Grok 4.5 vs Grok 4.3: Prepare API Tests
Prepare a safe Grok 4.5 vs Grok 4.3 API test plan for tool calling, context, latency, cost, hallucination, fallback, and eval coverage.

Dora here. I would not run a real Grok 4.5 vs Grok 4.3 comparison yet.
Checked on July 2, 2026: xAI’s public model docs list grok-4.3, not a public Grok 4.5 API model. So this is a pre-launch test plan. If you own a production AI workflow, the work now is simple: freeze the Grok 4.3 baseline, prepare the eval set, and wait for official Grok 4.5 API fields before making claims.
Comparison Status: What Can and Cannot Be Compared Yet
Grok 4.3 as the confirmed baseline
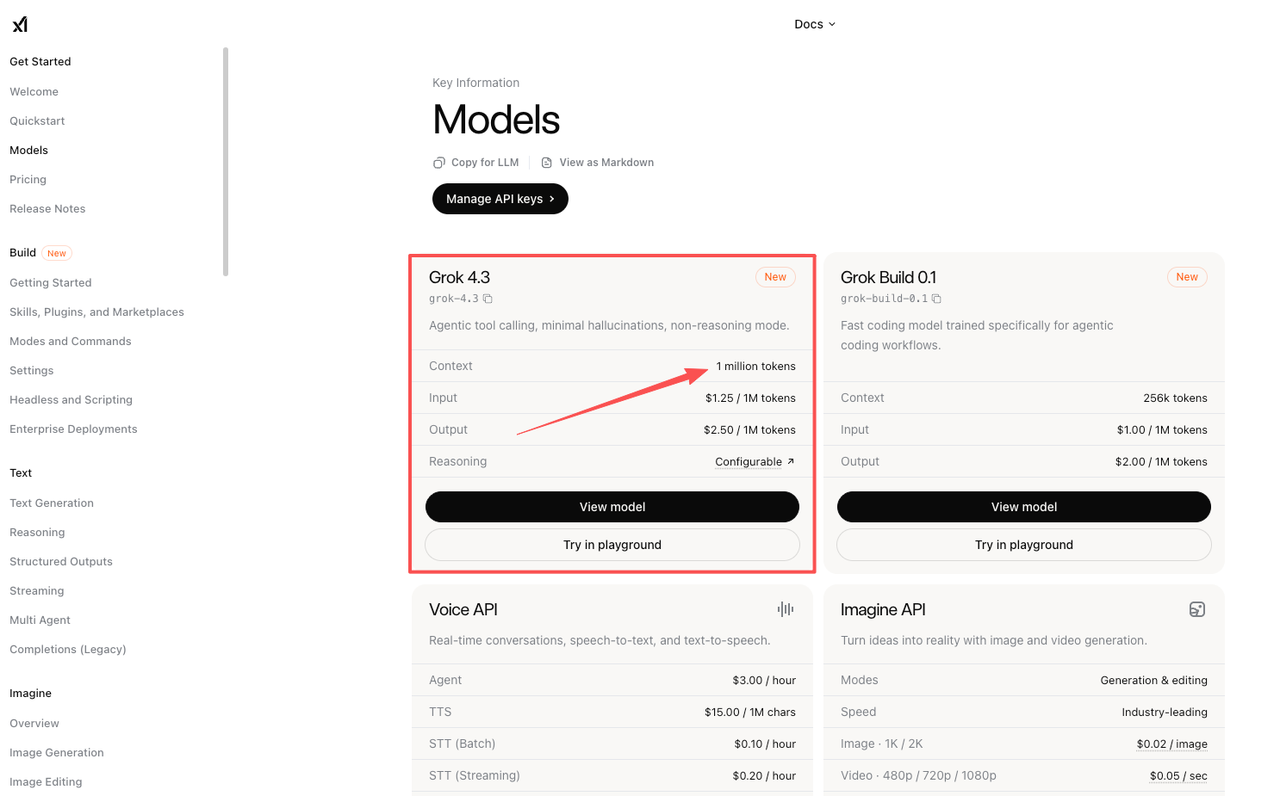
Grok 4.3 is the confirmed API baseline. The xAI models page lists grok-4.3 with a 1M token context window, configurable reasoning, and current API pricing. The xAI pricing page shows Grok 4.3 at $1.25 per 1M input tokens and $2.50 per 1M output tokens.
That is enough to build the control group.
The baseline should include:
- tool calling behavior
- structured output reliability
- long-context accuracy
- latency and cost per task
- hallucination and refusal patterns
- regression performance against current production prompts
For structured data tasks, use xAI’s Structured Outputs docs as the reference point. For agentic flows, use the Function Calling docs. That gives you something testable. Not vibes.
Grok 4.5 fields that remain unknown
Grok 4.5 is not a public API target in xAI docs at the time of writing. Media reports say Grok 4.5 is in private beta at Tesla and SpaceX, with claims around internal performance and Cursor-related training data, but those are not official xAI API specifications. Treat them as reporting, not migration input. Business Insider has a useful example of the current claim surface, but it is still not an API contract.
The unknown fields matter:
- model slug
- API availability
- pricing
- context window
- output limits
- reasoning controls
- tool support
- structured output guarantees
- rate limits
- provider availability through OpenRouter or other routers
I paused here. This is exactly where teams usually get sloppy.
What to Test After Grok 4.5 API Launches
Tool calling, structured outputs, long-context behavior
Run the same prompts against Grok 4.3 and Grok 4.5.
For tool calling, test auto, required, none, forced tool selection, and parallel function calls. Do not only test the happy path. Include missing parameters, malformed tool outputs, ambiguous user intent, and tool conflicts.
For structured outputs, test strict JSON schemas, nullable fields, enum-heavy schemas, nested objects, and extraction tasks. A model that sounds better but breaks schema 3% more often is not an upgrade for production AI.
For long context, test your real document lengths. If your product regularly sends 80k tokens, test 80k. If support workflows send 400k tokens, test that. A 1M window does not mean your task remains accurate at 1M.
Latency, cost, output stability, hallucination rate
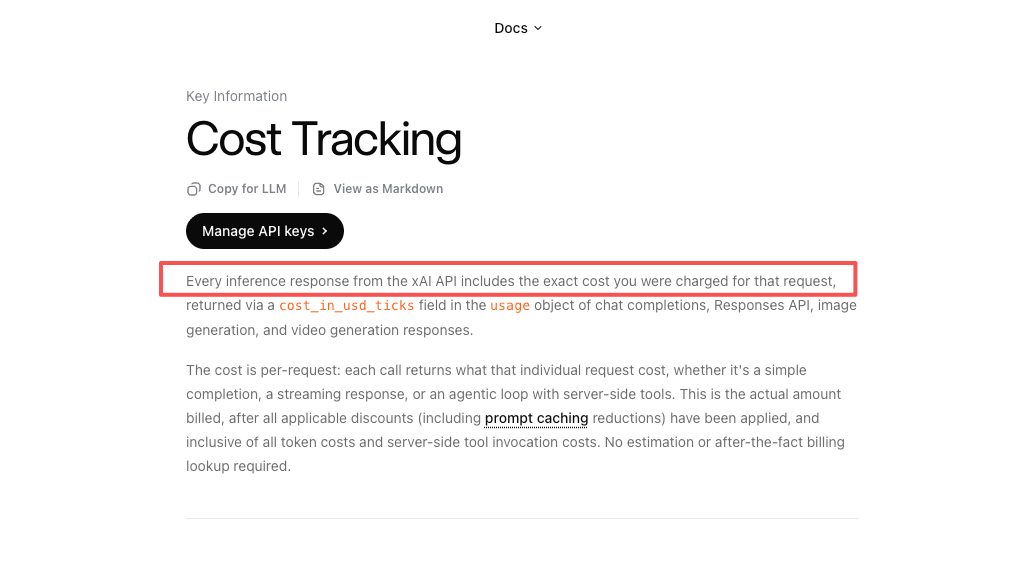
Measure p50, p95, and p99 latency. Track time to first token separately from full completion time.
Use xAI’s cost tracking field, especially cost_in_usd_ticks, to log per-request cost. That matters more than list price once tool calls, retries, and longer outputs enter the system.
Run each eval more than once. Five repeats is the minimum I would trust. Ten is better for high-risk tasks. Output stability matters when the same customer prompt can produce different decisions.
Build a Real Evaluation Set
Production prompts, edge cases, regression tasks
Do not build the eval set from synthetic demo prompts.
Use anonymized production prompts from the last 30 to 90 days. Add edge cases: short prompts, messy prompts, long prompts, multilingual inputs, incomplete context, adversarial instructions, and requests that previously caused support tickets.
If your stack used Grok 4.1 before Grok 4.3, include old Grok 4.1 regression cases too. Model evaluation should catch old failures returning under a new name.
Pass/fail thresholds before migration
Set thresholds before the test starts.
A practical threshold set might look like this:
| Area | Example pass threshold |
|---|---|
| JSON schema validity | 99.5%+ |
| Tool call argument accuracy | 98%+ |
| Critical hallucination rate | Lower than Grok 4.3 |
| p95 latency | No more than 20% worse |
| Cost per successful task | No more than 15% higher |
| Human escalation rate | No increase |
Adjust the numbers for your product. Just write them down first.
Migration and Fallback Plan
Traffic split, rollback rules, provider fallback
Start with shadow traffic. Then move to 1%, 5%, 10%, and 25% live traffic only if the model clears each gate.
Rollback rules should be boring:
- schema failures exceed threshold
- p95 latency crosses the limit
- cost per successful task jumps
- safety or compliance failures appear
- support tickets rise
- fallback rate increases
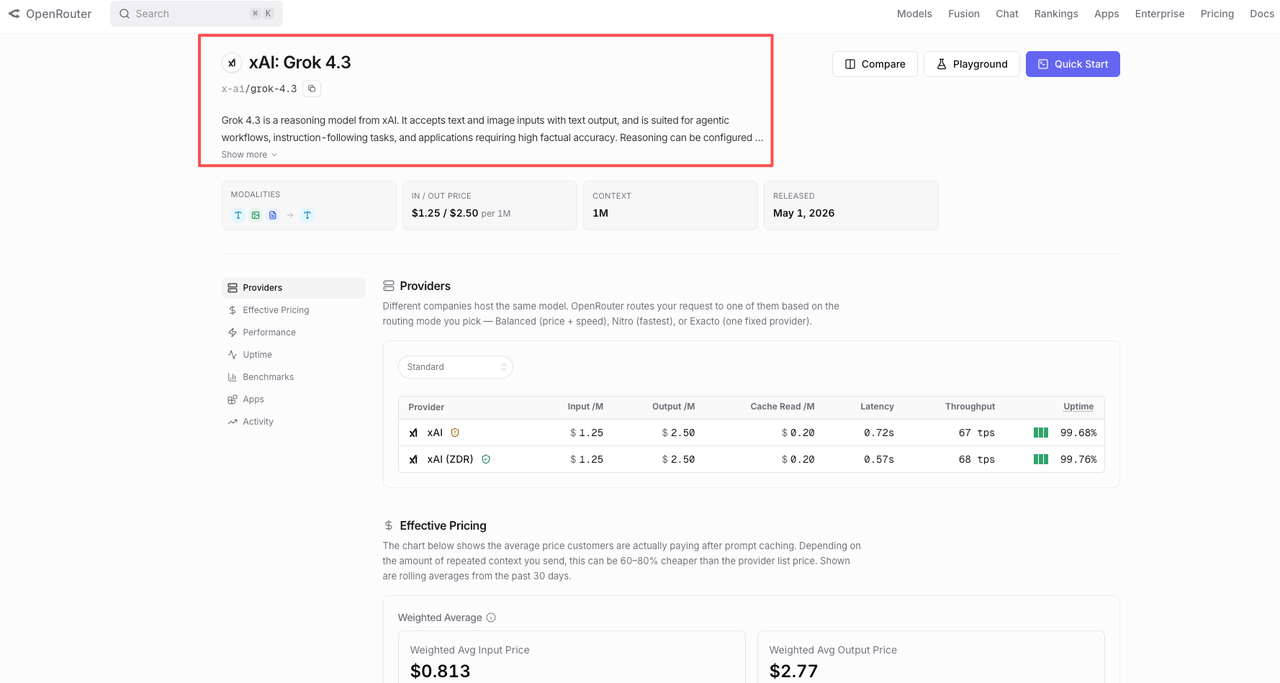
If you use OpenRouter, its Grok 4.3 page is useful for provider routing context, uptime monitoring, and fallback planning. Still, provider fallback changes behavior. Test it as its own system, not as a free safety net.
Logging and cost monitoring during rollout
Log model slug, provider, prompt version, tool calls, retries, latency, token usage, exact cost, schema errors, and final task outcome.
Without this, Grok 4.5 vs Grok 4.3 becomes a meeting debate. With it, the answer is usually obvious.
Limits and Risks
Vendor claims vs workload-specific results
Vendor benchmarks are inputs. Not decisions.
A model can beat another model on public tests and still fail your customer support router, code review assistant, medical intake summarizer, or sales workflow.
Why benchmark wins do not equal production fit
Production fit is narrower.
You care about repeatability, failure shape, cost curve, rollback speed, and how the model behaves on your ugly prompts. That is where model evaluation earns its keep.
FAQ
Can I compare Grok 4.5 and Grok 4.3 today?
Not as an API migration test. You can prepare the Grok 4.5 vs Grok 4.3 framework today, but Grok 4.5 needs public API docs before a fair comparison.
What evals should run before switching models?
Run tool calling, structured outputs, long-context, hallucination, latency, cost, and regression evals. Use production prompts first.
How much traffic should a migration test use?
Start with shadow traffic, then 1% to 5% live traffic. Move higher only after clean logs.
When should a team stay on Grok 4.3?
Stay on Grok 4.3 if Grok 4.5 is more expensive, less stable, slower at p95, weaker on structured outputs, or not meaningfully better on your actual workload.
Conclusion
The useful Grok 4.5 vs Grok 4.3 question is not “which model is smarter?”
It is: can Grok 4.5 clear your production gates better than Grok 4.3, at an acceptable cost, with rollback ready?
Until the API is public, prepare the harness. That is the work. See you.
Previous posts: