GPT-5.6 Sol vs Terra vs Luna for Production
Compare GPT-5.6 Sol, Terra, and Luna for production routing strategy, eval design, fallback rules, cache behavior, and monitoring.

The first routing table I would build for GPT-5.6 Sol has three empty cells: pass line, fallback, and cost per successful task. Not model name. Not “best tier.” Those are easy to fill in. Too easy.
The hard part is deciding when Sol is allowed to receive traffic, when Terra is good enough, and when Luna should stay on the cheap, predictable lane. If that decision is not written down before testing, the strongest tier slowly becomes the default tier. Usually by accident.
I paused here because the empty cells matter more than the model names.
Quick Verdict for Production Teams
Start from workload value, not model hype
OpenAI frames GPT-5.6 as a three-tier family. The GPT-5.6 announcement positions Sol as the highest-capability tier, Terra as the balanced tier, and Luna as the faster, lower-cost tier.
That framing is useful. It is not a production guarantee.
I would start from failure cost. A weak internal summary is annoying. A wrong customer escalation is expensive. A broken code-generation task can create review debt for three people. These are not the same workload, so they should not share the same default model.
| Workload | First tier to test | Why |
|---|---|---|
| Intent routing / tagging | Luna | Stable shape, high volume, low failure cost |
| Structured extraction | Luna → Terra | Schema validity decides |
| Support drafting | Terra | Quality and cost both matter |
| Tool-heavy agent tasks | Terra → Sol | Escalate after tool failure or high-value context |
| Complex coding / analysis | Sol | Expensive mistakes justify stronger evals |
This is not a routing policy. It is where I would start testing.
Why one default tier is rarely enough
One default tier looks clean in a registry. It rarely matches the system. If everything goes to Luna, hard cases leak quality. If everything goes to Terra, simple tasks may overpay. If everything goes to Sol, the bill becomes a design critique.
A production router needs lanes. Cheap predictable work. Normal reasoning. Expensive edge cases. Fallback when preview access changes. Good enough for a prototype. Not for production AI.
Tier Routing Strategy
Luna for high-volume predictable tasks
I would test GPT-5.6 Luna first where the task shape is stable. Intent classification. Short extraction. FAQ matching. Low-risk summarization. Rewrite tasks where the acceptable output range is narrow.
The reason is not that Luna is guaranteed to be fast on your workload. It is not. Latency depends on prompt length, output length, cache behavior, traffic mode, and whatever else your system is doing that day.
The reason is exposure. High-volume tasks make small cost differences visible quickly. If Luna clears the quality floor, it should probably own that lane.
Terra for balanced quality and cost
GPT-5.6 Terra is where I would expect many product teams to begin serious testing. It fits support drafting, internal assistants, structured reasoning, moderate tool use, and workflows where quality matters but Sol is hard to justify on every request.
Terra is also the useful middle control. If Luna is too brittle and Sol is too expensive, Terra tells you whether OpenAI 5.6 works for the workload at all.
I would compare Terra against the current production model. Not against a mood. Not against a model family chart. Against the thing already handling traffic.
Sol for high-value complex tasks after evals
GPT-5.6 Sol belongs where mistakes cost more than tokens.
Complex coding. Multi-step analysis. Tool-heavy agent loops. Security review support. Customer escalations. Anything where a wrong answer creates follow-up work, user risk, or review debt.
I would not route every complex-looking request to Sol. I would route Sol after Terra fails, after uncertainty gets high, or when the task class already proved Sol earns its cost.
The pattern is boring: start lower when the task is stable, escalate when risk changes.
Eval Design Before Routing Traffic
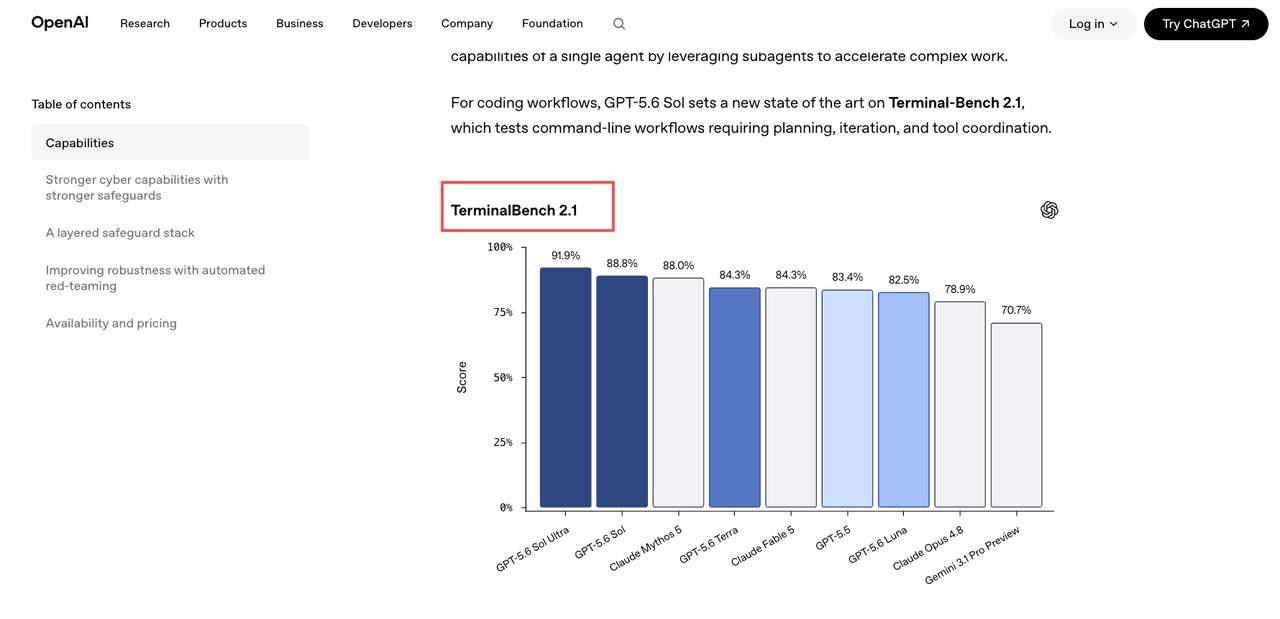
Quality floor, tool use, coding tasks, latency, refusal behavior
I would build one sheet per workload class. A JSON extractor cares about schema validity and field accuracy. A coding assistant cares about test completion and regressions. A support agent cares about escalation, refusal behavior, and hallucination. A summarizer cares about factual compression.
A single “model score” hides the exact reason a tier should receive traffic.
For routing, the useful unit is cost per successful task. Not token price. Not benchmark position. A cheaper tier that retries twice may stop being cheap. GPT-5.6 Sol may look expensive until it removes human review from a high-value task.
So that is where the bottleneck was.
Pass/fail thresholds by workload class
Set pass lines before testing. Otherwise the result becomes a meeting.
| Workload class | Main gate | Routing implication |
|---|---|---|
| Classification | Accuracy and regression rate | Luna only if it stays stable at volume |
| Structured extraction | Schema validity and field accuracy | Escalate to Terra when downstream repair rises |
| Support drafting | Escalation and hallucination rate | Terra first; Sol for high-value or risky cases |
| Coding tasks | Test pass rate and regression behavior | Sol only after it beats the current baseline |
| Agent workflows | Tool-call accuracy and recovery | Terra first; Sol for complex loops |
The exact numbers depend on the product. The gates should not. Each tier earns a lane. No lane, no traffic.
Cache and Fallback Breakpoints
Prompt-prefix stability and cache hit rate
Prompt caching changes the math.
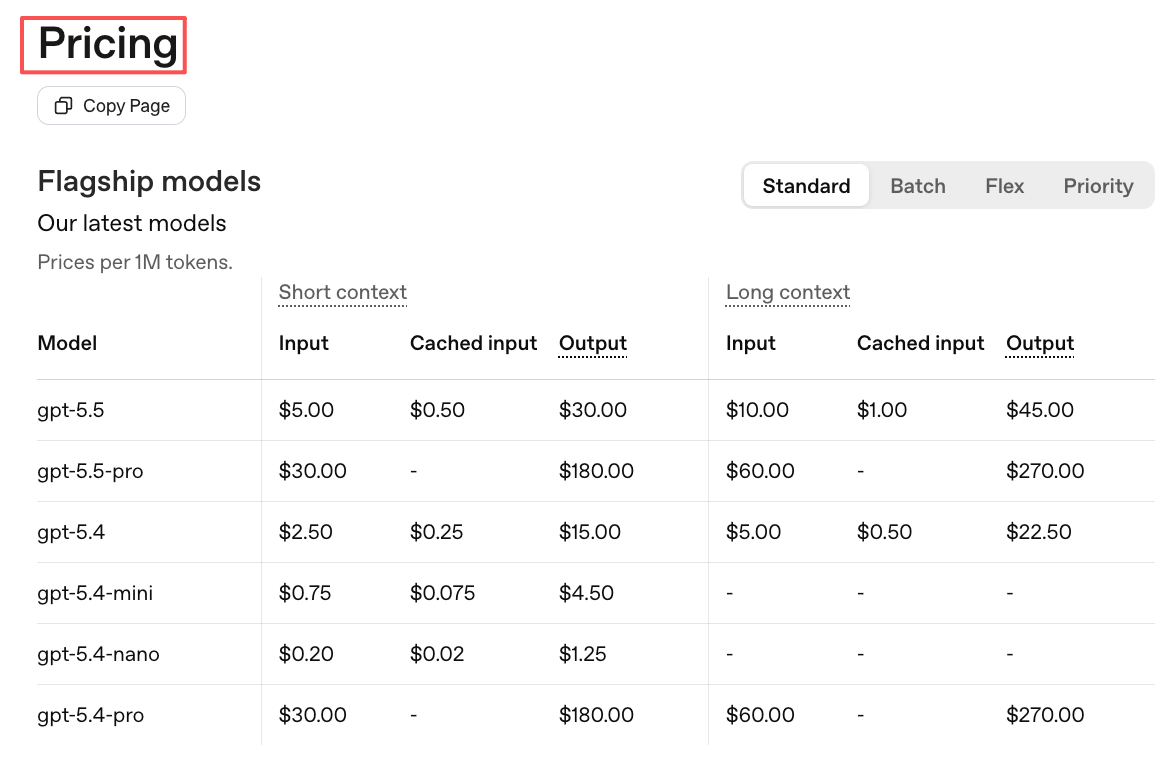
OpenAI says GPT-5.6 introduces explicit cache breakpoints and a minimum cache life. I would still check the official pricing page before putting any estimate into deployment planning.
A stable prefix makes higher tiers more realistic. A constantly changing prefix does the opposite. If every request rebuilds the system prompt, cached-input pricing is not the price you are actually paying.
I would measure cache hit rate by workload, not globally. A support assistant and a code agent can have completely different cache behavior. Averaging them together makes the dashboard calmer than the system.
Escalation, degradation, and rollback rules
Routing needs rules before launch.
Escalation decides when Luna hands off to Terra, and when Terra hands off to Sol. Low confidence, schema failure, tool-call failure, policy ambiguity, high-value user context, and repeated retries are common triggers.
Degradation decides what happens when preview access changes or capacity tightens. Terra is not automatically a safe replacement for Sol. Luna is not automatically a safe replacement for Terra. The fallback tier must have passed the same workload gate.
Rollback decides when the system returns to the previous production model. I would define that around cost per successful task, p95 latency, error rate, retry rate, and human review rate.
Fallback is not a mood. It is a rule.
Production Monitoring
Cost per successful task, latency, cache hit rate, error rate
Once traffic starts, I would monitor by tier and workload class.
Cost per successful task tells me whether the route is economical. p95 latency tells me whether users feel the delay. Cache hit rate tells me whether the pricing assumption was real. Error rate and retry rate show whether a tier is quietly failing behind a clean UI.
Escalation rate is the one I would watch closely. If Luna escalates most of its traffic to Terra, Luna is not the first lane. It is a delay. If Terra escalates too often to Sol, Terra may be underpowered for that workload. If Sol still needs human review, the workflow may need redesign, not a stronger model.
Tier drift and preview access changes
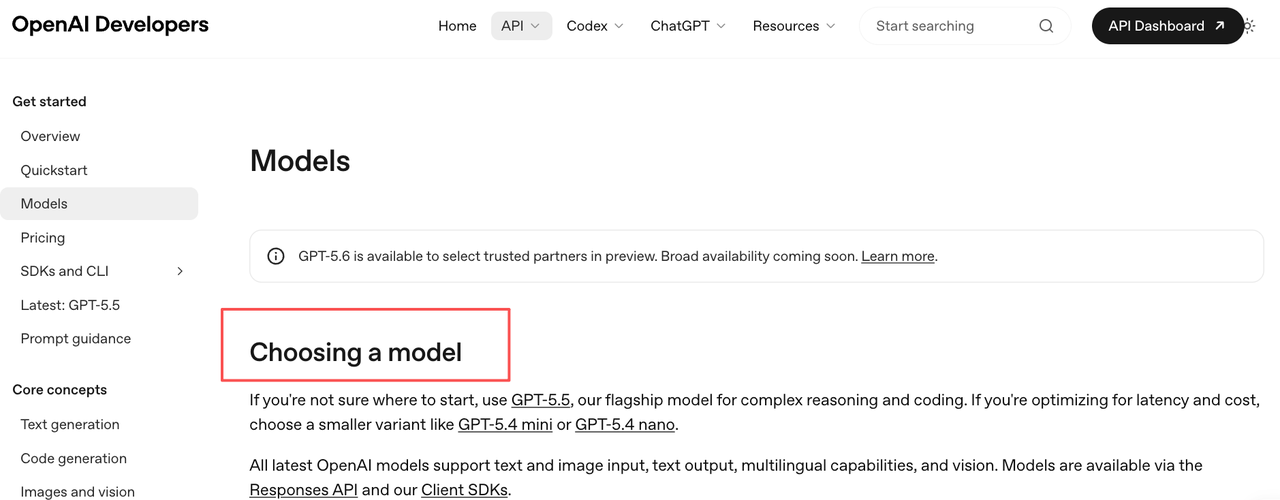
GPT-5.6 is still preview-limited for select partners on the OpenAI models page. That status matters for routing.
I would keep tier status in the internal registry: preview, limited production, approved production, paused, deprecated. The router should read that registry. It should not rely on someone remembering what was available last week.
Preview access can move. Production assumptions should not move silently.
FAQ
How should teams choose a default GPT-5.6 tier?
For mixed quality-sensitive workloads, start evals with Terra. For predictable high-volume tasks, test Luna first. Use GPT-5.6 Sol for high-value or complex workloads after it clears evals. Do not choose the default tier because it sounds safest.
When should traffic escalate from Luna to Terra or Sol?
Escalate when confidence drops, schema validation fails, tool calls break, user value is high, policy risk appears, or the workload has already shown that the lower tier misses the threshold.
What fallback should run if preview access changes?
Use the last approved production model for that workload. Do not automatically fall from Sol to Terra or Terra to Luna unless that tier already passed the same gate.
Which metrics prove a tier is production-ready?
Cost per successful task, p95 latency, cache hit rate, schema validity, tool accuracy, retry rate, escalation rate, human review rate, and rollback behavior. Benchmarks are context. These are production signals.
Conclusion
GPT-5.6 Sol is not the default answer. It is the tier I would reserve for tasks where the failure cost justifies it. Terra is the likely middle lane. Luna is where predictable volume should be tested first.
Route by workload value. Set eval gates. Watch cache behavior. Keep fallback boring. That is where my data ends.
Previous posts: