動画フェイススワップの仕組みとAPIガイド
動画フェイススワップの内部動作の仕組みと、APIを通じた呼び出し方を解説します。全体的なパイプライン、入力要件、よくある失敗パターンについて説明します。

こんにちは、Doraです。正直に言うと — 初めてビデオ顔交換APIを呼び出したとき、ほぼ正しく見えるレスポンスが返ってきました。顔はそこにありました。タイミングが0.5秒ずれていました。ライティングのせいで被写体が内側からほんのり光って見えました。まるで割引価格のゴーストのように。
それがビデオ顔交換技術の本質です。外から見ると単純そうに見えます — 顔Aを体Bに入れ替える、 それだけ — しかしデモクリップを超えてリアルなものを構築しようとした瞬間、実際にどれだけ多くの動く部品が動いているかに気づきます。それらの部品を理解することが、洗練されて見えるアウトプットと、ユーザーをうんざりさせるアウトプットの差になります。
このガイドでは、ビデオ顔交換が実際にどのように機能するか、さまざまなアプローチ、APIが何か役に立つことをする前に何が必要か、そして最終的に必ず遭遇する障害モードの対処法について解説します。
ビデオ顔交換が実際に行うこと
多くの解説がこの重要な部分をスキップしているので、明確に分解します。
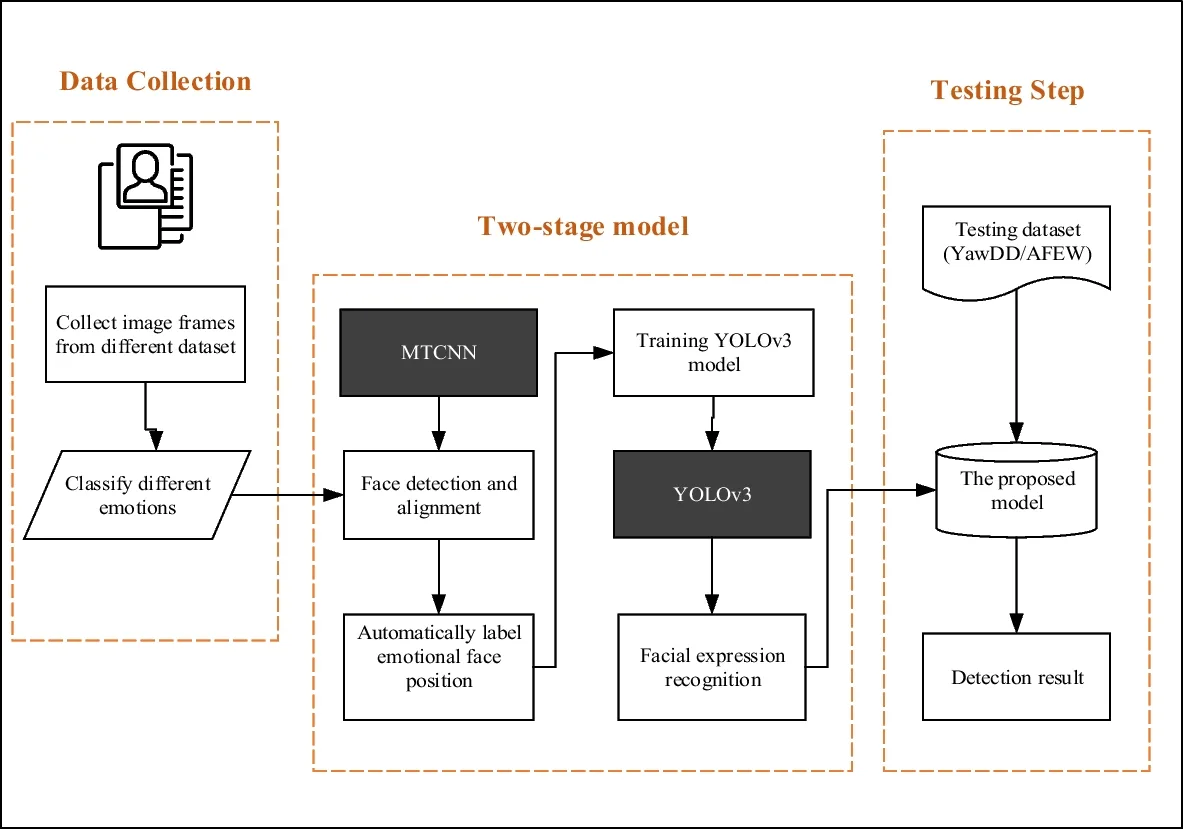
ビデオ顔交換はフィルターではありません。 映像に重ねたマスクでもありません。かなり深いレベルで行っていることは — ビデオの各フレームで顔を検出し、そのジオメトリをマッピングし、ソース顔のアイデンティティを抽出し、ターゲットの動き、ライティング、表情を保持しながらターゲットの顔の構造にソースのアイデンティティをブレンドすることです。
これは順番に起こる3つの異なる問題です。
検出 → アライメント → ブレンドのパイプライン
検出はモデルがフレーム内の顔を見つける場所です。簡単そうに聞こえます。そうではありません。部分的に遮られた顔、急な角度で向いた顔、素早く動いている顔はすべて検出の失敗を引き起こします。ほとんどの本番システムはマルチタスクカスケード畳み込みネットワークの変形を使用します — 基礎的なMTCNNアプローチについてはこの顔検出ディープラーニングガイドで読むことができます — ただし、より最近のアーキテクチャはそれらの初期ベンチマークから大幅に改善されています。
アライメントは多くの人が考えないステップですが、本当に重要です。顔が検出されると、モデルは顔のランドマーク — 目、鼻の先端、口の角 — を特定し、それらを使って顔を正規化された位置とスケールに変換します。これがないと、スワップは誰かが少し間違った角度で顔を付けて、誰も気づかないことを祈っているように見えます。必ず気づかれます。
ブレンドは実際のアイデンティティ転送が起こる場所です。モデルはソース顔のアイデンティティ特徴を取り、ターゲット顔のジオメトリに投影し、結果をフレームに合成します。最新のアプローチはこれにGAN(生成的敵対ネットワーク)を使用します — ブレンドした顔を生成するジェネレーターとリアリズムを評価するディスクリミネーター — だからこそGANベースのディープフェイク生成がどのように機能するかを理解することは、アウトプットのデバッグを始める前の有用なコンテキストとなります。
アウトプット品質が実際に意味すること
早い段階で私を混乱させたことがあります: 顔交換アウトプットの「品質」は一つの数字ではありません。 少なくとも3つの別々のものです。
アイデンティティの保持 — アウトプットは実際にソース顔に見えるか、それとも両方のぼやけた平均に過ぎないか?
時間的一貫性 — 顔はフレーム全体で同じように見えるか、それとも微妙にちらつくか?
フォトリアリズム — 結果はシーンに属しているように見えるか、それとも合成されているように見えるか?
優れたアイデンティティ保持と悪い時間的一貫性を持つことができます。貧弱なアイデンティティ転送で美しいフォトリアリズムを持つことができます。ほとんどのAPIはこれらの間でトレードオフする設定や品質ティアを提供しています。ユースケースでどれが重要かを知ることで、多くの混乱を避けることができます。
ビデオ顔交換アプローチの種類
すべてのビデオ顔交換モデルが同じ方法で機能するわけではありません。同様のアーキテクチャの違いがSeedance 2.0のような最新のAIビデオ生成モデル全体に存在し、アプローチによって時間的一貫性とモーションモデリングの処理が大きく異なります。ツールやAPIを選ぶ前に理解すべき2つの重要な軸があります。
フレームごとモデルと時間認識モデル
フレームごとモデルはビデオの各フレームを独立して扱います。一般的に高速でシンプルに実装できますが、ビデオは関連する画像のシーケンスであるという事実を考慮しません。結果として: フレーム間の微妙なちらつき、特に顔の縁や低光量条件で発生します。
時間認識モデルは前後に何が来るかを知りながらフレームを処理します — 本質的にモーションを理解し、クリップ全体で一貫性を維持します。同様のトレードオフが主要なAIビデオモデルの比較に見られ、安定性とモーションリアリズムが主要な差別化要因です — 本質的にモーションを理解し、クリップ全体で一貫性を維持します。アウトプットはよりスムーズで安定していますが、これらのモデルはより重く遅いです。 数秒以上の長さや近距離での視聴を意図したものには、時間認識モデルはレイテンシコストに値します。
私の正直な経験: プロトタイピングやサムネイル生成ならフレームごとで十分です。フルサイズの画面で視聴するものを構築しているなら、ちらつきを後悔することになります。
単一顔対複数顔
単一顔モデルはよりシンプルで、特定のタスクに対して一般的に高品質です。ユースケースがフレーム内の明確に見える1つの顔を含む場合 — ほとんどの本番シナリオをカバーします — これが正しい出発点です。
複数顔モデルは1つのフレームで複数の顔を検出してスワップできます。アンサンブルショット、グループ映像、または入力ビデオを完全にコントロールできないシナリオに役立ちます。トレードオフは計算コストが高く、誤った顔割り当てが起きやすいことです — つまり、モデルが間違った顔を間違った体にスワップします。4人のクリップを送って意図せずシュールなものが返ってくる前に知っておく価値があります。
APIを呼び出す前に: 必要なもの
ここがほとんどの人が時間を無駄にする場所です。APIが難しいからではなく、入力要件がドキュメントで通常示されているよりも具体的だからです。
入力要件(フォーマット、解像度、クリップ長)
ほとんどのビデオ顔交換APIが期待するもの:
- ビデオフォーマット: H.264エンコーディングのMP4が最も安全なデフォルトです。一部のAPIはWebMやMOVも受け付けますが、H.264/MP4が最も広くサポートされています。
- 解像度: 720pは許容可能なスワップ品質の実用的な最小値です。1080pはモデルにより多くの顔の詳細を提供します。480p以下では、ほとんどのモデルが目に見えるアーティファクトを生成し始めます — 顔の領域に十分なピクセルがなく、クリーンなブレンドができません。
- クリップ長: 多くのAPIは同期処理を30〜60秒に制限しています。より長いクリップにはWebhookコールバック付きの非同期ジョブ送信が必要です。アーキテクチャを設計する前に、クリップがどちらのカテゴリに属するかを把握してください。
- ソース画像: スワップする顔には、明るく照らされた正面の写真1枚で通常十分です。一部のモデルはビデオソースも受け付けますが、均一なライティングの明確な静止画像は通常より一貫したアイデンティティ転送を生成します。
顔の角度とライティングの制約
ここで現実的なチェックを: モデルは魔法ではありません。
顔の角度: ほとんどのモデルは正面からの視点から約30〜35度の傾きまでうまく機能します。それを超えると、ランドマークの精度が低下し始め、アライメントエラーに連鎖し、ブレンドアーティファクトが生成されます。プロフィール(横顔)は一般的にサポートされていないか、使用できない出力を生成します。ソース映像に被写体がカメラからよく目を離す場合は、品質の期待値を調整してください。
ライティング: 強い方向性ライティング — サイドライトの顔、深い目の影を作る強い頭上からの光 — はブレンドステップが説得力を持って処理するのが難しいです。モデルはソース顔のライティングとターゲットフレームのライティングを調和させる必要があり、それらが一致しないほど継ぎ目が見えやすくなります。
暗い映像を避けろと言っているわけではありません。ソース素材を生成していてコントロールできるなら、均一なライティングがアウトプットを意味のある形で改善するということです。
APIワークフロー ステップバイステップ
実践的に進めましょう。ビデオ顔交換APIコールの典型的なフローです。
認証
ほぼすべての本番APIはベアラートークン認証を使用します。登録時にAPIキーを受け取り、ヘッダーとして渡します:
Authorization: Bearer YOUR_API_KEYこれは標準的な慣行であり、OWASP RESTセキュリティチートシートなどのリソースからのセキュリティガイドラインと一致しています。最初にやっておく価値があることがいくつかあります:
- APIキーは環境変数として保存し、コードベースにハードコードしない
- キーローテーションを設定する — ほとんどのAPIはアカウントアクセスを失わずにキーを再生成できます
- 利用可能であれば、統合が実際に必要な権限のみを持つスコープ付きキーを使用する
リクエストの送信
典型的なリクエストボディはこのようなものです:
{
"source_image_url": "https://your-storage.com/source-face.jpg",
"target_video_url": "https://your-storage.com/target-video.mp4",
"output_format": "mp4",
"quality": "high"
}一部のAPIはmultipart form-dataを介してバイナリファイルを直接受け付けます。他のAPIは公開アクセス可能なファイルを指すURLのみを受け付けます。APIドキュメントをこの点で注意深く確認してください — ファイルURLにアクセスできなかったためにAPIが200を返しても何も処理しない、というサイレント失敗の一般的な原因です。
より長いクリップでは、通常アウトプットを直接返す代わりにジョブIDが返ってきます:
{
"job_id": "fswap_a3b92f",
"status": "processing",
"estimated_time_seconds": 45
}アウトプットの処理
ジョブステータスエンドポイントをポーリングするか、処理が完了したときに結果を受け取るWebhookを設定します。レスポンスには処理済みビデオのダウンロードURLが含まれます。これらのURLは通常時間制限があります — 有効期限内(通常はプロバイダーによって1〜24時間)にアウトプットをダウンロードして自分のストレージに保存してください。
ステータスが完了だからといってアウトプットが完璧だと思わないでください。常に数フレームをスポットチェックしてください。ステータス完了はパイプラインがクラッシュなく実行されたことを意味します。スワップが良く見えることを意味しません。
本番システムでは、これらの非同期パターン — 適切なエラー処理、リトライロジック、Webhook検証 — を中心に堅固なREST API統合を構築することで、後の痛みを伴うデバッグセッションを節約できます。

一般的な障害モードと修正方法
ここが本題です。私はこれら3つすべてに遭遇しました。
モーションのグリッチ
見た目: スワップされた顔がフレーム間でジッターまたは「ポップ」する。これはクリエイターがAI生成ビデオのちらつきとジッターを修正する方法に関するガイドで議論されている問題と非常に似ています。
なぜ起こるか: 時間的スムージングなしのフレームごと処理。各フレームが独立して解決されるため、ランドマーク検出のわずかな変化が不一致を生み出します。
修正方法: 利用可能であれば時間認識モデルに切り替える。フレームごとAPIに縛られている場合、一部のプロバイダーはポスト処理安定化パスを提供しています — オプションでそれを探してください。あるいは、APIに送信する前に入力ビデオをモーション安定化で前処理することも役立ちます。
アイデンティティのドリフト
見た目: アウトプットの顔が徐々にソースに似なくなり、ソースとターゲットのブレンド — または単なる平均的な誰か — に見え始める。
なぜ起こるか: 通常ソース画像の品質の問題。ソース顔の写真が低解像度、照明が悪い、または正面でない角度で撮られている場合、モデルは信頼できるアイデンティティ特徴を抽出できません。ギャップを推測できるもので埋め、多くの場合ターゲット顔の方向に向かっていきます。
修正方法: より高品質なソース画像を使用する。正面向き、均一な照明、顔領域で少なくとも512×512px。この一つの変更だけで、私の経験ではおよそ80%のケースでアイデンティティドリフトが解決されます。
ライティングの不一致
見た目: スワップされた顔が「貼り付けられた」ように見える — 顔のライティング方向や色温度が周囲のシーンと一致しない。
なぜ起こるか: ブレンドモデルはライティングを調和させようとしますが、できることには限界があります。ソース画像のライティングとターゲットビデオの大きな違いは合成ステップに負荷をかけます。
修正方法:
- ソース画像をコントロールできる場合、ターゲット映像と似たライティング条件で撮影する
- 一部のAPIはパラメーターとして明示的なライティング正規化を提供しています — オンにする
- 深刻な不一致の場合、アウトプットをカラーグレーディングパスでポスト処理することで、顔をシーンに説得力を持ってブレンドするのに役立ちます
では、結論は何でしょうか?
ビデオ顔交換は、成功するために何が必要かを理解するときに本当に強力な技術です。品質の問題のほとんどは謎ではありません — それらは入力品質、ユースケースのためのモデル選択、およびパイプラインが何をできて何をできないかについての現実的な期待に帰結します。それらを正しく理解することで、デモでは良く見えたのに本番では崩れたアウトプットのデバッグに費やす時間を大幅に削減できます。





