Claude Code Agent Harness: Análise da Arquitetura
Como o Claude Code conecta ferramentas, gerencia permissões e orquestra sessões de agentes — uma análise técnica para desenvolvedores.

Eu continuava deparando com a mesma pergunta enquanto construía minha própria configuração de chamada de ferramentas: por que a integração parece muito mais difícil do que a construção de prompts?
A parte do modelo ficou clara rapidamente. Mas no momento em que precisei que ele fizesse coisas — ler arquivos, executar comandos shell, falar com serviços externos — cada decisão parecia que poderia quebrar algo. Limites de permissão. Limites de contexto. Despacho de ferramentas.
Então, no final de março de 2026, o código-fonte do Claude Code foi acidentalmente exposto via um mapa de fonte npm na versão 2.1.88. Mais de 500.000 linhas de TypeScript, espelhadas em horas. A Anthropic confirmou que foi um erro de empacotamento — sem dados de clientes envolvidos — e começou a emitir remoções DMCA.
Mas a arquitetura se tornou de conhecimento público. E o que ela revelou não foi o modelo. Foi o harness.
Uma nota sobre as fontes: Os detalhes aqui vêm de análises da comunidade, reproduções de código aberto e documentação pública e blog de engenharia da Anthropic — não do próprio código vazado. Detalhes incertos estão marcados.
O Que É um Harness de Agente?
Definição e papel em sistemas agênticos
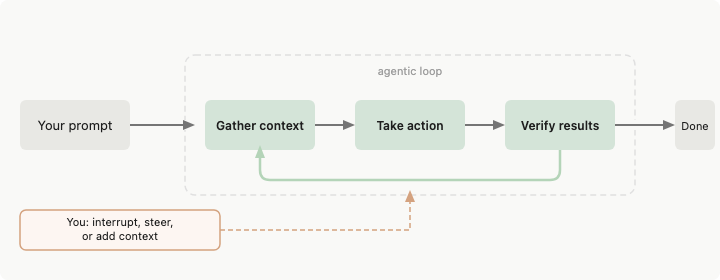
Um harness de agente é tudo que existe entre o modelo de linguagem e o mundo real. O modelo gera texto. O harness decide o que esse texto pode tocar.
A documentação da Anthropic para o Claude Code descreve isso diretamente: o Claude Code “fornece as ferramentas, gerenciamento de contexto e ambiente de execução que transformam um modelo de linguagem em um agente de codificação capaz.” O modelo raciocina. O harness age.
Quando seu agente lê um arquivo, o harness decide se a leitura é permitida, o que acontece com o resultado e quanto da resposta cabe no próximo prompt. O modelo nunca toca o sistema de arquivos diretamente.
Por que o design do harness importa para produção
A maioria das demonstrações de agentes pula essa parte. Você vê um modelo chamando uma função, obtendo um resultado, chamando outra. Parece limpo. Então você executa por 45 minutos em uma base de código real, e as coisas começam a desmoronar silenciosamente — contexto transbordando, permissões muito frouxas ou muito irritantes, resultados de ferramentas truncados sem o modelo saber.
A equipe de engenharia da Anthropic escreveu sobre isso: mesmo um modelo de fronteira executando em loop através de múltiplas janelas de contexto terá desempenho inferior sem um harness bem projetado. O agente tenta fazer muita coisa de uma vez, ou declara o trabalho concluído prematuramente. O harness impõe estrutura sobre essa tendência.

A Superfície de Ferramentas do Claude Code
Categorias principais de ferramentas
Com base na documentação oficial do Claude Code e análises públicas, o Claude Code expõe aproximadamente 19 ferramentas com controle de permissão. As principais categorias: leituras e edições de arquivos, execução de shell (Bash), operações Git, busca na web, edição de notebooks e chamadas de ferramentas MCP. Análises da comunidade sugerem que o número pode ser mais próximo de 40 quando se inclui integração LSP, geração de subagentes e ferramentas internas de coordenação.
Cada ferramenta é sandboxed independentemente. Não é “o agente tem acesso ao sistema de arquivos” — é “o agente pode usar a ferramenta Read, e Read tem seu próprio portão de permissão que verifica um pipeline de regras antes de qualquer execução.”
Como as ferramentas são registradas e despachadas
O modelo decide o que tentar. O sistema de ferramentas decide o que é permitido. Arquiteturalmente separados.
Toda chamada de ferramenta flui através de uma verificação de permissão antes da execução. Análises aprofundadas da comunidade descrevem uma função central que avalia regras de negar/perguntar/permitir nessa ordem — negar sempre vence. Três resultados possíveis: prosseguir silenciosamente, solicitar ao usuário ou bloquear.
Um modelo comprometido não pode contornar verificações de segurança sendo persuasivo. O harness não se importa com o argumento do modelo. Regras são regras.
Níveis de permissão
O modelo de permissão do Claude Code foi descrito por múltiplos analistas da comunidade como aproximadamente três níveis:
Nível 1 — Aprovação automática: Ações somente leitura ou inerentemente seguras. Leituras de arquivos, pesquisa de texto, navegação de código. Essas não alteram estado, portanto executam sem interrupção.
Nível 2 — Solicitar confirmação: Ações que modificam estado de maneiras controladas. Edições de arquivos, certos comandos shell. No modo automático (introduzido em março de 2026), um classificador em segundo plano executando no Sonnet 4.6 avalia se elas podem prosseguir sem perguntar. O classificador vê a solicitação do usuário e a chamada de ferramenta, mas não o texto em prosa do modelo — uma escolha de design deliberada para evitar que o modelo passe pela barreira com argumentos.
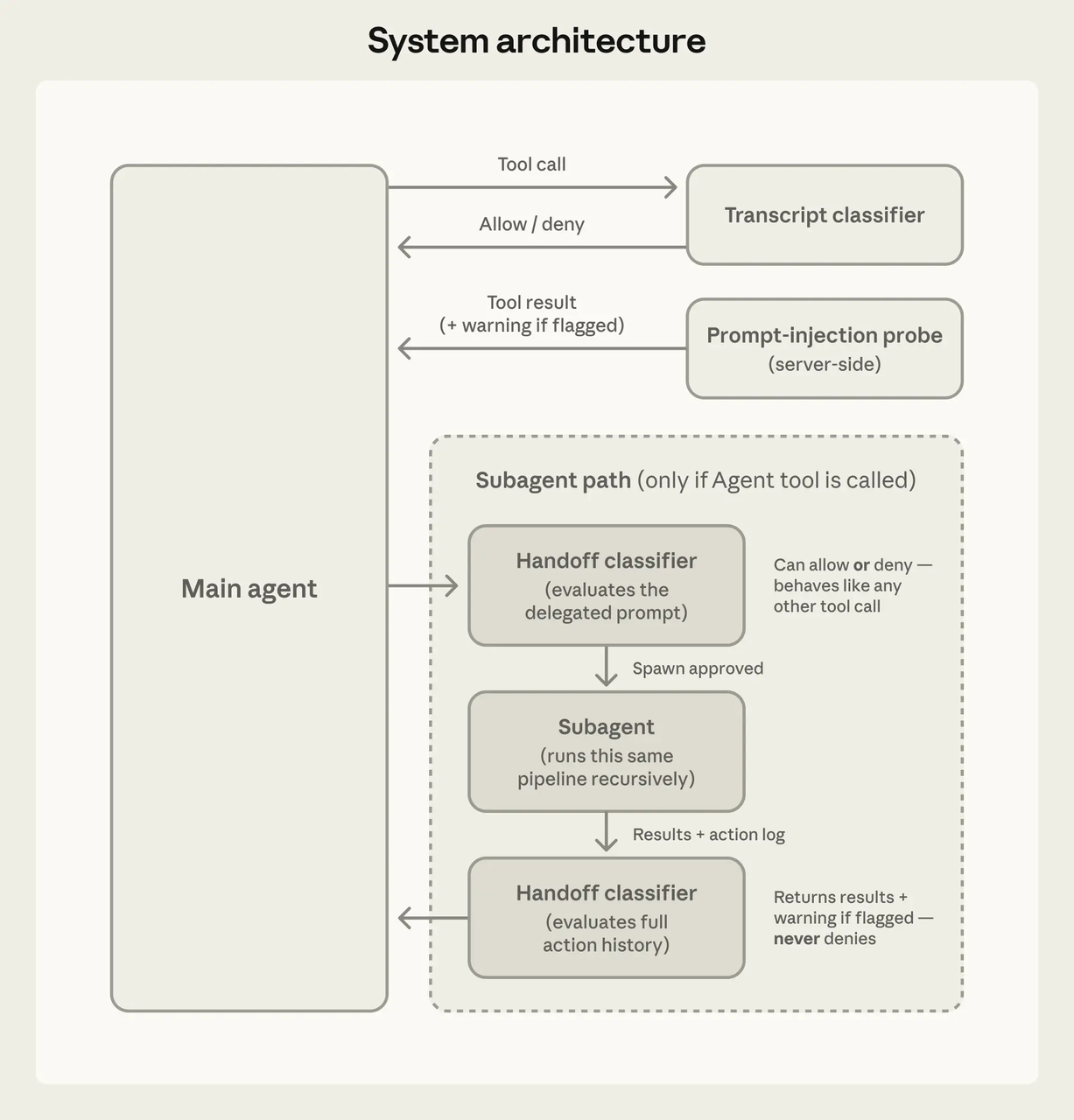 Nível 3 — Requer aprovação explícita ou bloqueio: Operações de alto risco. Comandos shell que poderiam modificar o estado do sistema de forma imprevisível, operações fora do diretório de trabalho, qualquer coisa que pareça exfiltração de dados.
Nível 3 — Requer aprovação explícita ou bloqueio: Operações de alto risco. Comandos shell que poderiam modificar o estado do sistema de forma imprevisível, operações fora do diretório de trabalho, qualquer coisa que pareça exfiltração de dados.
Uma ressalva: o enquadramento de três níveis vem de análise da comunidade, não dos documentos oficiais da Anthropic. O sistema oficial usa regras de permitir/perguntar/negar e seis modos de permissão (padrão, acceptEdits, plan, auto, dontAsk, bypassPermissions). Os “três níveis” são um modelo mental útil, mas uma simplificação.
Gerenciamento de Sessão e Contexto
Como o Claude Code rastreia o estado da sessão
O Claude Code acumula contexto ao longo de uma sessão — arquivos lidos, comandos executados, resultados de grep, diffs, saída de erros. Tudo se empilha em um prompt crescente. Ao contrário de uma interface de chat onde cada mensagem é um tanto independente, uma sessão do Claude Code é uma memória de trabalho contínua.
As sessões são salvas localmente. Cada mensagem, uso de ferramenta e resultado são armazenados, o que permite retroceder, retomar e bifurcar. Antes de alterações no código, o harness faz um snapshot dos arquivos afetados para que você possa reverter.
Truncamento de saída e tratamento de custo de tokens
Grandes saídas de ferramentas são um problema real. O Claude Code define um máximo padrão de 25.000 tokens para saída de ferramentas MCP, com um aviso em 10.000 tokens. Os autores de servidores podem anotar ferramentas para permitir resultados maiores (até 500.000 caracteres), que são persistidos em disco em vez de mantidos no contexto.
Esse é o tipo de coisa que você não pensa até que seu agente silenciosamente perde o rastreamento de informações porque um resultado de ferramenta foi truncado. Limites explícitos e configuráveis com fallbacks baseados em disco — vale a pena copiar.
Comportamento de compactação
Esse me pegou antes de eu entendê-lo. Quando o uso de tokens atinge aproximadamente 98% da janela de contexto, o Claude Code compacta automaticamente: resume o histórico anterior para liberar espaço. Metadados críticos são preservados. Imagens e PDFs são removidos.
A parte complicada: a compactação pode perder detalhes importantes. A solução prática: coloque tudo que for crítico no CLAUDE.md, que o harness relê a cada turno.
A pesquisa da Anthropic sobre design de harness descobriu que resets completos de contexto — onde uma nova instância de agente assume a partir de um artefato de handoff — às vezes funcionam melhor do que a compactação para sessões estendidas. Mais complexidade de orquestração, mas melhor fidelidade de contexto.
Camada de Integração MCP
Como o Claude Code se conecta a servidores MCP
 MCP (Model Context Protocol) é um padrão aberto para conectar ferramentas de IA a serviços externos. O Claude Code suporta três modos de transporte: HTTP (recomendado para servidores remotos), stdio (para processos locais) e SSE.
MCP (Model Context Protocol) é um padrão aberto para conectar ferramentas de IA a serviços externos. O Claude Code suporta três modos de transporte: HTTP (recomendado para servidores remotos), stdio (para processos locais) e SSE.
Adicionar um servidor é um comando: claude mcp add server-name --transport http "URL". Depois disso, as ferramentas do servidor aparecem como ferramentas chamáveis na sessão, sujeitas ao mesmo pipeline de permissão que as ferramentas integradas.
Descoberta de ferramentas e fluxos de autenticação
Um detalhe que me impressionou: a busca de ferramentas. Quando você conecta servidores MCP, o Claude Code não carrega todos os seus esquemas de ferramentas no contexto antecipadamente. Ele carrega apenas os nomes das ferramentas no início da sessão, depois usa um mecanismo de busca para descobrir ferramentas relevantes quando uma tarefa realmente precisa delas. Apenas as ferramentas que o Claude usa entram no contexto.
Isso mantém a sobrecarga do MCP baixa. Os fluxos de autenticação dependem do servidor — OAuth, chaves de API, cabeçalhos. O Claude Code requer aprovação explícita do usuário para novos servidores MCP.
O que está pronto para produção vs. ainda em evolução
A integração MCP é funcional e ativamente usada. Mas alguns limites práticos valem a pena conhecer:
O limite recomendado é em torno de 5 a 6 servidores MCP ativos, já que cada um inicia um subprocesso. A busca de ferramentas ajuda com a sobrecarga de contexto, mas a latência ainda aumenta além disso.
 Respostas MCP grandes precisam de tratamento cuidadoso. O limite padrão de 25K tokens funciona para a maioria dos casos de uso, mas fica apertado para esquemas de banco de dados. O fallback de persistência em disco ajuda, embora o modelo receba apenas uma referência em vez do resultado completo no contexto.
Respostas MCP grandes precisam de tratamento cuidadoso. O limite padrão de 25K tokens funciona para a maioria dos casos de uso, mas fica apertado para esquemas de banco de dados. O fallback de persistência em disco ajuda, embora o modelo receba apenas uma referência em vez do resultado completo no contexto.
E os servidores MCP construídos pela comunidade variam em qualidade. Os documentos da Anthropic explicitamente observam que servidores de terceiros podem ser vetores de injeção de prompt. O sistema de permissão ajuda, mas a confiança ainda é sua responsabilidade.
Lições para Construtores
O que essa arquitetura revela sobre sistemas agênticos de nível produção
Alguns padrões do design do Claude Code que acho que se generalizam:
Separe o raciocínio da aplicação de permissões. O modelo decide o que quer fazer. Um sistema diferente decide se é permitido. Um modelo comprometido não pode substituir verificações de segurança porque literalmente é um caminho de código diferente.
Torne o gerenciamento de contexto explícito. Compactação, limites de truncamento, busca de ferramentas, persistência em disco — todos esses são mecanismos para gerenciar ativamente o que o modelo vê. A maioria dos projetos amadores de agentes trata o contexto como um saco sem fundo. Não é.
Projete para continuidade de sessão. Snapshots, alterações de arquivo reversíveis, CLAUDE.md como âncora persistente. Agentes de longa execução precisam de memória que sobreviva à compressão de contexto.
A granularidade de permissão compensa. Regras por ferramenta, por padrão, por diretório com avaliação negar-primeiro. Mais trabalho do que uma flag “permitir tudo”, mas é a diferença entre uma demonstração e um sistema implantável.
Quando construir seu próprio harness vs. usar uma camada gerenciada
Tarefa estreita e bem definida — um bot de CI que executa testes e publica resultados — você pode montar um harness mínimo você mesmo. Algumas ferramentas, uma verificação de permissão simples, uma janela de contexto fixa.
Sessões estendidas, estado através de resets de contexto, saída de ferramentas não confiáveis, dezenas de ferramentas — construa sobre um harness existente ou estude um de perto. O Claude Agent SDK, a arquitetura Codex da OpenAI, o LangGraph já resolveram problemas que você acabará encontrando.
A maioria das equipes subestima a complexidade do harness. Eu certamente subestimei. O modelo é a parte fácil.
Perguntas Frequentes
O que é o harness de agente do Claude Code?
A camada de infraestrutura entre o modelo Claude e o mundo real — despacho de ferramentas, permissões, gerenciamento de contexto, estado de sessão, conexões MCP. A Anthropic descreve como o que “transforma um modelo de linguagem em um agente de codificação capaz.”
Como o Claude Code lida com permissões de ferramentas?
Um pipeline baseado em regras avalia cada chamada de ferramenta: permitir, perguntar ou negar, com negar sempre vencendo. No modo automático, um classificador em segundo plano em uma instância de modelo separada avalia casos ambíguos — e deliberadamente não vê a saída em prosa do agente para evitar injeção de prompt.
A integração MCP do Claude Code está pronta para produção?
Funcional e ativamente usada, mas com limites práticos em torno de contagem de servidores, tamanho de resposta e confiança em terceiros. Está evoluindo rapidamente.
Posso construir meu próprio harness usando os mesmos padrões?
Sim. O Claude Agent SDK expõe os mesmos modos de permissão, hooks e gerenciamento de contexto. Projetos da comunidade como Everything Claude Code também documentaram padrões reutilizáveis.
Qual é a diferença entre paridade de especificação e paridade comportamental?
Paridade de especificação significa suportar as mesmas ferramentas e configurações. Paridade comportamental significa lidar com casos extremos da mesma forma — compactação descartando uma regra crítica, uma ferramenta retornando 100K tokens, um modelo tentando contornar permissões. Corresponder à especificação é simples. Corresponder ao comportamento leva meses.
Algo que ficou comigo: o harness é a parte difícil. Todo mundo assume que o modelo é a vantagem competitiva. E é — até você tentar fazê-lo fazer coisas de forma confiável por mais de cinco minutos. É aí que vive a engenharia.
Posts anteriores:
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado

API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção

Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída

API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber
