GLM-5V-Turbo: What Developers Should Know in 2026
GLM-5V-Turbo is Z.ai's vision-coding model. Here's what developers need to know about its API, pricing, limits, and real use cases in 2026.

A colleague sent me a screenshot last week — a design mockup on the left, a near-pixel-perfect HTML reproduction on the right. “GLM-5V-Turbo did this in one pass,” the caption said. I filed it away and moved on. Then I kept seeing it mentioned in the same breath as agentic workflow tooling, and decided to actually look at what this model is and isn’t.
This is what I found — written for developers evaluating multimodal models for agentic coding use cases, not for anyone looking for a product recommendation.
What Is GLM-5V-Turbo?
Z.ai (Zhipu AI) and the GLM Model Family
GLM-5V-Turbo is a vision-language model released on April 1, 2026 by Zhipu AI, operating internationally under the brand Z.ai. Zhipu is a Beijing-based AI lab — publicly traded on the Hong Kong Stock Exchange since January 2026 — and one of China’s most active foundation model producers. Their GLM series has iterated quickly: GLM-4.5 in July 2025, GLM-4.7 in December, GLM-5 in February 2026, and now a multimodal variant in April.
GLM-5V-Turbo is the first model in the family built as a native multimodal agent — meaning vision wasn’t bolted on, it was part of the architecture from the start. That distinction matters for what the model is actually good at.
How GLM-5V-Turbo Differs from GLM-4V and GLM-5
GLM-4V handled image input. GLM-5 improved text coding and reasoning. GLM-5V-Turbo combines multimodal input (image, video, text) with agent-oriented output: tool calling, task decomposition, and GUI interaction. It’s built around a new visual encoder called CogViT, uses reinforcement learning across 30+ task types, and runs INT8 quantization for faster inference.
The positioning is narrow by design. This is not a general-purpose upgrade to GLM-5. It’s a specialized model for tasks that start with visual input and end with code or structured action.
Core Capabilities
Design-to-Code and UI Generation
The headline capability is reproducing UI designs as working frontend code. Give the model a mockup — screenshot, Figma export, hand-drawn sketch — and it generates HTML, CSS, and sometimes JavaScript. In Z.ai’s own testing, GLM-5V-Turbo scored 94.8 on the Design2Code benchmark against Claude Opus 4.6’s 77.3. That’s a meaningful gap if the benchmark holds up under independent testing (more on that below).
In practice, this is most useful for frontend scaffolding: turning design specs into initial component code, reproducing existing UI layouts for migration projects, or generating variations from a reference image.
GUI Agent and Agentic Workflow Support
Beyond static design reproduction, the model supports GUI agent tasks — navigating browser interfaces, extracting structured data from screens, and executing multi-step workflows that involve visual state. OpenRouter’s model page describes it as built to “complete the full loop of perceive → plan → execute,” and the AndroidWorld and WebVoyager benchmark results Z.ai cites suggest it can handle real-world GUI navigation, not just synthetic tests.
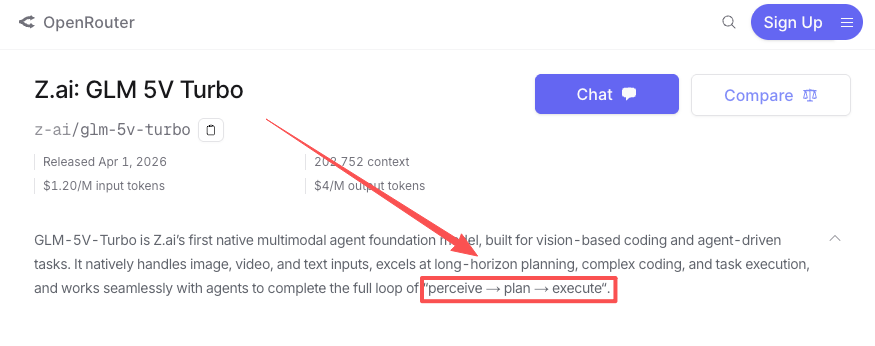
For teams building agentic workflows that include a visual layer — form-filling automation, UI testing agents, screen-to-action pipelines — this is where the model has a practical claim. The tool calling improvements in GLM-5V-Turbo (inherited and extended from GLM-5-Turbo) are explicitly designed to reduce failed invocations in agent loops.
Multimodal Input Handling
The model accepts images, short video clips, and text in the same context. Video input extends the use cases into screen recordings and product walkthroughs — the model can follow along visually and generate documentation or action plans from what it sees. Context window is 202,752 tokens with a maximum output of 131,072 tokens, confirmed on Z.ai’s official pricing page.
API Access and Pricing
How to Access GLM-5V-Turbo via API
The model is available through Z.ai’s API with an OpenAI-compatible interface. Authentication follows standard API key patterns — register at z.ai, generate a key, configure it in your existing tooling.
The API supports function calling, streaming, and structured output — the same capability surface as GLM-5-Turbo, extended with vision input.
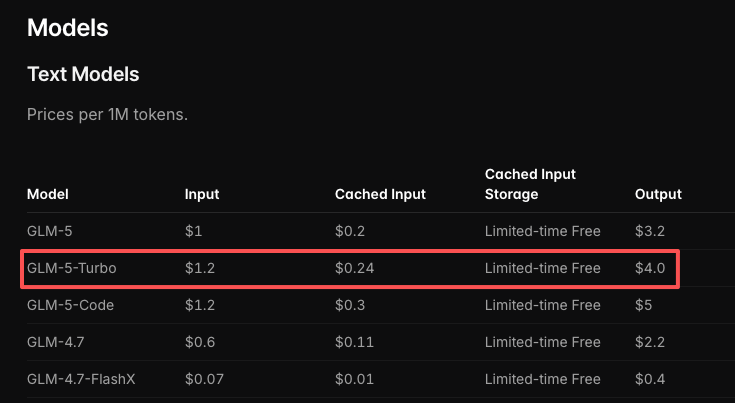
Pricing: Input and Output Token Costs
| GLM-5V-Turbo | GLM-5-Turbo | GLM-5 | |
|---|---|---|---|
| Input (per 1M tokens) | $1.20 | $1.20 | $1.00 |
| Output (per 1M tokens) | $4.00 | $4.00 | $3.20 |
| Cached input | $0.24 | $0.24 | $0.20 |
Figures sourced from the Z.ai official pricing page as of April 2026. Verify directly before planning production budgets — Z.ai has adjusted pricing with previous model launches.
For reference: Claude Opus 4.6 costs $5/M input and $25/M output. GPT-4o is $2.50/$10. At $1.20/$4, GLM-5V-Turbo is meaningfully cheaper for vision-heavy workloads where output volume is modest.
Context Window and Output Limits
- Context window: 202,752 tokens
- Max output: 131,072 tokens
Both are generous. For most design-to-code or GUI agent tasks, you won’t hit these limits. Long video sequences or very large design files might, so worth testing with your actual inputs before committing.
Where It Fits (and Where It Doesn’t)
Strengths: Visual Coding, Design Reproduction
GLM-5V-Turbo’s practical advantage is specific: tasks that require looking at something and producing code from it. Frontend scaffolding from design assets, UI component extraction, screenshot-to-HTML, screen recording analysis. If your pipeline starts with a visual artifact and ends with code, this model is worth benchmarking against your current solution.
The agentic workflow support is a real addition. Tool calling stability matters in production agent loops — failed invocations break chains and require retries. Z.ai’s stated focus on this in GLM-5V-Turbo is a sign they’ve seen the same failure mode everyone building agents has.
Limitations: Pure-Text Backend Coding, General Reasoning
This is the part worth being explicit about. GLM-5V-Turbo is not a direct competitor to Claude or GPT-4o for backend coding, repository exploration, or general reasoning tasks. In those categories, Claude Opus 4.6 leads across the board according to Z.ai’s own comparisons — and that’s the company making the favorable case for their model.
If your coding work is primarily text-in, text-out — debugging logic, writing API integrations, refactoring backend code — a text-only model like GLM-5 or GLM-5-Turbo will serve you better at the same price. Adding a visual encoder doesn’t help with problems that don’t involve visual input.
Who Should Use It and Who Should Skip It
Worth evaluating if you’re:
- Building frontend tooling that starts from design assets
- Running GUI agent workflows with visual state
- Looking for a cheaper alternative to GPT-4V or Claude for image-to-code tasks
- Testing multimodal inputs in an agent pipeline
Probably skip it if you’re:
- Working on pure text coding — backend, CLI tooling, API development
- Needing strong general reasoning alongside code generation
- Operating under data residency constraints (Z.ai is a Chinese company; review their privacy policy against your compliance requirements)
Benchmark Claims — What to Take Seriously
Design2Code Performance
Z.ai reports GLM-5V-Turbo scored 94.8 on Design2Code versus Claude Opus 4.6‘s 77.3. These are Z.ai’s own measurements. No independent evaluation lab has published corroborating results as of this writing. That doesn’t mean the numbers are wrong — it means they haven’t been stress-tested yet.
Design2Code as a benchmark measures how closely the generated HTML/CSS reproduces a reference mockup, pixel-wise and structurally. It’s a reasonable proxy for the specific task of UI reproduction. It is not a proxy for general coding quality, architectural judgment, or real-world production readiness.
The gap is large enough to be credible as a directional signal. Treat it as a reason to test, not as a conclusion.
Pure-Text Coding Comparison Caveats
Z.ai’s documentation acknowledges that GLM-5V-Turbo trails Claude in pure-text coding benchmarks. That candor is useful. It means the model’s positioning is honest: this is a visual-first tool, not a general coding upgrade. Any comparison that frames GLM-5V-Turbo as broadly competitive with frontier text models is misreading what the company is actually claiming.
FAQ
Q: Is GLM-5V-Turbo available via API?
Yes. Via Z.ai’s native API (OpenAI-compatible) and through OpenRouter. Standard API key setup, supports function calling and streaming.
Q: What is the pricing for GLM-5V-Turbo?
$1.20 per million input tokens, $4.00 per million output tokens, as of April 2026. Verify at docs.z.ai/guides/overview/pricing before production use.
Q: How does GLM-5V-Turbo compare to GPT-4o and Claude for coding?
For design-to-code and visual UI tasks: Z.ai’s benchmarks (self-reported) show it ahead of both. For pure text coding and backend work: Claude Opus 4.6 leads. The comparison only holds in the visual domain.
Q: Does GLM-5V-Turbo support video input?
Yes — short video clips alongside images and text in the same context. Useful for screen recordings and walkthrough-based documentation generation.
Q: What are the rate limits and context window?
Context window is 202,752 tokens, max output 131,072 tokens. Rate limits aren’t published in the official docs — Z.ai has had capacity issues with previous model launches, so test throughput under real load before committing to a production architecture.
Design-to-code is a genuinely useful task category, and having a model that treats it as a first-class problem — rather than a side capability of a general model — is a reasonable engineering decision. Whether GLM-5V-Turbo delivers on that in your specific pipeline is something only your own test data will answer.
The benchmark numbers are worth a look. The independent verification is still pending.
Pricing and specs verified against the Z.ai official documentation as of April 2, 2026. All benchmark figures are Z.ai’s self-reported data unless otherwise noted — treat as preliminary until independently validated.
Previous Posts:
Related Articles

Claude Code Agent Harness Architecture: Key Insights from the Leak

Claude Code Undercover Mode: What the Leaked Source Actually Reveals

Claude Mythos API & Pricing: What Builders Need to Know Before Launch

What Is Google Gemma 4? Architecture, Benchmarks, and Why It Matters

Claude Code architecture Deep Dive: What the Leaked Source Reveals
