Ketersediaan API GPT-5.5: Apa yang Perlu Direncanakan Tim
GPT-5.5 telah diumumkan, namun akses API belum sepenuhnya tersedia. Berikut yang dapat direncanakan tim sekarang dan apa yang masih perlu diverifikasi.

Saya menghabiskan Jumat lalu untuk mengarahkan ulang alur kerja Codex ke GPT-5.5, lalu menghabiskan hari Senin menjelaskan kepada dua klien mengapa keputusan peluncuran ini lebih rumit dari yang disarankan judul-judul berita. Nama saya muncul di banyak dokumen “haruskah kita migrasi?” di WaveSpeedAI, jadi saya Dora — orang yang membuat tim menunggu dua minggu sebelum menyetujui pergantian model. API-nya sudah aktif. Itulah bagian yang paling banyak diliput dan berhenti di sana. Yang ingin saya tulis adalah sepuluh hari setelah peluncuran, ketika “tersedia” berubah menjadi “benar-benar terintegrasi,” dan di mana sebagian besar tim yang saya ajak bekerja sama mengalami kendala.
Ini adalah catatan perencanaan, bukan tutorial. Jika Anda datang untuk contoh curl, dokumentasi resmi menangani itu lebih baik dari yang bisa saya lakukan.
Di Mana GPT-5.5 Tersedia Hari Ini
Status peluncuran ChatGPT dan Codex
GPT-5.5 diluncurkan pada 23 April 2026 untuk pengguna Plus, Pro, Business, dan Enterprise di dalam ChatGPT dan Codex, dengan GPT-5.5 Pro dibatasi untuk tingkatan Pro, Business, dan Enterprise. Di Codex khususnya, model ini hadir dengan jendela konteks 400K dan mode Fast yang berjalan 1,5x lebih cepat dengan biaya 2,5x lebih besar — detail yang dipaparkan dengan jelas dalam pengumuman peluncuran resmi GPT-5.5 di OpenAI. Peluncuran hanya mencakup permukaan konsumen pada hari pertama. Saya ingin mencatat ini karena setengah dari tiket yang saya lihat minggu lalu mengasumsikan paritas API sejak awal.
Apa yang OpenAI katakan tentang ketersediaan API
Bagian yang terlewat oleh siklus pers awal: akses API tiba satu hari kemudian, pada 24 April 2026. Baik gpt-5.5 maupun gpt-5.5-pro kini tersedia di Responses dan Chat Completions API, dikonfirmasi dalam dokumentasi model GPT-5.5 milik OpenAI sendiri. Jendela konteks adalah 1M token di permukaan API, berbeda dari batas Codex 400K. Dua permukaan, dua batas — mudah tertukar, dan layak dituliskan sebelum engineer Anda melakukannya. Jadi pertanyaannya bukan lagi “kapan tim saya bisa menggunakannya.” Melainkan “haruskah kita, dan apa yang perlu kita verifikasi terlebih dahulu.”
Apa yang Dapat Direncanakan Tim dengan Aman Sebelum Integrasi API
Kriteria evaluasi dan persiapan migrasi
Saya tidak menyarankan migrasi di hari yang sama. Inilah yang akan saya kunci terlebih dahulu.
Bangun harness evaluasi kecil terhadap model Anda saat ini. Lima hingga sepuluh prompt representatif dari beban kerja nyata Anda, dinilai berdasarkan dimensi yang benar-benar penting bagi Anda: kebenaran, biaya token, latensi, tingkat percobaan ulang. Jalankan GPT-5.4 dan GPT-5.5 secara berdampingan, prompt yang sama, pengaturan suhu yang sama, definisi alat yang sama. Tolok ukur independen seperti perbandingan yang diterbitkan di LLM Stats menunjukkan GPT-5.5 unggul pada 9 dari 10 tolok ukur bersama tetapi hanya meraih kemenangan marjinal pada SWE-Bench Pro. Artinya: peningkatannya nyata, tetapi tidak seragam lebih baik. Beban kerja Anda yang menentukan.
Tentukan jalur fallback Anda sekarang, bukan setelah 429 pertama. Rilis model baru secara historis hadir dengan batas laju yang lebih ketat selama 30 hari pertama. Pastikan GPT-5.4 terpasang sebagai fallback sebelum Anda mengalihkan satu pun permintaan produksi. Saya telah menyaksikan dua tim melewati langkah ini dan membayar mahal saat lonjakan lalu lintas hari peluncuran.
Pertanyaan untuk pengadaan, keamanan, dan rekayasa
Beberapa yang harus saya jawab minggu ini:
- Harga telah berlipat ganda. Tarif standar adalah $5 per 1M token input dan $30 per 1M output, sesuai halaman harga resmi OpenAI. Pro adalah $30 / $180. Klaim efisiensi token sebagian mengimbangi ini pada beban kerja Codex, tetapi pada sebagian besar beban kerja lainnya, perkirakan tagihan Anda naik secara signifikan.
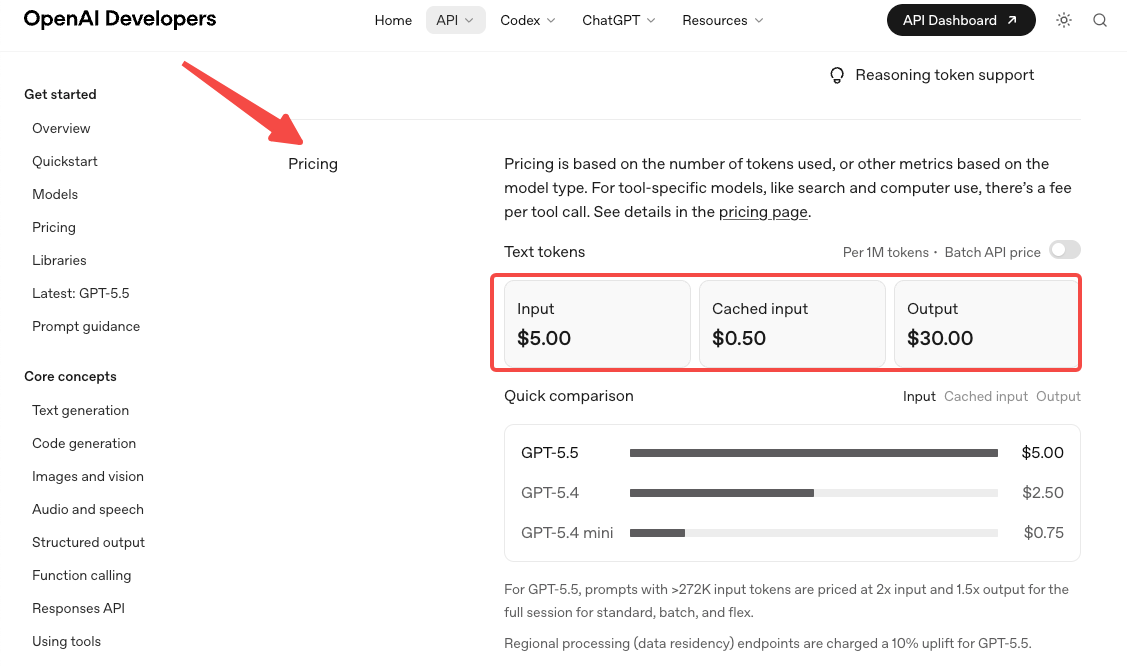
- Harga konteks panjang berubah pada 272K. Di atas ambang itu, input menjadi 2x dan output 1,5x untuk seluruh sesi. Jika alur kerja Anda secara rutin melampaui 272K token, modelkan biaya Anda dua kali — sekali di bawah ambang, sekali di atasnya. Ini menangkap tim yang membangun di sekitar struktur tingkatan GPT-5.4 dan mengasumsikan model baru akan mewarisinya.
- Keamanan perlu membaca kartu sistem. GPT-5.5 hadir dengan pengklasifikasi siber yang lebih ketat, didokumentasikan dalam kartu sistem GPT-5.5. Beberapa beban kerja yang sah akan diblokir awalnya sementara OpenAI menyetel ulang. Layak ditandai kepada siapa pun yang menjalankan alat keamanan, pipeline analisis kode, atau alur kerja red-team melalui API.
Apa yang Masih Perlu Diverifikasi Sebelum Penggunaan Produksi
ID model, batas laju, harga, dan dukungan alat
Saya akan memverifikasi ini dalam urutan ini:
1.ID Model dan snapshot. Kunci ke snapshot, bukan alias. Alias berubah; snapshot tidak. Periksa daftar yang tersedia di halaman model GPT-5.5 sebelum melakukan hard-code apa pun ke dalam klien Anda.
2.Batas laju tingkatan Anda. Sistem tingkatan OpenAI mempromosikan secara otomatis berdasarkan pengeluaran, tetapi batas hari peluncuran bisa lebih ketat dari yang dinikmati GPT-5.4 saat ini. Dokumentasi batas laju OpenAI adalah tempat saya akan memulai, dan layak menjalankan uji burst sintetis terhadap tingkatan Anda saat ini sebelum mengasumsikan headroom-nya ada.
3.Perilaku alat dan output terstruktur. Pemanggilan fungsi, pencarian web, dan output terstruktur semuanya berfungsi, tetapi skema yang tepat dan interaksi mode penalaran memerlukan smoke test terhadap definisi alat aktual Anda. Saya telah melihat pengaturan effort penalaran mengubah perilaku percobaan ulang dengan cara yang tidak muncul sampai Anda mencapai lalu lintas produksi.
Throughput dan detail peluncuran enterprise
Bagi siapa pun yang menjalankan volume serius: Batch dan Flex berjalan dengan setengah tarif standar, Priority dengan 2,5x. Artinya: jika pekerjaan Anda mentolerir async, Batch pada GPT-5.5 biayanya sama per token dengan GPT-5.4 pada standar. Itulah arbitrase nyata yang tersembunyi dalam rilis ini, dan hampir tidak ada yang saya ajak bicara yang telah memperhitungkannya. Rincian harga GPT-5.5 di apidog membahas contoh perhitungan lebih baik dari yang akan saya lakukan di sini.
Perencanaan Penyedia Langsung vs Kesiapan Berbasis Platform
Saya bekerja di platform yang mengagregasi akses model, jadi bias saya sudah jelas. Tetapi argumen strukturalnya sama terlepas dari platform siapa yang Anda gunakan: ketika satu penyedia merilis model dengan harga 2x pada hari pertama, kasus untuk logika perutean menjadi lebih kuat, bukan lebih lemah.
Integrasi penyedia langsung terlihat seperti ini: tulis ulang klien Anda, uji ulang prompt Anda, ulangi model biaya Anda, ulangi per penyedia. Platform multi-model — termasuk WaveSpeedAI, tetapi juga yang lain — memungkinkan Anda menukar model dengan perubahan konfigurasi. Trade-off-nya adalah Anda menambahkan lapisan antara diri Anda dan sumber. Untuk tim frekuensi tinggi yang rilis setiap hari, lapisan itu biasanya sepadan dengan abstraksi. Untuk tim yang menjalankan satu model pada satu beban kerja dengan volume rendah, tidak sepadan.
Saya akan merencanakan pengaturan perutean bagaimanapun juga. Kueri premium ke GPT-5.5, lalu lintas rutin ke GPT-5.4 atau model frontier lainnya — pola ini saja cenderung memotong tagihan 40–60% versus default model tunggal, terlepas dari penyedia mana yang Anda pusatkan.
FAQ
Apakah GPT-5.5 sudah diluncurkan di API?
Ya, mulai 24 April 2026. Peluncuran pada 23 April hanya mencakup ChatGPT dan Codex; API menyusul satu hari kemudian. Baik gpt-5.5 maupun gpt-5.5-pro dapat diakses di endpoint Responses dan Chat Completions dengan jendela konteks 1M token.
Apa yang harus diverifikasi tim sebelum pekerjaan integrasi dimulai?
Dampak harga pada campuran token nyata Anda, batas laju pada tingkatan Anda saat ini, fallback ke GPT-5.4 yang terpasang dan diuji, dan harness evaluasi singkat yang membandingkan kedua model pada beban kerja aktual Anda. Kunci ke ID snapshot, bukan alias.
Apakah worth menunggu daripada menggunakan GPT-5.4?
Tergantung beban kerja. Untuk tugas coding agentik dan penggunaan komputer, GPT-5.5 menunjukkan keunggulan yang berarti, sebagaimana didokumentasikan dalam liputan peluncuran TechCrunch. Untuk beban kerja di mana GPT-5.4 sudah memenuhi standar kualitas Anda, harga per token yang berlipat ganda sulit dibenarkan tanpa peningkatan yang terukur.
Bagaimana tim harus mempersiapkan diri untuk peluncuran API yang cepat?
Bangun harness evaluasi sekarang, rutekan melalui lapisan abstraksi jika Anda belum melakukannya, dan asumsikan batas laju akan mengencang sebelum melonggar. Jangan membayar di muka saldo kredit besar — harga untuk generasi ini masih bergerak.
Apakah harga yang berlipat ganda benar-benar berarti tagihan berlipat ganda?
Tidak, tetapi mendekati itu. Keuntungan efisiensi token pada beban kerja Codex membawa tagihan dunia nyata di bawah 2x. Pada beban kerja lainnya, perkirakan lebih mendekati harga resmi. Pemrosesan Batch dengan tarif setengah adalah tuas yang paling worth ditarik pertama.
Kesimpulan
API-nya sudah aktif. Harganya berubah. Batas lajunya masih menetap. Tidak ada dari itu yang berarti Anda harus terburu-buru. Yang dimaksud adalah bahwa jendela perencanaan yang diharapkan sebagian besar tim tertutup lebih cepat dari yang diperkirakan, dan pekerjaan sekarang adalah verifikasi daripada menunggu.
Saya menjalankan migrasi sendiri selama dua minggu ke depan. Apakah GPT-5.5 akan tetap di perutean default saya setelah itu — saya belum tahu. Itulah gunanya evaluasi.
Selanjutnya akan menyusul.
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8

API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi

Harga GPT-5.4 Mini: Biaya Input, Cache & Output

API MAI-Image-2.5: Yang Perlu Diketahui Para Developer
