Claude Mythos Coding Performance: What It Means for AI Dev Workflows
Claude Mythos reportedly scores dramatically higher on coding than Opus 4.6. Here's what that means for developers building AI coding agents in 2026.

Everyone zeroed in on the cybersecurity scare as Fortune dropped a bare bold healine saying: Anthropic had accidentally left nearly 3,000 internal files exposed, including a draft blog post hyping their unreleased model. But as someone who spends every day building with Claude, what caught my attention wasn’t the leak itself — it was the quiet, explosive claims buried in that draft about coding performance.
In this piece, you guys and I, Dora, are not going to chase hype or security panic but cut straight to what actually matters for developers and teams shipping real products through laying out exactly what we know (and what we don’t) about Claude Mythos / Capybara’s coding capabilities.
What the Leaked Draft Says About Claude Mythos Coding Performance
The precise claim from the leaked draft: “Compared to our previous best model, Claude Opus 4.6, Capybara gets dramatically higher scores on tests of software coding, academic reasoning, and cybersecurity, among others.”
That’s the entirety of what Anthropic put in writing about coding performance. No SWE-bench percentage, no Terminal-Bench score, no comparison table. The phrase “dramatically higher” is the actual signal — vague, but not meaningless.

For context, Opus 4.6 currently leads publicly available models on SWE-bench Verified (~80.8%), Terminal-Bench 2.0, and Humanity’s Last Exam. Anthropic’s official spokesperson confirmed the model represents “meaningful advances in reasoning, coding, and cybersecurity.” Training is complete, early access testing is underway, and coding is explicitly one of the three primary capability dimensions. Everything else is inference.
Why Coding Is the Most Important Capability for This Model Tier
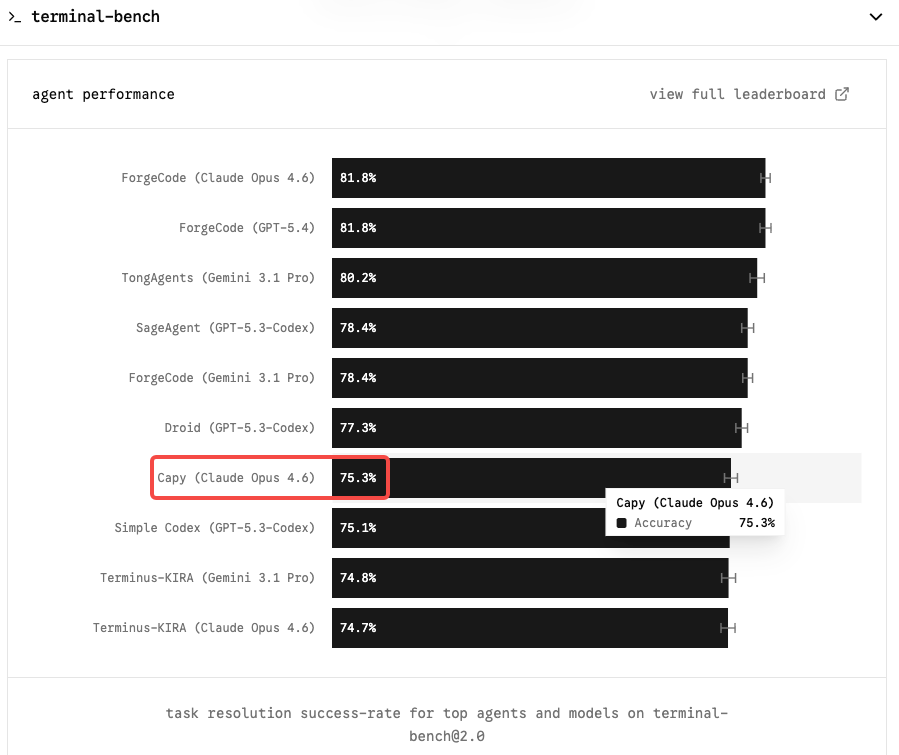
Terminal-Bench 2.0 Context and Current Opus 4.6 Scores
Terminal-Bench 2.0 is the benchmark that matters most for agentic coding workflows. Unlike SWE-bench, which tests isolated GitHub issue resolution, Terminal-Bench evaluates real tasks in a sandboxed terminal environment — system administration, DevOps, multi-step CLI workflows. It’s harder, more representative of production use, and less susceptible to scaffold-driven inflation.
Claude Opus 4.6 holds the top spot with 65.4% on Terminal-Bench 2.0 and 72.7% on OSWorld. A Capybara-tier model moving that number into the 75–85% range would be a genuine step change for any team running autonomous coding agents.
On SWE-bench Verified, the picture is more compressed: six models now score within 0.8 points of each other. Opus 4.6 sits at 80.8%; Gemini 3.1 Pro delivers 80.6% at $2/$12 per million tokens. Raw SWE-bench is no longer a meaningful differentiator. Terminal-Bench and long-context coherence are where Opus 4.6 earns its premium — and where Mythos will likely make its clearest case.
What “Dramatically Higher” Actually Means Structurally
In the draft, “dramatically higher” appears alongside “step change” — the same phrase Anthropic’s spokesperson used publicly. Neither term is casual. The jump from Opus 4.1 to Opus 4.6 was a generational improvement within the same tier. “Step change” implies something different in kind — more like the gap between Sonnet and Opus than between two consecutive Opus versions.
A model that meaningfully outperforms Opus 4.6 in coding would be a significant tool for software development, debugging, and agentic workflows. The open question is when it becomes available and at what cost. That’s the honest framing. The performance claim is credible given Anthropic’s recent track record. The validation is just not here yet.
Implications for Agentic Coding Workflows
Long-Context Code Tasks
The most immediate practical implication of a Capybara-tier model for coding teams isn’t raw benchmark scores — it’s what better reasoning does at scale.
Claude Code’s 1M context window is now GA for Opus 4.6, providing ~830K usable tokens after compaction — enough for entire monorepos and full documentation sets. A model that dramatically outperforms Opus 4.6 on coding, applied to that same window, means better architectural understanding across large codebases and fewer reasoning errors on multi-file refactoring. The context window doesn’t change. The quality of reasoning inside it would.
For teams doing large codebase analysis today — the kind of work where you’re loading 50K+ lines of source and asking the model to understand the full picture — this is the practical upgrade path that matters most.
Multi-Step Debugging Agents
Anthropic shipped Agent Teams as an experimental feature with the Opus 4.6 release, marking a significant step in agentic workflows. One session acts as the team lead — it coordinates work, assigns tasks, and synthesizes results. Teammates work independently, each in its own context window, and communicate directly with each other.
Multi-step debugging agents are where the compounding value of a better base model becomes clearest. In a multi-agent setup, the team lead’s planning quality determines how well the whole operation runs. A stronger model makes better task decomposition decisions, writes clearer task specs for subagents, and catches integration errors earlier.
The leaked draft specifically called out software coding alongside cybersecurity as the domains where Capybara “dramatically” outperforms Opus 4.6. If that gap is real and substantial on Terminal-Bench-style tasks, it would translate directly into more reliable multi-step debugging agents that require less human intervention to recover from wrong assumptions.
Self-Directed Codebase Exploration
This is the use case I’m most curious about in practice. Claude Code traces the issue through your codebase, identifies the root cause, and implements a fix. The quality of that tracing is a function of reasoning depth, not just context window size.
In a typical 2026 workflow, a developer might present a high-level requirement and the lead agent will decompose this into distinct tasks, with teammates utilizing the Model Context Protocol to access external tools, run tests, and perform security audits simultaneously. A Capybara-tier model running as the orchestrator in that kind of setup would make the entire workflow more autonomous — meaning fewer clarification requests, better initial task decomposition, and more reliable self-correction when a subagent hits an unexpected state.
What Builders Should Do Now While Mythos Is Not Available
How to Benchmark Opus 4.6 for Your Current Use Case
The single most useful thing you can do right now is run your own evaluation on Opus 4.6 — not against benchmarks, but against your actual workload. Generic benchmarks like SWE-bench test isolated issue resolution with standardized scaffolding. Your production coding agent has a specific codebase structure, a specific set of tasks, and a specific failure mode. Those are what matter.
A practical baseline evaluation for a coding agent might look like this:
# Simple task success rate tracking
results = {
"task_id": [],
"model": [],
"success": [],
"turns_needed": [],
"context_used_tokens": [],
"cost_usd": []
}
# Run the same 20-30 representative tasks through Opus 4.6
# Track: did it succeed on first attempt? How many turns?
# What fraction of the 1M context window did it consume?
# Where did it fail — reasoning error, tool use, or context overflow?The reason this matters: when Mythos does become available, you’ll have a real baseline for evaluating whether the capability improvement justifies the cost premium for your specific workflow. “Dramatically higher” on Anthropic’s internal test suite may or may not translate to a meaningful difference in your particular codebase structure and task distribution.
The ‘best model’ is the one that matches how you communicate with it. A mid-tier model in a great harness beats a frontier model in a bad one. Your harness quality — prompt engineering, tool configuration, CLAUDE.md structure — is a variable you can improve now. Mythos won’t fix a poorly designed agent architecture.
Architecture Decisions That Will Scale with a More Capable Model
The good news is that well-designed agentic architectures are model-agnostic at the routing layer. The patterns worth building toward now:
Separate orchestration from execution. An orchestrator agent that decomposes tasks, assigns files, and reviews outputs — backed by specialized subagents for implementation — can swap its base model with a single parameter change. Build this separation now and the Mythos upgrade becomes a configuration update, not an architectural refactor.
Use CLAUDE.md as runtime context, not session-specific prompting. The CLAUDE.md file serves as the “constitution” for AI agents within a repository — providing the necessary context on project architecture, coding standards, and build commands that allow agents to operate without human nanomanagement. A well-structured CLAUDE.md reduces per-task exploration costs on Opus 4.6 today and will amplify the gains from a stronger model tomorrow.
Design for the 1M context window, not against it. Teams that have already restructured their file loading strategy, chunking logic, and context management to work within the 1M window will be positioned to take full advantage of Mythos’s reasoning capability across that same window. Don’t build workarounds for context limits that assume the ceiling won’t rise.
What to Watch at Launch for Coding-Specific Teams
The signals that matter most for developers are different from general enterprise signals. For coding-focused teams specifically:
SWE-bench and Terminal-Bench scores at launch. Anthropic has historically published these alongside model releases. If Mythos delivers on the “dramatically higher” claim, you’d expect Terminal-Bench 2.0 scores to move meaningfully above Opus 4.6’s 65.4%. A jump to 75%+ would validate the claim for agentic workflows.
Claude Code model string update. Check the Claude Code docs and the API models overview for a new model alias. Claude Code has historically updated its default model within days of a new flagship release. If Mythos ships to the public API, this is where it will surface first for coding teams.
Agent Teams compatibility announcement. Agent Teams shipped as experimental with Opus 4.6. Whether Mythos integrates natively with Agent Teams at launch — or requires a separate configuration — will determine how quickly teams can move it into multi-agent workflows.
The Anthropic changelog and pricing documentation. These two pages are the earliest reliable signal before any press announcement. A new model string and a new pricing row will appear here first.
FAQ
Is Claude Mythos available for coding tasks now?
No. As of early April 2026, there is no public API endpoint for Claude Mythos or the Capybara tier. Claude Mythos / Capybara is available only to a small group of early access customers selected by Anthropic, with no public API, no announced pricing, and no confirmed release date. Claude Opus 4.6 — 80.8% on SWE-bench Verified, 65.4% on Terminal-Bench 2.0 — remains the best publicly available option.
Will Claude Mythos work with Claude Code?
Almost certainly yes, eventually. Claude Code’s architecture is model-agnostic; switching to a new flagship is a single parameter change. But this is not confirmed for Mythos at launch.
Should I wait for Mythos to build my AI coding tool?
No. Anthropic has stated it needs to become “much more efficient before any general release.” Building on Opus 4.6 now means your architecture is production-validated when Mythos arrives. The upgrade will be a model string swap. The teams that wait will be playing catch-up.
Previous Posts:
Related Articles

Claude Code Hidden Features Found in the Leaked Source: Full List (2026)

claw-code Pricing and Access in 2026: What You Actually Pay

7 Best Free AI Avatar Generators in 2026

10 Best Free AI Image Generators in 2026

8 Best Free AI Video Generators in 2026
