What Is Unlimited-OCR? Long-Document Parsing Explained
Learn how Unlimited-OCR uses R-SWA and constant KV cache for long-document parsing, where it fits, and its practical limits.

Hello, I’m Dora. I’ve been running multi-page PDFs through OCR pipelines for about a year now — invoices, scanned reports, the occasional 40-page technical manual a client drops on me with no warning. The part that breaks isn’t usually the text recognition. It’s what happens around page 10, when the model starts forgetting it’s still inside the same document.
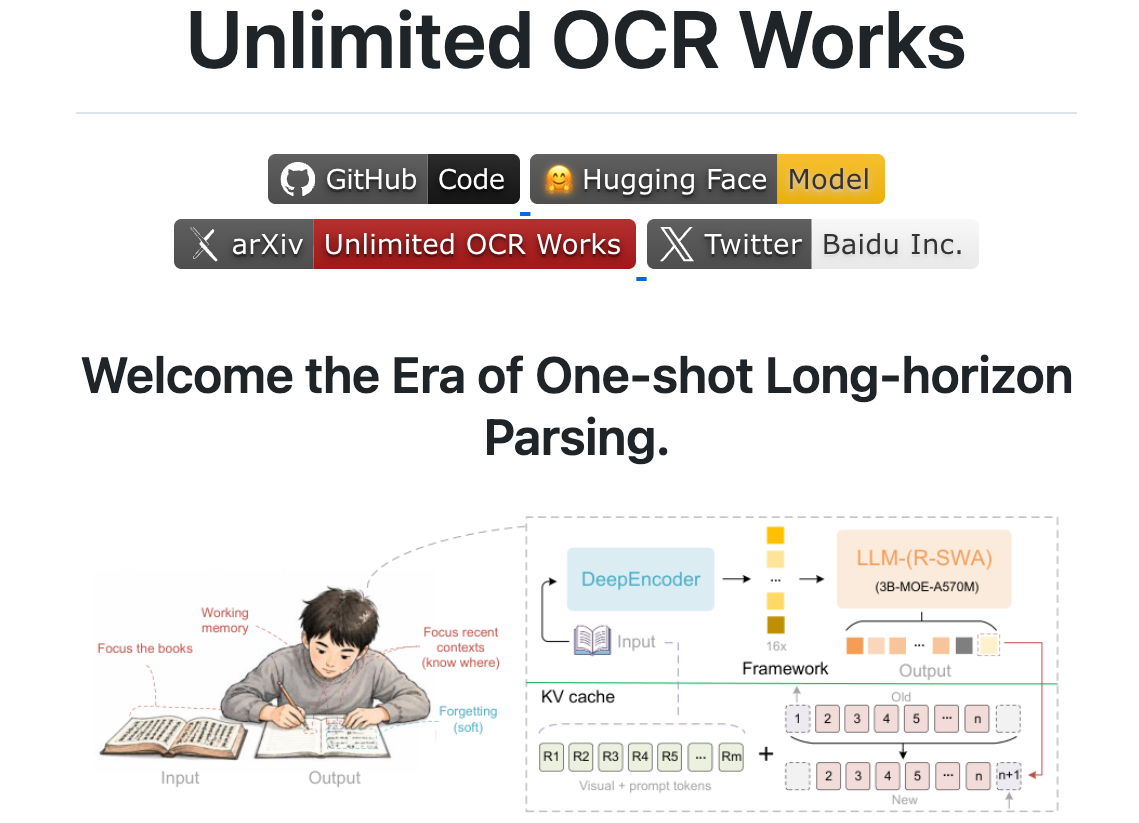
That’s the problem Unlimited-OCR — Baidu’s open-source model released on June 22 — is built to address. Not “OCR a single image better.” Read dozens of pages in one pass without the KV cache exploding. Released under MIT license, 3B parameters, 32K-token standard context. The interesting part isn’t the parameter count. It’s the attention rewrite that makes single-pass long-document parsing actually tractable.
Below is what the model is, how its core mechanism works, and where I’d actually trust it in a production pipeline versus where I’d still hold back.
What Unlimited-OCR Is
Unlimited-OCR is a 3B-parameter Mixture-of-Experts model with about 500M activated per token. It was open-sourced by Baidu on June 22, 2026, with weights, inference code, and a technical report all dropped at the same time. The GitHub repository and the Hugging Face model card are both public.
The baseline it builds on is DeepSeek-OCR — not DeepSeek-OCR 2, which is a separate lineage. This matters because the encoder side is essentially borrowed. Baidu kept the DeepSeek-OCR DeepEncoder design: SAM-ViT cascaded with CLIP-ViT, 16× token compression, a 1024×1024 page reduced to roughly 256 visual tokens. The encoder isn’t the contribution. The decoder is.
What’s different from “conventional OCR services” — the Baidu OCR cloud APIs most enterprises are currently paying for, or any pipeline OCR stack like PaddleOCR, MinerU, Marker — is the architecture itself. Pipeline OCR splits the job: detection model → recognition model → layout reconstruction → table extraction. Each handoff is a place where errors compound. End-to-end OCR models like DeepSeek-OCR collapse all of that into one decoder. Unlimited-OCR keeps the end-to-end shape and removes the practical ceiling on output length that previous end-to-end models hit.
One thing worth being precise about: this is open-source OCR with open weights, which is not the same as “open commercial use.” The MIT license on the model itself is permissive. What that means for your specific deployment — I’ll come back to in the FAQ.
How R-SWA Enables Long-Document Parsing
The mechanism behind Unlimited-OCR is called Reference Sliding Window Attention, or R-SWA. The full description is in the Unlimited OCR Works technical report, but the practical version is short.
Standard end-to-end OCR uses an LLM decoder. The KV cache grows linearly with every token generated. By page 10 of a long document, the cache is large enough that decoding slows down noticeably, and by page 20 you’re either out of memory or quality starts degrading because attention is spread too thin. The workaround most teams use is to chunk: process page-by-page in a loop, clear cache between pages. It works. It also breaks the continuity that end-to-end models were supposed to preserve — cross-page references, table continuations, section numbering all become someone else’s problem to stitch back together.
R-SWA splits attention into two parts that stay constant in size. Every generated token attends to two things only:
- All reference tokens — the visual tokens from the encoder, plus the prompt. These stay visible the entire time.
- The most recent 128 output tokens — a sliding window over what the model just wrote.
Everything older than 128 tokens of generated output falls outside the window and gets soft-forgotten. The visual tokens — the actual page content — never leave. So the model can keep producing output for pages and pages, and the KV cache size stays flat instead of climbing.
The 128-token window is the default. The standard max output is 32,768 tokens. In the report’s tests, that’s enough to transcribe dozens of pages in a single forward pass — no chunking loop, no cache clear, no manual stitching.
R-SWA also produced a modest accuracy bump on OmniDocBench v1.5 — text edit distance dropped by 0.035 versus the DeepSeek-OCR baseline, table TEDS improved by about 6%. Baidu’s framing is that this isn’t an OCR-specific trick. It’s a general-purpose parsing attention pattern that could apply to ASR transcripts, translation, anything where you read a fixed reference and write a long sequence off it.
Production Fit, Limits, and Evaluation
This is where I get cautious. The benchmark numbers are clean. Production conditions usually aren’t.
Where it actually fits. The clearest cases I’d reach for Unlimited-OCR over a pipeline OCR stack:
- Multi-page technical manuals or research papers where section structure, table continuations, and cross-page references need to survive.
- Legal archives or contract bundles — long documents with consistent formatting where chunking causes more downstream cleanup than it saves.
- Any pipeline currently using a for-loop over single-page DeepSeek-OCR calls. That’s the most direct upgrade path.
Where I’d still hold back. A few things the paper doesn’t promise, and you shouldn’t either:
- Mixed-quality scans. The encoder is the same DeepEncoder. If single-page recognition struggles on faded scans or heavy handwriting, the long-form version inherits that — it doesn’t fix the input.
- Anything beyond 32K output tokens. R-SWA keeps the cache constant during decoding, but the standard max length is still 32K. Past that, you’re back to chunking.
- High-volume, latency-sensitive workloads. The compute cost per token drops with R-SWA, but a 3B MoE on a single 1024×1024 page still needs GPU. If you’re processing thousands of single-page invoices a day, page-level alternatives may still win on throughput and cost.
How I’d evaluate it. Don’t trust OmniDocBench scores alone. The benchmark is real — OmniDocBench is a CVPR 2025 paper with public eval code — but your document distribution isn’t its document distribution. The check I’d run:
- Pick 20 documents from your actual pipeline. Mix page counts, mix scan quality.
- Run them through your current OCR stack and through Unlimited-OCR.
- Compare on three things: text accuracy, table structure preservation, and whether you need to manually fix page-boundary errors.
- Time the full pipeline end-to-end, not just inference. A faster decoder doesn’t help if pre-processing dominates.
If the model gives you cleaner long-document output with less post-stitching, the migration is worth it. If it’s a wash, stay on what works.
FAQ
Does R-SWA preserve consistency across very long document outputs?
The report shows constant KV cache and stable decoding up to 32K tokens. Consistency on your specific document type — section numbering staying continuous, table rows not duplicating across page breaks — needs your own validation. The mechanism is built for it. Whether your documents behave as expected is testable, not assumable.
Can teams audit page boundaries after one-shot parsing?
The model outputs a continuous token stream — it doesn’t natively emit page markers unless prompted to. If audit trails matter (legal, compliance), you’ll want to prompt for explicit page tags in the output and verify them post-hoc. This is a workflow design choice, not a model limitation.
How does mixed handwriting affect long-document parsing reliability?
The DeepEncoder wasn’t designed primarily for handwriting. Mixed printed-and-handwritten documents will likely degrade in proportion to how much handwriting is present. R-SWA doesn’t change that — it changes how long the model can keep generating, not what it can recognize. If your documents are handwriting-heavy, run a dedicated test before committing.
Does the MIT license cover commercial deployment?
The model weights are MIT-licensed. For your specific commercial deployment — what you produce, how you redistribute, what compliance obligations apply in your jurisdiction — check the latest license file on the official repository and confirm with your legal team. I’m not the right source for that decision.
Conclusion
Unlimited-OCR is a focused contribution: keep DeepSeek-OCR’s encoder, replace the decoder’s attention with R-SWA, get dozens of pages in one pass with a constant KV cache. Open weights, MIT-licensed, 32K standard context. That’s the whole pitch.
For teams currently running for-loops over single-page OCR or stitching outputs across chunks, this is worth a real test. For everyone else — the benchmark wins are modest at the single-page level, and the architecture’s main value shows up at length. Run it against your own documents. That’ll tell you more than I can.
More to come once I’ve had it in a pipeline for a couple of weeks.
Previous posts: