Apa Itu SkyReels V4? Model AI Video-Audio Terpadu Pertama yang Dijelaskan
SkyReels V4 adalah AI open-source pertama yang menghasilkan video dan audio secara bersamaan — pada resolusi 1080p/32FPS. Inilah yang bisa dilakukannya, cara kerjanya, dan mengapa hal ini penting.

Halo, saya Dora. Hari itu saya membuat video SkyReels V4 pertama saya. Lima belas detik seekor kucing berjalan melewati gang basah kehujanan saat senja. Videonya bagus — 1080p, gerakan mulus, pencahayaan yang indah. Tapi yang membuat saya terdiam adalah audionya. Suara langkah kaki yang memercik di genangan air. Suara lalu lintas yang sayup-sayup. Gema samar dari dinding gang. Semuanya dihasilkan bersama, tersinkronisasi dengan sempurna, tanpa saya menyentuh satu pun alat pengeditan audio.
Itulah bagian yang terasa berbeda.
Masalah yang Dimiliki Setiap Alat Video AI Sebelum V4
Mengapa generasi video saja selalu terasa tidak lengkap
Sebagian besar alat video AI menghasilkan klip tanpa suara. Runway, Pika, bahkan versi SkyReels sebelumnya — semuanya menghasilkan visual dan berhenti di sana. Anda mendapatkan shot indah 10 detik berupa ombak yang menghantam pantai, tetapi sepenuhnya sunyi. Ombak tidak berderai. Angin tidak bertiup. Tidak ada suara ambien sama sekali.
Ini bukan kelalaian teknis. Menghasilkan audio yang tersinkronisasi bersamaan dengan video memang benar-benar sulit. Audio tidak hanya perlu sesuai dengan adegan secara umum, tetapi juga dengan kejadian visual spesifik — suara langkah kaki saat kaki menyentuh tanah, pintu menutup saat diayunkan, suara yang sinkron dengan gerakan bibir.
Hambatan “tambahkan audio setelah produksi”
Alur kerja standar menjadi: buat video, ekspor, buka editor audio, tambahkan efek suara atau musik secara manual, sinkronkan semuanya dengan tangan, ekspor lagi. Untuk klip 15 detik, ini bisa memakan waktu 20-30 menit.
Saya mencoba ini dengan output Pika bulan lalu. Videonya terlihat profesional. Tapi mencari suara ambien yang tepat, mengatur waktunya agar sesuai dengan petunjuk visual, dan menghindari kesan “jelas ditambahkan belakangan” menghabiskan lebih banyak waktu daripada membuat videonya sendiri. Alur kerja ini terasa rusak — seperti membeli mobil tetapi harus memasang mesinnya secara terpisah.
Apa Sebenarnya SkyReels V4 Itu
Dibuat oleh SkyworkAI (penjelasan silsilah V1/V2/V3)
SkyworkAI merilis SkyReels V1 pada awal 2025 sebagai model teks-ke-video dasar. V2 menyusul dengan arsitektur diffusion forcing yang memungkinkan generasi dengan panjang tak terbatas melalui sekuens autoregresif. V3 diluncurkan pada Januari 2026 dengan pembelajaran in-context multimodal — Anda bisa memberinya gambar referensi, klip audio, atau video yang sudah ada dan model akan menghasilkan kelanjutan yang koheren.

V4, yang diluncurkan pada 25 Februari 2026, mewakili lompatan yang berbeda. Jika V3 menambahkan fitur, V4 merestrukturisasi seluruh arsitektur di sekitar sistem dual-stream yang menghasilkan video dan audio secara bersamaan.
Apa yang sebenarnya dimaksud dengan “model fondasi video-audio terpadu”
Makalah teknis menjelaskan V4 menggunakan Multimodal Diffusion Transformer (MMDiT) dengan dua cabang paralel. Satu cabang mensintesis frame video. Cabang lainnya menghasilkan audio yang selaras secara temporal. Kedua cabang berbagi encoder teks berbasis model bahasa besar multimodal, yang berarti keduanya memproses pemahaman semantik yang sama dari prompt Anda dan menjaga sinkronisasi sepanjang proses generasi.
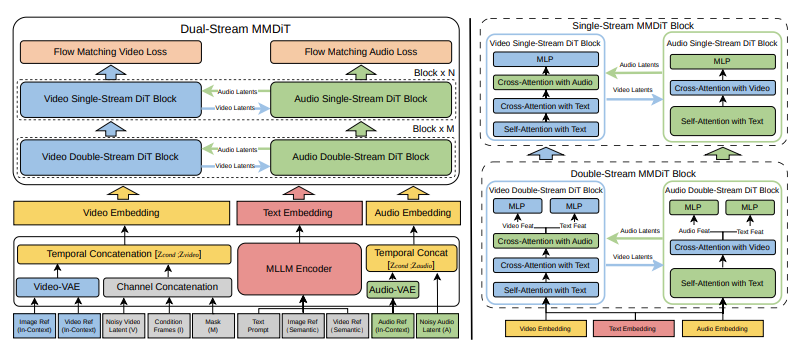
Ini bukan generasi video dengan audio yang ditambahkan belakangan. Ini adalah satu model yang memperlakukan penglihatan dan suara sebagai output yang sama pentingnya, dihasilkan bersama dari pemahaman laten yang sama tentang adegan tersebut.
Dalam praktiknya, ini berarti ketika Anda memberi prompt “seorang wanita berbicara di podium,” model menghasilkan baik visual gerakan bibirnya maupun audio ucapan yang sebenarnya, tersinkronisasi di tingkat frame. Ketika Anda membuat “hujan deras di atap logam,” Anda mendapatkan baik visual hujan yang mengalir ke bawah maupun suara gemuruh logam yang khas — tidak hanya kira-kira sesuai, tetapi dihasilkan sebagai peristiwa audiovisual yang terpadu.
Kemampuan Utama Sekilas
Generasi video + audio bersama dari satu prompt
Generasi dengan satu prompt adalah kemampuan utama. Anda menulis “guntur menggelinding di atas lanskap gurun” dan V4 menghasilkan 15 detik awan yang berkumpul, kilat yang menyambar, dan guntur yang tersinkronisasi menggelegar sesuai dengan waktu visual. Tidak ada langkah generasi audio terpisah. Tidak ada pekerjaan sinkronisasi manual.
Saya menguji ini dengan adegan dialog. Memberi prompt “dua orang bertengkar di kafe yang ramai” dan mendapatkan bukan hanya visual percakapan tetapi juga obrolan latar, suara piring yang beradu, dan suara-suara pembicara yang naik turun sesuai intensitas gestur mereka. Sinkronisasi bibir tidak sempurna — saya melihat beberapa momen di mana waktu sedikit meleset — tetapi lebih baik dari apa pun yang pernah saya sinkronkan secara manual.
Output 1080p / 32FPS / 15 detik
Spesifikasi teknis: hingga resolusi 1080p, 32 frame per detik, durasi maksimum 15 detik. Sebagai perbandingan, sebagian besar alat pesaing mencapai maksimum 720p atau membutuhkan waktu generasi yang jauh lebih lama untuk output HD.
Batas 15 detik lebih penting dari kedengarannya. Sebagian besar konten media sosial berada dalam potongan 10-15 detik. YouTube Shorts dibatasi 60 detik. Instagram Reels 90 detik. Untuk kasus penggunaan itu, 15 detik dengan audio tersinkronisasi lebih berguna daripada 30 detik video sunyi yang membutuhkan pasca-produksi.
Input multi-modal: teks, gambar, video, mask, referensi audio
V4 menerima lima jenis input: prompt teks, gambar referensi, klip video, mask biner untuk inpainting, dan referensi audio. Anda dapat menggabungkannya — unggah gambar orang tertentu, berikan sampel audio suara langkah kaki di atas kerikil, dan beri prompt “berjalan melewati hutan saat fajar.” Model menggunakan ketiga input tersebut untuk memandu generasi.
Saya menguji prompting multi-modal dengan gambar referensi gaya arsitektur tertentu dan klip audio suara ambien jalanan. Video yang dihasilkan mempertahankan detail arsitektur dari gambar sambil melapisi suara ambien dari referensi audio. Tidak sempurna — beberapa elemen audio terasa generik — tetapi kemampuannya bekerja.
Tiga tugas dalam satu: hasilkan, inpaint, edit
Selain generasi, V4 menangani inpainting dan pengeditan melalui channel concatenation. Berikan video dan mask yang menunjukkan wilayah mana yang akan dimodifikasi, dan model menghasilkan ulang hanya area tersebut sambil mempertahankan sisanya. Ini memungkinkan tugas seperti menghapus objek, mengubah latar belakang, atau mengganti elemen tertentu tanpa menghasilkan ulang seluruh klip.
Bagaimana V4 Dibandingkan dengan Versi Sebelumnya
Evolusi V4 vs SkyReels V1/V2/V3
V1 hanya teks-ke-video. V2 menambah panjang melalui diffusion forcing. V3 memperkenalkan input multimodal tetapi masih menghasilkan video tanpa audio native. V4 adalah yang pertama memperlakukan audio sebagai output kelas satu yang dihasilkan bersamaan dengan video.
Siapa yang Harus Memperhatikan SkyReels V4?

Pembuat konten dan sineas
Siapa pun yang memproduksi konten berformat pendek untuk platform sosial langsung mendapat manfaatnya. Kompresi alur kerja — dari prompt hingga klip audiovisual yang selesai — menghilangkan hambatan yang membuat alat video AI terasa seperti menciptakan lebih banyak pekerjaan daripada yang dihemat.
Saya menyaksikan seorang teman sineas menggunakan V4 untuk membuat B-roll untuk sebuah dokumenter. Prompt seperti “time-lapse lampu kota yang menyala saat senja” atau “close-up hujan di kaca jendela” dengan suara ambien yang sesuai. Hasilnya tidak bisa dibedakan dari footage nyata, tetapi cukup baik untuk shot latar belakang, dan siap dalam waktu kurang dari 60 detik masing-masing alih-alih memerlukan pengambilan gambar di lokasi atau lisensi footage stok.
Pengembang yang membangun pipeline video
Jika Anda membangun aplikasi yang menghasilkan atau memanipulasi video, antarmuka terpadu V4 untuk generasi, inpainting, dan pengeditan menyederhanakan tumpukan. Alih-alih merangkai model terpisah untuk generasi video, sintesis audio, dan koreksi sinkronisasi, satu panggilan API menangani seluruh alur.
Arsitektur model didokumentasikan secara rinci, dan SkyworkAI memiliki riwayat membuat versi sebelumnya menjadi open-source, yang mengisyaratkan akses pengembang akan berkembang. Bobot V3 sudah tersedia di Hugging Face dan GitHub.
Status Akses Saat Ini & Apa yang Akan Datang
Per 2 Maret 2026, V4 dalam pratinjau terbatas. Situs resmi menawarkan tier gratis dengan batas generasi harian, tetapi belum ada akses API. Berdasarkan timeline V3 — yang pergi dari rilis makalah ke API publik dalam sekitar dua minggu — saya perkirakan ketersediaan yang lebih luas pada pertengahan Maret.
Makalah teknis mencatat bahwa pekerjaan di masa depan mencakup perpanjangan melampaui 15 detik dan peningkatan kontrol audio yang lebih halus. Keterbatasan tersebut terasa signifikan saat ini, terutama batasan durasi. Tapi untuk masalah spesifik yang diselesaikan V4 — menghasilkan klip audiovisual pendek yang tersinkronisasi tanpa pasca-produksi — ini bekerja lebih baik dari apa pun yang pernah saya uji.
Saya terus menggunakan V4 dalam alur kerja saya sejak uji coba pertama itu. Tidak untuk segalanya — masih ada tugas di mana footage yang difilmkan atau video stok lebih masuk akal. Tapi untuk B-roll cepat, adegan ambien, atau cuplikan media sosial di mana audio tersinkronisasi penting, V4 menghilangkan cukup banyak hambatan sehingga saya kini menjangkaunya terlebih dahulu.
Arsitektur terpadu ini terasa kurang seperti fitur inkremental dan lebih seperti memperbaiki sesuatu yang seharusnya bekerja dengan cara ini sejak awal.
Artikel Terkait

Claude Fable 5 Telah Dirilis: 80,3% di SWE-Bench Pro, Harga 2× Opus 4.8, Gratis Hingga 22 Juni

Cara Memilih API Media AI untuk Aplikasi Codex (2026)

Hunyuan 3D API: Yang Perlu Diketahui para Developer

Hunyuan 3D vs Hyper3D vs Pixal3D

Membangun Aplikasi Video AI dengan Coding Agent
