicialmente.”
O grupo de acesso antecipado está avaliando o Mythos em relação ao problema específico para o qual o modelo foi projetado: encontrar vulnerabilidades em bases de código de produção endurecidas de forma mais rápida e abrangente do que as ferramentas existentes. Analistas observam que ele poderia comprimir a lacuna ofensiva-defensiva em ambas as direções — possibilitando descoberta mais rápida de vulnerabilidades, red teaming contínuo e caça a ameaças, enquanto também diminui a barreira para ataques sofisticados se usado de forma inadequada.
Para clientes de segurança atualmente no período de avaliação, as questões práticas se concentram em três áreas: como o Mythos se integra com os fluxos de trabalho existentes de SIEM e gerenciamento de vulnerabilidades, se os resultados do modelo podem ser apresentados em formatos compatíveis com sistemas de tickets existentes e como são os requisitos de revisão humana em escala.
Em entrevistas com mais de 40 CISOs em vários setores, a VentureBeat descobriu que estruturas formais de governança para ferramentas de varredura baseadas em raciocínio são a exceção, não a regra. As respostas mais comuns foram que a área era considerada tão incipiente que muitos CISOs não achavam que essa capacidade chegaria tão cedo em 2026. As equipes dentro do programa de acesso antecipado estão, em certo sentido, escrevendo o manual de governança que o resto do setor seguirá.
Implicações para Equipes de Desenvolvedores que Constroem sobre Infraestrutura de IA
Se sua equipe está construindo produtos sobre Claude ou qualquer modelo de IA de fronteira, a situação do Mythos cria duas categorias distintas de preocupação.
A primeira é direta: você é um alvo potencial para ataques assistidos por IA, e esses ataques estão se tornando mais capazes.
A segunda preocupação é arquitetural: como sua infraestrutura de IA é protegida contra injeção de prompt, acesso não autorizado a ferramentas e uso indevido de agentes. As organizações precisam tratar cada agente, bot e serviço de IA como uma identidade, aplicando o mesmo nível de controles, permissões e supervisão a identidades não humanas que aplicam a usuários humanos — exigindo inventário de acesso e eliminando credenciais codificadas que criam bots inseguros.
Na prática, isso significa várias coisas para equipes que constroem sobre Claude hoje:
Limite rigorosamente o acesso ao servidor MCP. Cada servidor MCP que você conecta a um agente Claude é uma superfície de ataque potencial. As capacidades agênticas expandidas que tornam o Claude Code poderoso também fazem com que permissões de agente com escopo inadequado sejam um vetor de risco significativo.
Trate o CLAUDE.md como um documento de segurança. As instruções no CLAUDE.md que definem quais ferramentas um agente pode usar, quais arquivos pode ler e quais operações pode executar são controles de segurança, não apenas auxiliares de produtividade. Um CLAUDE.md mal escrito que concede amplo acesso a arquivos ou permissões de ferramentas amplifica o risco.
Aplique revisão humana a patches gerados por IA, não apenas a código gerado por IA. O código gerado por IA tem 2,74x mais probabilidade de introduzir vulnerabilidades XSS e 1,91x mais probabilidade de introduzir referências de objetos inseguros em comparação com código escrito por humanos. A mesma capacidade de raciocínio que encontra vulnerabilidades pode introduzi-las. A revisão humana de mudanças relevantes para segurança não é opcional.
Perguntas Frequentes
As equipes de segurança podem acessar o Claude Mythos agora?
Não por nenhum canal público. O plano de lançamento do modelo reflete a preocupação com cibersegurança: o acesso antecipado é restrito a organizações de cibersegurança defensiva verificadas. Para equipes de segurança que desejam se preparar, o Claude Code Security — construído sobre o Opus 4.6, disponível agora em prévia de pesquisa limitada para clientes Enterprise e Team — é a ferramenta publicamente acessível mais próxima e uma linha de base útil para entender o que a capacidade de nível Mythos estenderia.
Quais salvaguardas a Anthropic está construindo?
As medidas confirmadas incluem sondas de detecção de uso indevido em tempo real, lançamento em estágios priorizando defensores e requisitos de revisão humana para patches. Para o Mythos, a ênfase está na governança de implantação, limites de ferramentas e trilhas de auditoria.
O Claude Mythos estará disponível para red teaming comercial?
Não confirmado. O grupo de acesso antecipado está focado em casos de uso de segurança defensiva. O red teaming comercial — onde organizações contratam empresas de segurança para sondar ativamente seus sistemas — fica em uma zona ambígua: é ofensiva autorizada. Dada a preocupação declarada da empresa sobre uso indevido ofensivo, espere controles de acesso significativos em vez de acesso aberto à API para casos de uso de red teaming.
Posts Anteriores:
- Claude Mythos vs Claude Opus 4.6: O Que o Vazamento Revela para Desenvolvedores
- Claude Mythos (Opus 5) Vazado: O Que Sabemos Até Agora
- O Que É o Claude Mythos? Vazamento, Nível Capybara e O Que a Anthropic Confirmou
- Claude Sonnet 4.6: Um Modelo de Trabalho “Sem Roubar o Protagonismo”
- Claude Opus 4.6 e Sonnet 4.6: Tudo O Que Você Precisa Saber
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado
API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção
Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída
API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber