DeepSeek V4: Everything We Know About the Upcoming Coding AI Model
DeepSeek V4 is set to launch in February 2026 with revolutionary coding capabilities. Here's what we know about the architecture, features, and benchmarks.

DeepSeek has rapidly emerged as one of the most formidable players in the AI space, challenging established labs with their R1 reasoning model and cost-efficient training approach. With DeepSeek V4 now publicly released, the Chinese AI company has shipped a coding-optimized model lineup that pushes the boundaries of what AI can do for software development — at price points that reset the competitive math industry-wide.
This article was originally drafted as a release-watch preview. It has been fully revised on May 8, 2026 to reflect the actual launch — covering shipped specifications, official benchmark numbers, public API pricing, and independent evaluation results from the U.S. NIST CAISI program.
Release Timeline
DeepSeek V4 launched as a preview on April 24, 2026, after an extended development cycle that ran several months past the originally rumored mid-February window. The release came in the form of two open-weight models — DeepSeek-V4-Pro and DeepSeek-V4-Flash — released simultaneously on Hugging Face, the official API, and chat.deepseek.com (under “Expert Mode” and “Instant Mode” respectively).
The company has been characteristically quiet about external announcements, but the DeepSeek-V4 technical report (April 2026) and the Hugging Face collection together provide a comprehensive picture of what shipped.
Architecture Innovations
DeepSeek V4‘s actual shipped architecture differs in important ways from the pre-release rumors that circulated in early 2026. The technical report documents the following core innovations:
Hybrid Attention Architecture (CSA + HCA)
The headline innovation is not a single attention variant but a hybrid mechanism. DeepSeek-V4 combines Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) for long-context efficiency. According to Section 3 of the technical report, V4-Pro at the 1M-token context setting uses only ~27% of the per-token inference FLOPs and ~10% of the KV cache footprint compared with DeepSeek-V3.2 — the single biggest reason 1M context is now financially viable rather than just demonstrable.
Manifold-Constrained Hyper-Connections (mHC)
The mHC architecture replaces conventional residual connections with a constrained hyper-connection scheme that strengthens gradient propagation through deep MoE stacks. The technical report frames this as a stability mechanism: it preserves expressivity while dampening the signal-degradation problems that surface when scaling to 1.6T parameters with sparse routing.
Mixture-of-Experts Scaling
Building on the V3 lineage, V4 ships in two MoE configurations:
- V4-Pro: 1.6T total parameters, 49B activated per token
- V4-Flash: 284B total parameters, 13B activated per token
Only the activated subset of experts fires for any given forward pass, which is what makes the per-token economics work at this parameter scale.
Muon Optimizer and 32T-Token Pretraining
V4 was pretrained on more than 32 trillion tokens using the Muon optimizer rather than AdamW — a notable departure that DeepSeek credits for faster convergence at this scale. Note that the previously rumored “Engram conditional memory” feature does not appear under that name in the shipped technical report; the comparable functionality is delivered through the hybrid attention mechanism plus mHC, not a separate memory module.
Key Capabilities
Extended Context Windows
Both V4-Pro and V4-Flash support a 1M-token context window by default. Combined with the hybrid attention efficiency, this enables true repository-level reasoning where the model can process entire codebases in a single pass — understand cross-module relationships, trace dependencies, and maintain consistency across large-scale refactoring without the cost-per-call overhead that made earlier “1M context” claims impractical in production.
Multi-File and Repository-Level Reasoning
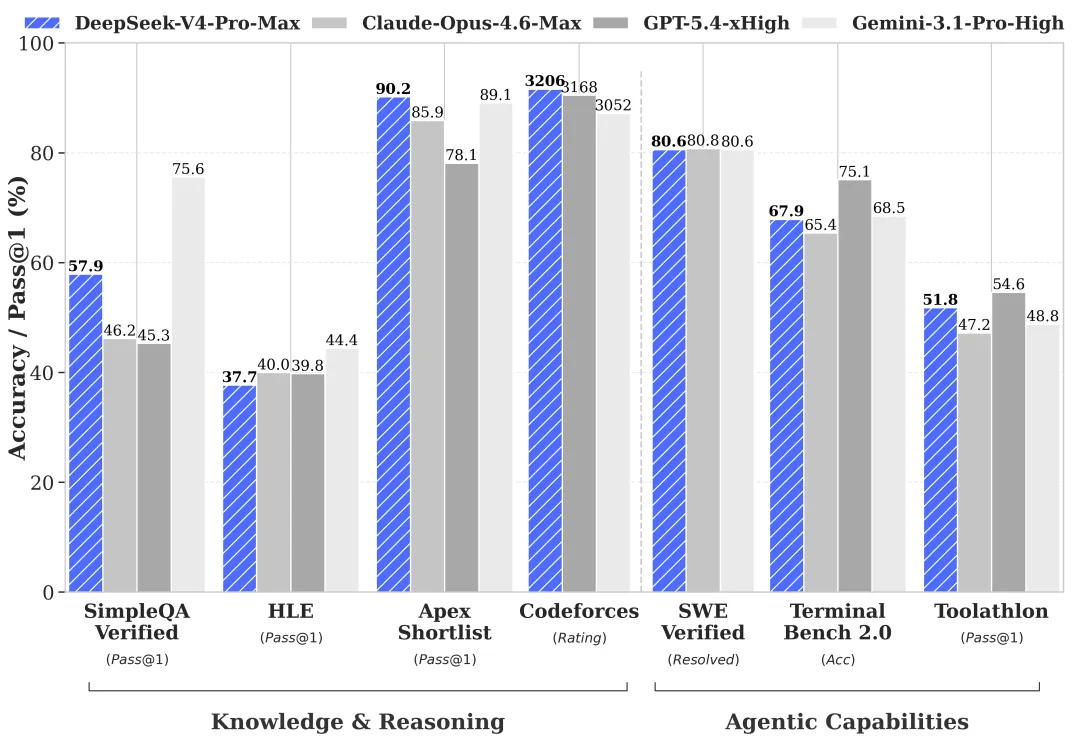
V4’s coding benchmarks demonstrate the practical impact. On the SWE-bench Verified benchmark — which tests real GitHub issue resolution rather than isolated function generation — V4-Pro-Max scores 80.6%, sitting 0.2 points behind Claude Opus 4.6 (80.8%) per Morph’s benchmark roundup and the official technical report. On Terminal-Bench 2.0 (multi-step shell and systems tasks), V4-Pro leads at 67.9% versus Claude Opus 4.6’s 65.4%.
Agentic Coding Integration
V4 ships with native integration into popular agentic coding harnesses — Claude Code, OpenClaw, and OpenCode all work with V4 via OpenAI ChatCompletions and Anthropic-compatible API endpoints. Three reasoning effort modes (Non-Think, Think High, Think Max) let callers tune compute-versus-quality per request rather than committing to a fixed configuration.
Computational Efficiency
The 73% reduction in per-token FLOPs at 1M context (versus V3.2) is what makes V4 viable both for cloud deployment and for self-hosted inference. This efficiency gain doesn’t trade off quality — instead, it enables longer context processing within the same compute budget that previously bought ~256K tokens of useful work.
Hardware Requirements
The actual hardware story for V4 is more demanding than the consumer-tier rumors suggested. V4-Pro at 1.6T total parameters requires substantial infrastructure even with FP4+FP8 mixed-precision quantization — the per-Hugging Face deployment notes confirm MoE expert weights at FP4, other weights at FP8.
For most teams, the API at $0.145/$1.74 per million input/output tokens (V4-Pro) or $0.14/$0.28 per million tokens (V4-Flash) will be substantially more economical than self-hosting unless data-residency or air-gap requirements force on-premises deployment.
Performance — Verified, Not Just Claimed
The original release-watch question was whether V4 would beat Claude Opus on coding benchmarks. The shipped numbers are now public, and they are strong but mixed. Official self-reported scores from the technical report:
| Benchmark | V4-Pro-Max | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 80.60% | 80.80% | — |
| LiveCodeBench | 93.5 | 88.8 | — |
| Terminal-Bench 2.0 | 67.90% | 65.40% | — |
| Codeforces ELO | 3,206 | — | 3,168 |
| HLE (Humanity’s Last Exam) | 37.70% | 40.00% | 39.80% |
| HMMT 2026 (math) | 95.20% | 96.20% | 97.70% |
Independent verification matters here, and it now exists. NIST’s Center for AI Standards and Innovation (CAISI) published an evaluation of V4-Pro on May 2, 2026 covering cyber, software engineering, natural sciences, abstract reasoning, and mathematics. Two findings worth noting:
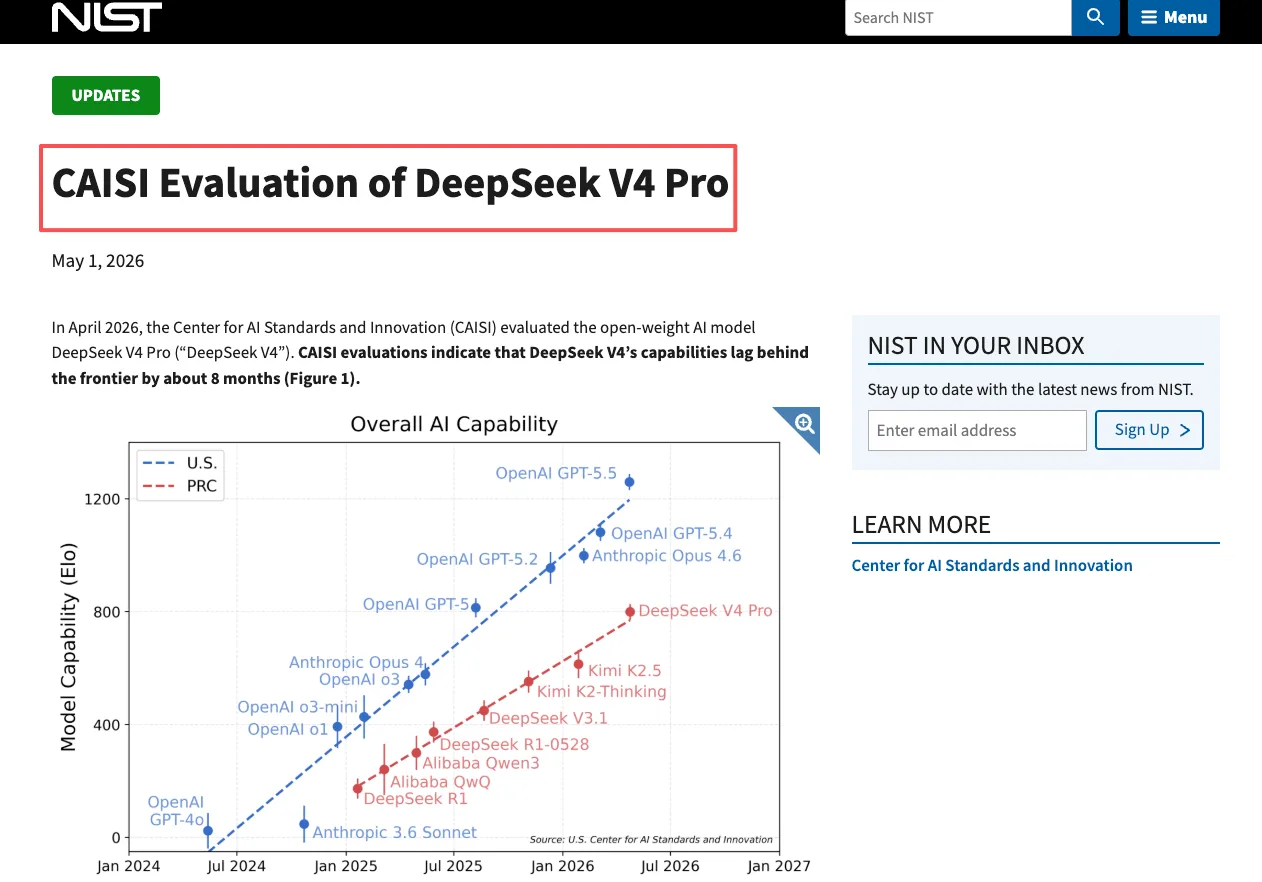
- CAISI confirms V4 is the most capable PRC AI model evaluated to date
- CAISI’s reproduced scores are systematically lower than DeepSeek’s self-reported numbers — the report attributes the gap to differences in scaffolding, system prompt, and token budget. Teams running V4 against their own evals should expect closer to CAISI’s numbers than DeepSeek’s headline figures.
The Council on Foreign Relations analysis frames V4 as roughly 3–6 months behind frontier U.S. models — a gap DeepSeek itself acknowledges in the technical report.
Open Source Impact
V4 ships under the MIT License rather than the Apache 2.0 some pre-release coverage anticipated — both are highly permissive, and for practical commercial purposes the difference is minimal. The license clarification matters because it removes the MAU caps and acceptable-use enforcement that complicate Llama-class deployments.
On-Premises and Air-Gapped Deployment
Organizations with strict data governance — finance, healthcare, defense — can run V4-Flash on a single-node multi-GPU setup, eliminating concerns about sending proprietary code to external APIs. V4-Pro is harder to self-host but doable for organizations with cluster-scale infrastructure.
Cost Advantages at Production Scale
The pricing is the disruption. V4-Pro at $1.74 per million output tokens is approximately 7× cheaper than Claude Opus 4.7 ($25/M) and GPT-5.5 on equivalent coding workloads. For high-volume agentic coding pipelines that burn millions of output tokens per day, this changes the build-versus-buy calculus.
Community Innovation
The open weights enable language-, framework-, or organization-specific fine-tuning. The MIT release allows commercial redistribution of derivatives, which previous DeepSeek licenses sometimes complicated.
What to Watch For Next
With V4 now public in preview, the open questions have shifted from “will it ship” to “how does it hold up”:
- Preview-to-stable transition: DeepSeek has not committed to a finalization timeline. Production teams should expect possible behavior changes before V4 reaches stable status.
- Real-world parity vs. benchmarks: The CAISI gap and reviewer reports of benchmark-versus-behavior discrepancies suggest teams should run domain-specific evals before migrating workloads.
- Compute supply: DeepSeek has acknowledged that V4-Pro serving capacity is constrained by available compute, partly tied to Huawei Ascend optimization. API rate limits may be tighter than the pricing implies.
- Distillation and IP disputes: Both Anthropic and OpenAI have publicly raised distillation concerns about earlier DeepSeek models; how this evolves under the V4 preview will affect enterprise procurement decisions.
- Competition within China: Moonshot’s Kimi K2.6 and Zhipu’s GLM 5.1 now perform comparably on most public benchmarks, narrowing the case for V4-Pro specifically over its domestic peers.
DeepSeek V4 is a serious release. The 31× cheaper coding-grade output, MIT-licensed weights, 1M-token economics, and strong agentic coding scores make it a credible alternative to closed-source frontier models for high-volume software engineering workloads — provided teams calibrate expectations to verified rather than self-reported benchmark numbers and accept the preview-status risk.
Frequently Asked Questions

Q1: Which model should I choose — V4-Pro or V4-Flash?
V4-Pro offers top coding performance (80.6% SWE-bench) for complex repository-level tasks. V4-Flash is much cheaper and faster for everyday use. Most teams should start with Flash.
Q2: Does DeepSeek V4 really support 1M context in production?
Yes. Both models support 1M-token context with hybrid attention, using only ~27% of the compute and 10% of the KV cache compared to V3.2, making it practical and cost-effective.
Q3: Can V4 replace Claude Opus or GPT-5 for coding?
V4-Pro matches or beats them on many coding benchmarks at 1/7th the price. However, expect slightly lower real-world results than self-reported scores. Test on your own tasks first.
Previous Posts:
Related Articles

Introducing ByteDance Seedream V5.0 Pro on WaveSpeedAI

Claude Fable 5 Just Shipped: 80.3% on SWE-Bench Pro, 2× Opus 4.8 Pricing, Free Through June 22
Gemini 3.5 Flash Shipped — A Flash-Tier Model Now Leads the Pro Tier on Agent Benchmarks
Gemini 3.5 Pro Is Coming Next Month — What the Flash Release Already Tells Us
Gemini 4.0 at Google I/O 2026: What's Confirmed, What's Anonymous-Sourced, What Builders Should Actually Watch For