RTKとは何か、そしてなぜトークン効率が重要なのか
RTKはAIコーディングワークフローにおけるトークンの多い端末出力を削減します。2026年において、トークン効率がほとんどのチームが気づいている以上に重要な理由を解説します。

最初は単なる苛立ちとして気づいた。RustプロジェクトでのClaude Codeの30分セッションが、エージェントの「何を作業していたか分からなくなった」という言葉で終わることがあった。モデルの失敗ではなく、コンテキストウィンドウの問題だ。使用量を確認すると、200Kウィンドウのうち約118Kがcargo testの出力、git statusのダンプ、そして冗長なfindコマンドひとつに食い潰されていた。
それがRTK AIを単なる好奇心ではなく、真剣な検索ワードにした瞬間だった。トークン効率はもはや「あれば便利な最適化」ではなく、エージェントがシェルの定型文でコンテキストが溺れる前にどれだけ長くコードについて推論し続けられるかという、ハードな制約になっている。この記事は、RTKとは何か、ai codingトークンコストの広い問題が課金からインフラへとシフトした理由、そしてこの種のツールがどこに位置するかについてだ。
免責事項:私はWaveSpeedAIに隣接するエージェントインフラに携わっている。RTKとは商業的な関係はない。ここでのフレーミングはカテゴリについてのものであり、特定のツールについてではない。
RTKとは何か、なぜトレンドになっているのか
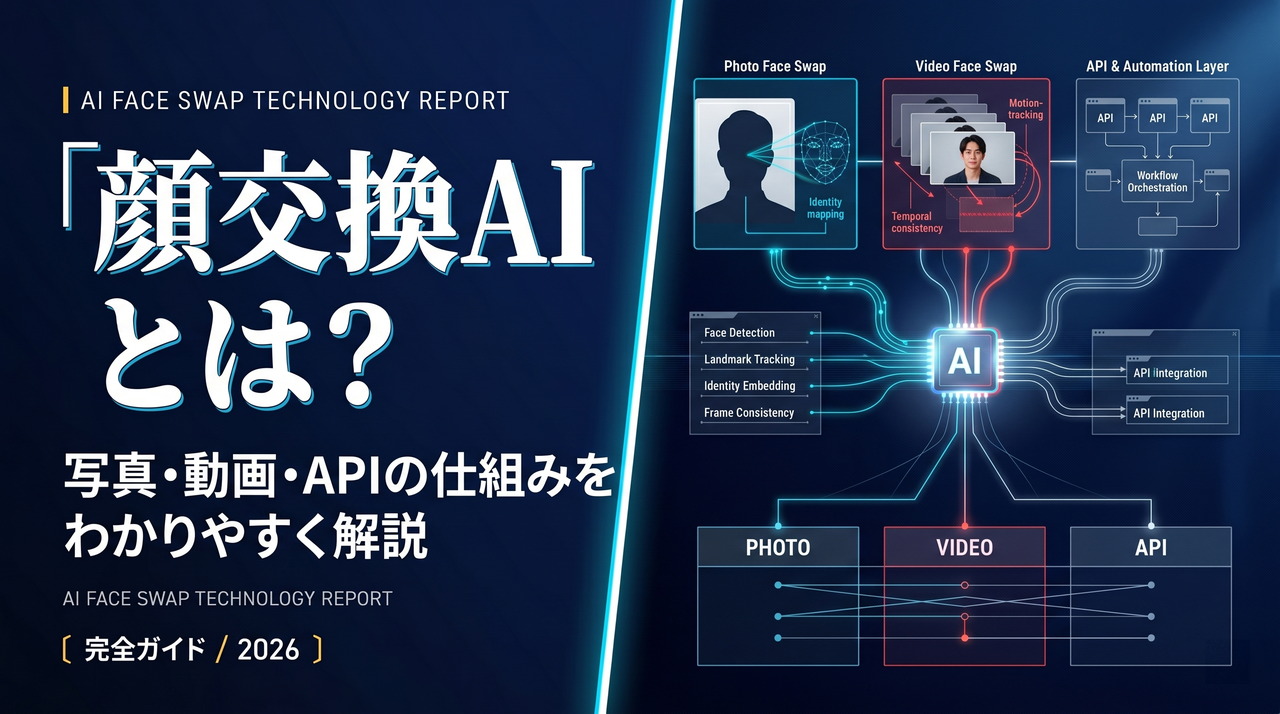
RTK(Rust Token Killer)は、Rustで書かれたオープンソースのCLIプロキシで、MITライセンスを持ち、シェルコマンドの出力がAIコーディングエージェントのコンテキストウィンドウに届く前に傍受する。READMEと公式サイトによると、100以上のサポートコマンドで60〜90%のトークン削減を主張している。2026年4月末時点でリポジトリはv0.38.0で活発に開発中だ。

仕組みは単一のバイナリだ。エージェント向けにrtk init -gを実行すると、Claude Code、Cursor、Copilot、Gemini CLI、Codex、Windsurf、Clineなどがサポートされている。透過的にgit statusをrtk git statusに、cargo testをrtk cargo testに書き換えるPreToolUseフックをインストールする。エージェントは書き換えが起きたことを知らない。ただ、より小さく圧縮された出力を見るだけだ。
ターミナルワークフローで実際に何が変わるのか
標準のgit status出力は、約80トークンのヒントテキスト(「git add…」アドバイス、ブランチトラッキングの定型文、指示)に包まれた約120トークンの有用な情報を出力する。RTKはヒントを取り除き、ファイルリストを残す。モデルにとっては同じ情報で、ノイズは約60〜75%少なくなる。
cargo testは圧縮が面白くなるところだ。262個のテストが通り3個が失敗する実行では、262行のtest::name ... okに加えて3つの失敗トレースが出力される。エージェントが必要なのは失敗トレースとカウントだけだ。RTKはノイズをグループ化し、シグナルを保持する。著者は15日間で7,061コマンドにわたって2,460万トークンを節約したShow HNベンチマークを投稿しており、自身の使用量で83.7%の効率を示している。
これは作業方法を変えないtokenoptimization cliだ。git statusと入力し続ける。エージェントはgit statusを呼び続ける。その間を行き来するバイトが縮小される。

出力圧縮がエージェントツールにとって重要な理由
出力圧縮はトークンを節約するだけではない。エージェントが読むものに関わっている。200Kのコンテキストウィンドウは大きく聞こえるが、計算してみると:セッションあたり60のシェルコマンド × 生の出力あたり約3,500トークン = 210Kトークンのノイズ。エージェントがコードの一行も推論する前にウィンドウを超えてしまう。
RTKプロジェクトのドキュメントが正しく指摘している部分はここだ:コストはトークン単価だけでなく、モデルがもはやあなたの問題を明確に見られないことにある。圧縮は選択的注意の一形態だ。定型文を取り除くことで、モデルは限られた注意をシグナルに使えるようになる。
トークン効率がインフラのトピックになった理由
1年前、「トークンコスト」は請求書の項目だった。2026年にはエージェント設計上の制約だ。三つのことが変わった。
コスト、レイテンシ、コンテキストの無駄
価格の計算が劇的に悪化したわけではない。AnthropicのAPI公式価格ではSonnet 4.6が100万トークンあたり3ドル/15ドルで、標準料金で最大100万のコンテキストウィンドウとなっている。変わったのは自律エージェントがセッションあたりに消費するトークン数だ。10Kトークンのシステムプロンプトで50回のツール呼び出しをするコーディングエージェントは、キャッシュを無視すると、そのシステムプロンプトだけで500Kトークンを支払う。
プロンプトキャッシングはこれを和らげる。キャッシュ読み取りはベース入力価格の0.1倍で、キャッシュされたプレフィックスに90%の割引がある。しかしキャッシングは会話の静的な部分にしか効かない。動的なサフィックス、つまりツール呼び出しの出力、中間の推論、生成されたコードには効かない。それがまさにRTKが狙う表面だ。キャッシングと出力圧縮は補完的であり、競合しない。
レイテンシも同じ形だ。より小さなペイロードは速く移動し、処理される。多くの短いツール呼び出しを連続して行う自律コーディングエージェントにとって、rtkのトークン節約は実際の経過時間の改善としても現れる。

ノイズの多いコマンド出力がエージェントの信頼性を壊す理由
これは請求書に表れない部分だ。エージェントのコンテキストがcargo test ok行や冗長なfind出力で溢れると、二つの失敗モードがより頻繁になる。
エージェントは5回前のツール呼び出しで何をしていたかを見失う。具体的には、元のユーザーリクエストがコンテキストの後ろに押しやられ、モデルの注意が最近の(ノイズの多い)ツール出力に向いてしまう。Claude Codeのセッションが、ユーザーが単一のテストを修正したかったことを忘れ、コンテキストの最も顕著なものが最後の4Kトークンのgrepダンプだったために、テストに隣接するコードをリファクタリングし始めるのを見たことがある。
コンテキストのオーバーフローはセッションの再起動を強制する。上限に達したら、会話を要約(忠実度を失う)するか、最初からやり直す(完全にスレッドを失う)かのどちらかだ。どちらにしても、失敗のコストを払うことになる。
ボトルネックは、実はモデルではなかったことが判明した。モデルが生産的に使える以上のバイトを運ぶ、シェルとコンテキストの間の中間チャネルだったのだ。
RTK AIの適所と不適所
RTKが適切なツールである条件は三つある:ループの一部としてシェルコマンドを実行するエージェントを使っていること、実行するコマンドがサポートリスト(git、cargo、npm、pytest、go test、find、grep、ls、docker、kubectl、その他約100)にあること、そしてワークフローがトークン制限に縛られていること、つまりAPIの請求書または定額プランのクォータに対してだ。
適さない場合:
- エージェントが大半の操作にフレームワークネイティブのファイルツール(Claude CodeのRead、Grep、Glob)を使っている場合。RTKフックはBashツール呼び出しのみを捉える。ネイティブツールはそれを迂回する。プロジェクトのREADMEはこれを明示している。ネイティブツールのワークフローをフィルタするには、
rtk readやrtk grepを明示的に呼び出す必要がある。 - WSLなしのWindowsの場合。RTKはCLAUDE.mdインジェクションモードにフォールバックし、指示を与えるが自動書き換えはしない。機能はするが透過的ではない。
- ボトルネックがツール呼び出しのノイズではない場合。エージェントが大半のトークンを長い生成コードや拡張された推論に費やしているなら、
git statusを圧縮しても一桁パーセントの節約にしかならない。インストール前に診断すること。
オンラインでよく見るvibecoding cost reductionのフレーミング、「これをインストールすれば請求が80%削減される」は半分正しい。80%はコンテキストのCLI部分に適用される。セッションの70%がCLI出力なら全体で約56%節約できる。30%なら約24%だ。インストール前に典型的なセッションでrtk discoverを実行すること。ランディングページのベンチマーク数値は上限だ。
この記事を書きながら数日間立ち止まった。より広いポイントは実はRTK自体についてではないからだ。私たちは今、1年前にはインフラ層として認識されていなかった新興カテゴリ、コンテキスト層の最適化を持っている。RTKはその一形態だ。プロンプトキャッシングは別の形態だ。自動コンテキスト要約を行うエージェントフレームワークは三番目だ。これらはすべて同じ問題の側面を解決している:トークンは新しい帯域幅であり、ツールとモデルの間のチャネルには、HTTPが25年前に得たのと同じ種類の圧縮層が必要だ。

FAQ
これらはインストールが価値があるかどうか評価しながら出てきた質問だ。
RTKは実際に何を最適化するのか?
RTKはエージェントのツール呼び出しの出力側を最適化する。つまり、シェルコマンドによって返されたバイトストリームが、モデルのコンテキストウィンドウに到達する前の部分だ。ドキュメントによると、四つの戦略を使っている:スマートフィルタリング(コメント、定型文、ヒントテキストを除去)、グループ化(類似アイテムを集約)、切り詰め(骨格を保持し、二次的な詳細をトリミング)、構造化要約(262個のパステスト → 1行のカウント行、失敗はそのまま保持)。エージェントが実行するコマンドは変更しない。見えてくるものだけを変える。
トークン効率はレイテンシにも効くのか?
はい、ただし間接的に。より小さな入力は速く処理される。Anthropicのプロンプトキャッシングドキュメントでは長いキャッシュされたプロンプトで最大85%のレイテンシ削減を報告しており、同じ論理が入力側の縮小にも適用される。素早いツール呼び出しシーケンスを行う自律エージェントにとって、累積効果は顕著だ。モデルが主に考えている単一の長形式応答では、効果は小さい。
RTK AIのようなツールから最も恩恵を受けるチームはどこか?
三つのプロファイルがある。高頻度でコーディングエージェントを実行するチームで、トークン消費が実際の費用項目になっている。定額プランでレート制限に予想以上に早くぶつかっているチーム。RTKはプランを変えずに実質的なクォータを拡張する。すべてのツール呼び出しが自社インフラの請求書の中にあるエージェント製品を構築しているチーム。四番目のプロファイル、週2回AIエージェントを使う偶発的なユーザーは違いに気づかないだろう。
トークンの最適化がメインのボトルネックでない場合はいつか?
エージェントがコンテキストサイズとは無関係の理由で失敗する場合:ツール設計の悪さ、モデルの誤った選択、指示の欠如、曖昧なユーザーインテント。トークンの最適化はスコープが不明確なエージェントを修正しない。また、ワークロードが生成ではなくツール出力の読み取りに支配されている場合にも効かない。ここが私のデータの終わりだ。CLI重視のコーディングワークフローへのRTKの影響しか測定していない。
結論
RTK AIの最速のまとめ:エージェントに届く前にシェルコマンドの出力を圧縮するCLIプロキシで、サポートされているコマンドで60〜90%のトークン削減を主張している。より遅く、より有用なまとめ:トークン効率が最適化であることをやめてインフラ層になった理由の実例だ。コンテキストは有限だ。請求書は現実だ。チャネルがノイズだらけになるとエージェントの信頼性は低下する。
RTKが特にあなたのワークフローに属するかどうかは、トークンが実際にどこへ行くかによる。それが代表するカテゴリ、エージェントとそのツール出力の間の圧縮とフィルタリングは、どの特定のバイナリが勝つかに関わらず重要になるだろう。
詳細な前後比較の数値と共に数週間のプロジェクトでRTKを実行したら、また続きを書く。トークンは今や請求書の脚注ではなく、インフラの問題だ。
過去の投稿: