GPT-5.5 API提供状況:チームが今すべき準備
GPT-5.5が発表されましたが、APIアクセスはまだ完全には利用できません。チームが今すぐ計画できることと、まだ確認が必要なことを解説します。

先週の金曜日はCodexのワークフローをGPT-5.5に切り替える作業に費やし、月曜日は2人のクライアントに対してこのロールアウトの判断がローンチの見出しが示すよりもずっと複雑だと説明することに費やした。WaveSpeedAIでは「移行すべきか?」という文書に私の名前が多く登場する。私はDora——チームにモデルの切り替えサインオフを2週間待たせる人間だ。APIは稼働している。そこまでは大半の報道が正しい。そして止まる。私が書きたいのはローンチから10日後のことだ——「利用可能」が「実際に統合済み」に変わるまでの間、そして私が関わるほとんどのチームがつまずいている場所について。
これはプランニングノートであり、チュートリアルではない。curlのサンプルを求めてここに来たなら、公式ドキュメントの方が私より的確に説明している。
GPT-5.5が現在利用可能な場所
ChatGPTとCodexのロールアウト状況
GPT-5.5は2026年4月23日にChatGPTとCodex内のPlus、Pro、Business、Enterpriseユーザー向けに公開され、GPT-5.5 ProはPro、Business、Enterpriseティアに限定された。Codexでは特に、このモデルは400Kコンテキストウィンドウと、コスト2.5倍で1.5倍高速なFastモードを備えて出荷されている——詳細はOpenAIのGPT-5.5ローンチ発表に明確に記載されている。ローンチ初日はコンシューマー向けサーフェスのみをカバーしていた。この点を強調したいのは、先週見たチケットの半数がAPIの同時提供を当初から前提としていたからだ。
OpenAIがAPIの利用可能性について述べていること
初期の報道サイクルが見逃した部分:APIアクセスは1日後、2026年4月24日に開始された。gpt-5.5とgpt-5.5-proはいずれもResponsesおよびChat Completions APIで公開されており、OpenAI自身のGPT-5.5モデルドキュメントで確認されている。APIサーフェスのコンテキストウィンドウは1Mトークンであり、Codexの400K上限とは異なる。2つのサーフェス、2つの制限——混同しやすく、エンジニアより先に書き留めておく価値がある。だから問題はもはや「チームがいつ使えるか」ではない。「使うべきか、そして最初に何を確認するか」だ。
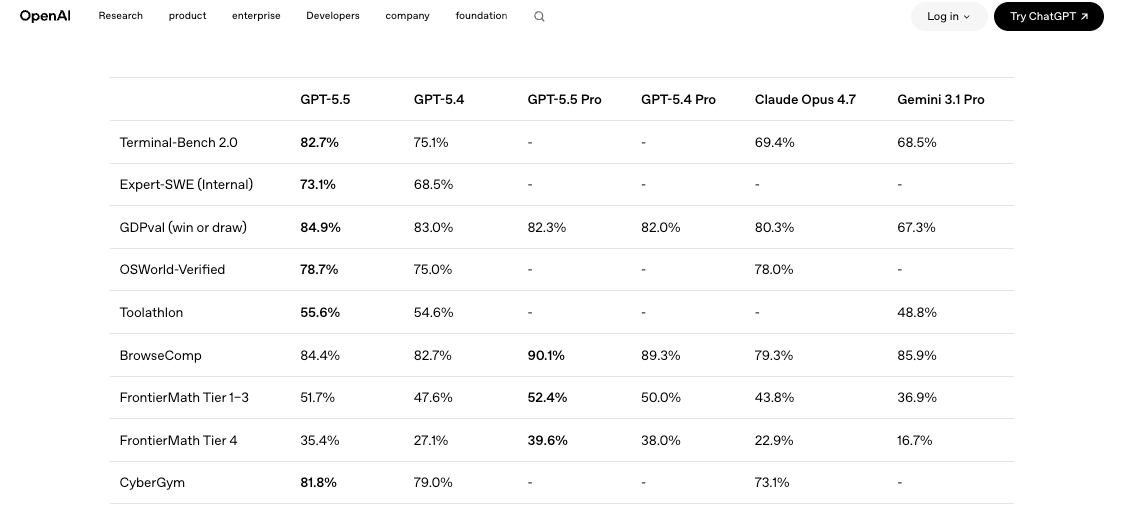
API統合前にチームが安全に計画できること
評価基準と移行準備
私は当日移行を推奨しない。まずロックダウンしておくべきことを挙げる。
現在のモデルに対して小さな評価ハーネスを構築すること。実際のワークロードから代表的なプロンプトを5〜10個選び、本当に重要な次元でスコアリングする:正確性、トークンコスト、レイテンシ、リトライ率。GPT-5.4とGPT-5.5を並列で実行し、同じプロンプト、同じtemperature設定、同じツール定義で比較する。LLM Statsで公開された比較などの独立したベンチマークでは、GPT-5.5が共有ベンチマーク10項目中9項目で向上しているが、SWE-Bench Proでの勝利は僅差にとどまっている。翻訳:アップグレードは本物だが、一様に優れているわけではない。ワークロードが決める。
フォールバックパスは今すぐ決めておくこと——最初の429エラーが来てからではなく。新しいモデルのリリースは歴史的に、最初の30日間はレート制限が厳しくなる傾向がある。プロダクションリクエストを1つ切り替える前に、GPT-5.4をフォールバックとして組み込んでおく。過去にこのステップを省いた2チームが、ローンチ当日のトラフィックスパイク中にその代償を払うのを目の当たりにした。
調達、セキュリティ、エンジニアリングへの質問
今週私が答えなければならなかったいくつかの問いを挙げる:
- 価格は2倍になった。標準レートは入力1Mトークンあたり5ドル、出力1Mトークンあたり30ドルで、OpenAIの公式価格ページに記載されている。Proは30ドル / 180ドル。Codexワークロードではトークン効率の主張がこれを部分的に相殺するが、他のほとんどのワークロードでは請求額が大幅に増加すると見込んでおくこと。
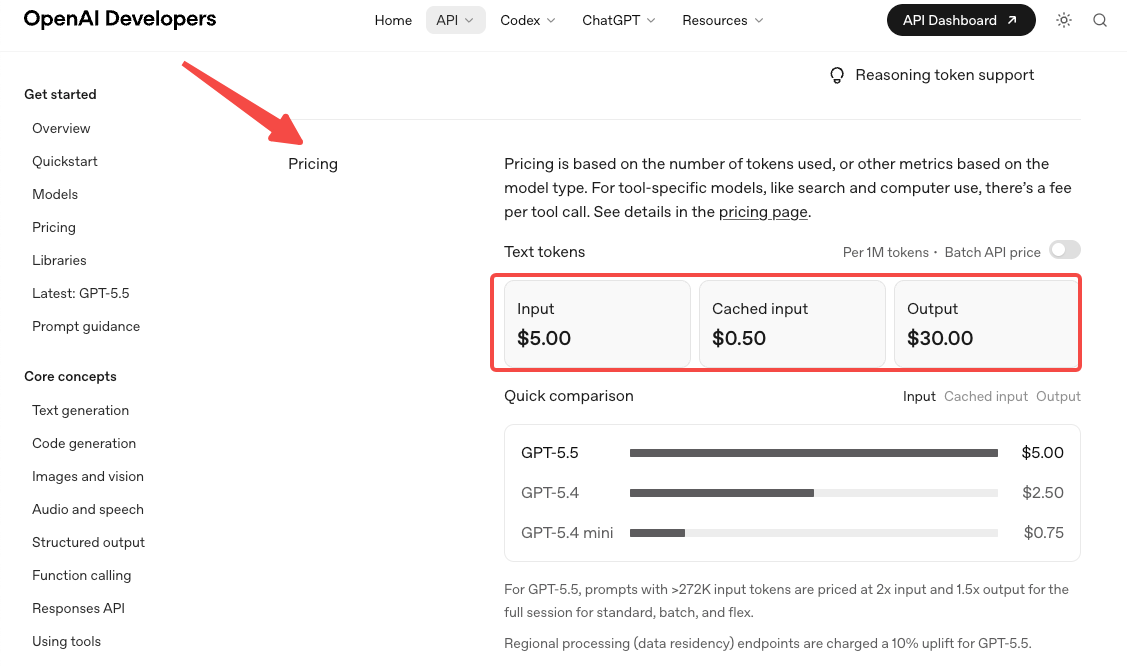
- 長コンテキストの価格は272Kで変わる。この閾値を超えると、セッション全体で入力が2倍、出力が1.5倍になる。ワークフローが定期的に272Kトークンを超える場合、コストを2回モデル化すること——閾値以下と以上で。これは、GPT-5.4のティア構造に基づいて設計し、新しいモデルがそれを引き継ぐと仮定していたチームに効いてくる。
- セキュリティチームはシステムカードを読む必要がある。GPT-5.5はより厳格なサイバー分類器を搭載しており、GPT-5.5システムカードに記載されている。OpenAIが調整を行う間、一部の正当なワークロードが初期段階でブロックされる可能性がある。セキュリティツーリング、コード分析パイプライン、またはレッドチームワークフローをAPIで実行している人には必ず伝えておくべきだ。
プロダクション利用前にまだ確認が必要なこと
モデルID、レート制限、価格設定、ツールサポート
この順序で確認することを推奨する:
1.モデルIDとスナップショット。エイリアスではなくスナップショットにロックすること。エイリアスは変わるが、スナップショットは変わらない。クライアントに何かをハードコーディングする前に、GPT-5.5モデルページで利用可能なリストを確認すること。
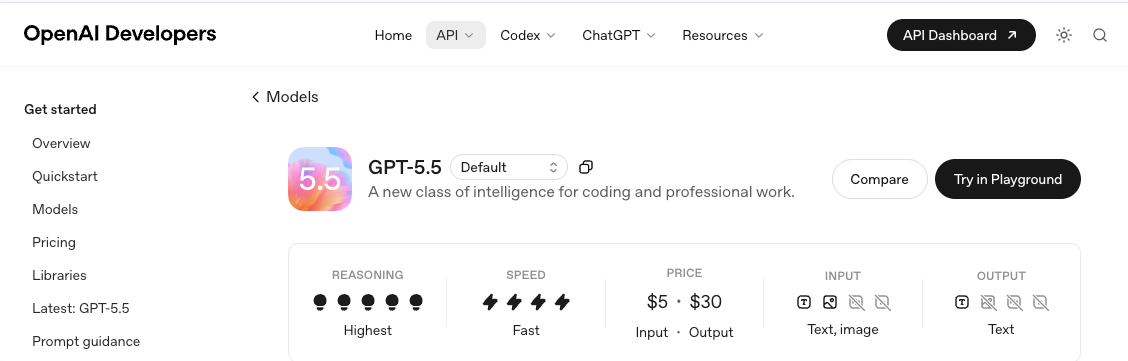
2.ティアのレート制限。OpenAIのティアシステムは支出に基づいて自動的に昇格するが、ローンチ当日の制限は現在GPT-5.4が享受しているものより厳しい場合がある。OpenAIのレート制限ドキュメントを出発点とし、現在のティアのヘッドルームを前提とする前に、合成バーストテストを実行する価値がある。
3.ツールと構造化出力の動作。関数呼び出し、ウェブ検索、構造化出力はすべて機能するが、正確なスキーマとreasoningモードのインタラクションは実際のツール定義に対してスモークテストが必要だ。reasoningのeffort設定がリトライ動作を変える場合があり、それはプロダクショントラフィックにヒットするまで表れないケースを見てきた。
スループットとエンタープライズロールアウトの詳細
本格的な量を処理している人向けに:BatchとFlexは標準レートの半額、Priorityは2.5倍で実行される。翻訳:非同期を許容できるワークロードなら、GPT-5.5のBatchは標準のGPT-5.4と同じトークン単価になる。これがこのリリースに隠されている本当のアービトラージであり、私が話したほぼ誰もまだ織り込んでいない。apidogのGPT-5.5価格内訳が実際の計算例をここより詳しく解説している。
直接プロバイダー計画とプラットフォームベースの準備
私はモデルアクセスを集約するプラットフォームで働いているので、バイアスを明示しておく。しかし構造的な議論は、どのプラットフォームを使っていても同じだ:単一のプロバイダーが初日に2倍の価格のモデルをリリースするとき、ルーティングロジックの必要性は高まる、弱まらない。
直接プロバイダー統合はこうなる:クライアントを書き直し、プロンプトを再テストし、コストモデルをやり直し、プロバイダーごとに繰り返す。マルチモデルプラットフォーム——WaveSpeedAIを含め、他のプラットフォームも——は設定変更でモデルを切り替えられる。トレードオフは、自分とソースの間に層を追加することだ。毎日リリースする高頻度チームにとって、その層は通常抽象化の価値がある。低ボリュームで1つのワークロードに1つのモデルを使うチームにとっては、そうではない。
いずれにせよルーティング設定は計画しておくべきだ。プレミアムクエリはGPT-5.5へ、ルーティンなトラフィックはGPT-5.4または他のフロンティアモデルへ——このパターンだけで、どのプロバイダーを中心に置いても、シングルモデルのデフォルトに対して請求額を40〜60%削減できる傾向がある。
FAQ
GPT-5.5はすでにAPIでローンチされているか?
はい、2026年4月24日以降。4月23日のローンチはChatGPTとCodexのみをカバーしており、APIはその1日後に続いた。gpt-5.5とgpt-5.5-proはいずれも、1Mトークンのコンテキストウィンドウを持つResponsesおよびChat Completionsエンドポイントでアクセス可能だ。
統合作業を始める前にチームが確認すべきことは?
実際のトークンミックスにおける価格への影響、現在のティアのレート制限上限、GPT-5.4へのフォールバックの組み込みとテスト、そして実際のワークロードで2つのモデルを比較する短い評価ハーネス。エイリアスではなくスナップショットIDにロックすること。
GPT-5.4を使い続けるのと待つのとどちらが良いか?
ワークロード次第。エージェント的なコーディングやコンピューター使用タスクでは、TechCrunchのローンチ報道に記載されているように、GPT-5.5は顕著な向上を示している。GPT-5.4がすでに品質基準を満たしているワークロードでは、測定可能な向上なしに2倍のトークン単価を正当化するのは難しい。
迅速なAPIロールアウトに向けてチームはどう準備すべきか?
今すぐ評価ハーネスを構築し、まだ行っていなければ抽象化層を通じてルーティングし、レート制限は緩むより前に厳しくなると想定すること。大きなクレジット残高を前払いしないこと——この世代の価格設定はまだ動いている。
価格が2倍になると請求額も2倍になるのか?
いいえ、ただしそれに近い。Codexワークロードでのトークン効率の向上により、実際の請求額は2倍未満に収まる。他のワークロードでは、定価に近いと見込むこと。半額のBatch処理が最初に引くべきレバーだ。
まとめ
APIは稼働している。価格は変わった。レート制限はまだ落ち着いていない。だからといって急ぐべきだという意味ではない。意味するのは、ほとんどのチームが期待していた計画期間が予想より早く閉じ、今の仕事は待つことではなく検証だということだ。
私自身、今後2週間で移行を進める。GPT-5.5がその後もデフォルトのルーティングに残るかどうか——まだわからない。それが評価の目的だ。
続報を待て。




