Claude Mythos vs Claude Opus 4.6: Apa yang Terungkap dari Bocoran untuk Para Developer
Claude Mythos vs Opus 4.6: apa yang disarankan bocoran tentang kesenjangan kemampuan, dan apakah developer harus menunggu atau membangun sekarang.

Saat sedang di tengah sprint mengerjakan integrasi Claude Code minggu lalu, kebocoran Mythos muncul di feed saya. Tiga pesan Slack dalam sepuluh menit, semua variasi dari pertanyaan yang sama: “Haruskah kita hentikan build-nya?” Ini adalah Dora si penggemar AI, yang telah memantau cerita ini dengan saksama sejak saat itu — dan menurut saya jawabannya lebih bernuansa dari yang digembar-gemborkan.
Tersedia di WaveSpeedAI — harga per-token transparan, endpoint kompatibel OpenAI. Claude Opus 4.6 API → · Claude Opus 4.7 API → · Buka Playground →
Izinkan saya menguraikan apa yang sebenarnya dikatakan kebocoran itu, apa yang saat ini diberikan oleh Opus 4.6, dan bagaimana mengambil keputusan nyata soal timing.
Dasar: Apa yang Saat Ini Diberikan Claude Opus 4.6 untuk Developer
Sebelum masuk ke spekulasi Mythos, mari kita jangkar pada apa yang benar-benar tersedia dan terdokumentasi hari ini.
Performa Coding dan Tugas Agentik
Claude Opus 4.6 mencapai 65,4% pada Terminal-Bench 2.0 dan 72,7% pada OSWorld, menjadikannya model publik terkuat Anthropic untuk tugas coding dan penggunaan komputer. Angka Terminal-Bench itu bukan sekadar trofi benchmark — ini mewakili kemampuan agentik nyata: debugging multi-langkah, refactoring skala besar, dan chaining tool otonom di seluruh alur kerja yang panjang.
Model ini dibangun untuk agen yang beroperasi di seluruh alur kerja, bukan hanya prompt tunggal, menjadikannya sangat efektif untuk codebase besar, refactor kompleks, dan debugging multi-langkah yang berkembang dari waktu ke waktu. Jika Anda membangun agen coding atau pipeline agentik, ini adalah model yang benar-benar menutup isu dan mengirimkan kode dengan kualitas produksi.
Yang penting secara operasional: Opus 4.6 memecah tugas kompleks menjadi sub-tugas independen, menjalankan tool dan subagen secara paralel, dan mengidentifikasi pemblokir dengan presisi nyata. Itulah perilaku yang membuat perbedaan dalam otomasi berbasis CI/CD nyata, bukan sekadar lingkungan demo.
Ketersediaan API, Harga, dan Dokumentasi
Inilah bagian yang penting untuk timeline pengambilan keputusan Anda. Claude Opus 4.6 memberikan penalaran mutakhir dengan harga $5 input / $25 output per juta token — pengurangan 67% dari era Opus 4.1 sebesar $15/$75. Dokumentasi Claude API lengkap sudah publik, berversi, dan stabil. Anda dapat mengaksesnya melalui claude-opus-4-6 hari ini.
Fitur unggulan dari generasi 4.6 adalah bahwa jendela konteks 1 juta token penuh sudah termasuk dalam harga standar, menghilangkan biaya tambahan konteks panjang yang berlaku pada model sebelumnya. Untuk tim yang berurusan dengan ingesti codebase besar atau alur kerja penelitian panjang, ini adalah pengurangan biaya yang signifikan dibandingkan generasi sebelumnya.
Tuas optimasi biaya yang sepenuhnya terdokumentasi dan tersedia sekarang:
Apa yang Dikatakan Kebocoran Claude Mythos Tentang Kesenjangan Tersebut
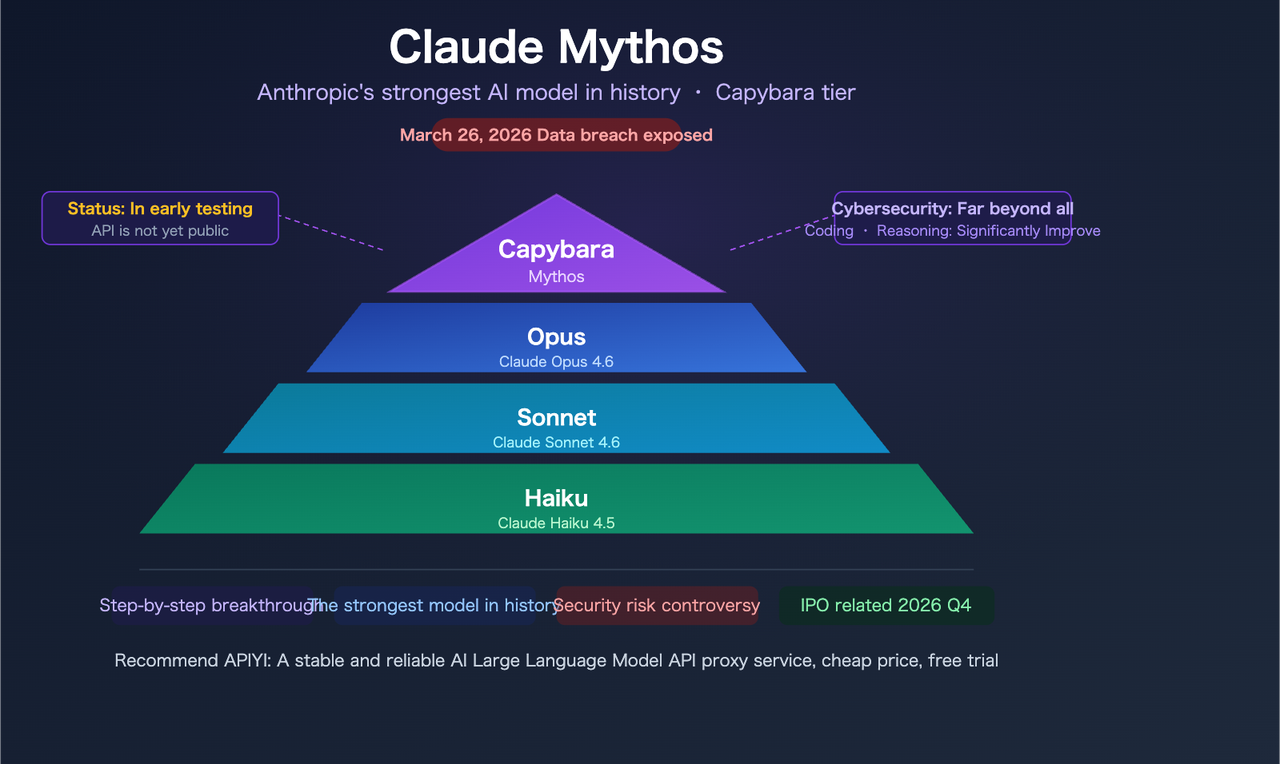
Awal bulan ini, Fortune melaporkan bahwa Anthropic secara tidak sengaja mengekspos hampir 3.000 file internal dalam penyimpanan data yang dikonfigurasi salah dan dapat dicari secara publik. Di antaranya: draf posting blog tentang model bernama Claude Mythos — yang juga memiliki nama kode internal “Capybara.”
Kerangka penting sebelum masuk: semua yang di bawah ini berasal dari dokumen draf yang belum diverifikasi, bukan rilis resmi. Tidak ada benchmark publik, tidak ada akses API, tidak ada halaman harga. Anthropic telah mengonfirmasi model tersebut ada dan sedang dalam pengujian terbatas. Selebihnya masih berupa draf.
Coding — “Skor yang Jauh Lebih Tinggi” Diuraikan
Draf yang bocor menyatakan: “Dibandingkan dengan model terbaik kami sebelumnya, Claude Opus 4.6, Capybara mendapatkan skor yang jauh lebih tinggi pada tes coding perangkat lunak, penalaran akademis, dan keamanan siber, di antara yang lainnya.” Itu adalah bahasa yang bermakna dari dokumen internal — “jauh lebih tinggi” bukan salinan pemasaran yang berhati-hati, ini adalah klaim internal yang kuat.
Yang tidak kita miliki: angka spesifik. Tidak ada skor spesifik yang telah dipublikasikan di luar bahasa kualitatif dalam draf tersebut. Siapa pun yang mengutip angka benchmark Mythos yang tepat saat ini sedang membuatnya. Pembacaan jujur di sini adalah bahwa evaluasi internal Anthropic menunjukkan kesenjangan yang cukup besar untuk membenarkan tingkat produk baru — yang itu sendiri merupakan sinyal signifikan, tetapi bukan hal yang sama dengan memiliki data terverifikasi.

Peningkatan Penalaran Akademis
Draf yang bocor mengelompokkan penalaran akademis bersama coding sebagai kemampuan yang terdiferensiasi utama. Anthropic menggambarkan Mythos sebagai “model tujuan umum dengan kemajuan bermakna dalam penalaran, coding, dan keamanan siber.” Untuk developer yang membangun asisten penelitian, pipeline analisis dokumen, atau alur kerja penalaran hukum/keuangan, ini patut dipantau — Opus 4.6 sudah mencapai 90,2% pada BigLaw Bench, dan jika Mythos mendorong batas itu lebih jauh, area permukaan kasus penggunaan meluas secara signifikan.
Kemampuan Keamanan Siber: Wilayah Baru
Ini adalah dimensi kemampuan yang mendapatkan liputan paling banyak — dan dengan alasan yang baik. Draf yang bocor menggambarkan model tersebut sebagai “saat ini jauh di depan model AI lainnya dalam kemampuan siber” dan memperingatkan bahwa model ini “mengisyaratkan gelombang model yang akan datang yang dapat mengeksploitasi kerentanan dengan cara yang jauh melampaui upaya para pembela.”
Dokumen internal yang bocor memperingatkan model tersebut dapat secara signifikan meningkatkan risiko keamanan siber dengan menemukan dan mengeksploitasi kerentanan perangkat lunak secara cepat, berpotensi mempercepat perlombaan senjata siber. Itulah mengapa peluncuran awal Anthropic dibatasi untuk organisasi yang berfokus pada pertahanan siber — langkah yang tidak biasa yang menandakan kekhawatiran nyata tentang penyalahgunaan, bukan sekadar pertunjukan keselamatan standar.
Ketegangan dual-use di sini nyata. Opus 4.6 milik Anthropic saat ini telah menunjukkan kemampuan untuk menemukan kerentanan yang sebelumnya tidak diketahui dalam codebase produksi, sebuah kemampuan yang diakui perusahaan bersifat dual-use — membantu peretas dan pembela sama-sama. Mythos tampaknya mendorong kemampuan itu jauh lebih jauh, yang menjelaskan peluncuran yang hati-hati.
Ini Adalah Tingkat Baru, Bukan Peningkatan Versi — Mengapa Itu Penting
Capybara di Atas Opus Secara Struktural
Draf yang bocor menyatakan: “Capybara adalah nama baru untuk tingkat model baru: lebih besar dan lebih cerdas dari model Opus kami — yang, hingga sekarang, adalah yang paling kuat.” Ini secara struktural berbeda dari Opus 4.5 → Opus 4.6. Anthropic saat ini memiliki tiga tingkat: Haiku, Sonnet, Opus. Capybara akan menambahkan tingkat keempat di atas semua itu.
Itu penting untuk cara Anda mengarsitektur sistem Anda. Jika Anda membangun dengan asumsi bahwa Opus selalu menjadi batasnya, tingkat baru di atasnya berarti peningkatan kemampuan potensial yang bukan hanya peningkatan fine-tune bertahap — mereka mewakili kelas tingkat keberhasilan tugas yang berbeda.
Harga: Lebih Mahal dengan Desain
Belum ada harga resmi, tetapi sinyal strukturalnya jelas. Draf blog mencatat bahwa model ini mahal untuk dijalankan dan belum siap untuk rilis umum. Mengingat Capybara berada di atas Opus dalam tingkat baru, perkirakan harga di atas $5/$25 per juta token saat ini untuk Opus 4.6. Berapa banyak di atasnya memang tidak diketahui — tetapi rencanakan agar harganya jauh lebih tinggi, bukan hanya kenaikan kecil.
Ini belum tentu kabar buruk. Pengurangan harga 67% dari Opus 4.1 ke Opus 4.6 menunjukkan Anthropic telah belajar menurunkan harga unggulan antar generasi. Peluncuran Capybara dengan harga premium hari ini tidak berarti harganya tetap di sana dalam 12 bulan. Polanya menunjukkan pertanyaan ROI sebenarnya adalah apakah lompatan kemampuan membenarkan biaya pada distribusi tugas spesifik Anda.

Haruskah Tim Anda Menunggu Claude Mythos?
Ini adalah keputusan nyata yang Anda cari. Ini adalah kerangka yang jujur.
Jika Anda Membangun Agen Coding atau Alur Kerja Agentik
Bangun sekarang dengan Opus 4.6. Kesenjangan kemampuan mungkin nyata, tetapi menunggu model yang belum dirilis tanpa timeline publik bukanlah strategi produk. Opus 4.6 sudah menjadi model publik terkuat untuk coding agentik — Terminal-Bench 2.0 di 65,4% adalah baseline yang bermakna yang mendukung kasus penggunaan produksi hari ini.
Poin yang lebih penting: keputusan arsitektur yang Anda buat sekarang — strategi prompt caching, orkestrasi subagen, pola penggunaan tool — akan ditransfer langsung ke Mythos saat diluncurkan. Bangun di Opus 4.6, rancang untuk routing model-agnostik, dan Anda akan berada dalam posisi yang jauh lebih baik untuk bermigrasi dibandingkan tim yang menunggu dan memulai dari nol.
Jika Prioritas Anda Adalah Efisiensi Biaya pada Skala
Pasti bangun sekarang. Mythos diharapkan lebih mahal dari Opus 4.6, dan tidak ada indikasi tingkat anggaran yang setara saat peluncuran. Jika Anda menjalankan beban kerja volume tinggi di mana $5/$25 per juta token sudah memerlukan optimasi hati-hati dengan pemrosesan batch dan prompt caching, Mythos kemungkinan bukan model default Anda — bahkan setelah tersedia secara publik. Gunakan waktu untuk mengoptimalkan alur kerja Opus 4.6 Anda; penghematan tersebut nyata dan tersedia hari ini.
Matematika yang layak dilakukan: tim yang menghabiskan $2.500/bulan untuk Opus 4.6 standar secara realistis dapat mencapai ~$250/bulan dengan pencampuran model, pemrosesan batch, dan caching. Pengurangan 90% itu mengakumulasi secara signifikan selama berbulan-bulan yang akan Anda habiskan untuk menunggu.
Jika Kasus Penggunaan Anda Melibatkan Riset Kerentanan atau Keamanan
Ini adalah satu kasus di mana menunggu masuk akal — tetapi Anda mungkin tidak punya pilihan. Kelompok akses awal untuk Mythos berfokus pada peneliti keamanan dan pembela — tujuannya adalah mempersiapkan pertahanan sebelum kemampuan ofensif model tersebut tersedia secara luas. Jika tim Anda bekerja dalam penelitian keamanan ofensif atau tooling defensif, langkah yang tepat adalah mengajukan permohonan akses awal melalui saluran Anthropic dan terus membangun di Opus 4.6 sementara itu.
Untuk tooling keamanan enterprise umum (pemindaian kode, kepatuhan, triase kerentanan), Opus 4.6 sudah mampu dan tersedia sepenuhnya. Mythos kemungkinan memperluas batas atas, bukan batas bawah.
Apa yang Harus Dilakukan Sementara Mythos Tidak Tersedia Secara Publik
Secara konkret, inilah cara menghindari upaya yang terbuang sambil tetap siap mengadopsi Mythos secara efisien:
Rancang untuk routing model-agnostik. Abstraksi panggilan model Anda di balik lapisan routing sehingga menukar claude-opus-4-6 dengan string model claude-capybara-* di masa depan hanyalah perubahan konfigurasi, bukan penulisan ulang arsitektur. Ini adalah praktik yang baik terlepas dari Mythos — ini juga memungkinkan Anda merutekan tugas yang sensitif biaya ke Sonnet 4.6 hari ini.
# Contoh: wrapper routing model-agnostik
import anthropic
MODEL_CONFIG = {
"flagship": "claude-opus-4-6", # ganti di sini saat Mythos diluncurkan
"balanced": "claude-sonnet-4-6",
"fast": "claude-haiku-4-5-20251001"
}
def call_claude(task_tier: str, messages: list, **kwargs):
client = anthropic.Anthropic()
return client.messages.create(
model=MODEL_CONFIG[task_tier],
max_tokens=1024,
messages=messages,
**kwargs
)Implementasikan prompt caching sekarang. Menurut dokumentasi prompt caching Anthropic, penulisan cache dikenakan biaya tambahan 25% pada hit pertama, kemudian dibaca dengan diskon 90% pada hit berikutnya. Untuk alur kerja agentik dengan sistem prompt yang berulang atau blok konteks besar, ini adalah optimasi biaya dengan leverage tertinggi yang tersedia — dan akan bekerja dengan cara yang sama pada Mythos.
Pantau cadence rilis resmi. Anthropic telah mengonfirmasi pengujian dengan pelanggan akses awal. Model peluncuran bertahap yang digunakan Anthropic — mitra keamanan terlebih dahulu, kemudian akses yang lebih luas — menunjukkan ketersediaan API umum kemungkinan berminggu-minggu hingga berbulan-bulan lagi, bukan dalam beberapa hari.
Evaluasi distribusi tugas Anda dengan jujur. Jika 80% panggilan API Anda adalah ringkasan dokumen, tanya jawab, atau ekstraksi terstruktur, kemajuan coding dan keamanan siber Mythos mungkin tidak banyak menggerakkan jarum Anda. Opus 4.6 sudah cukup kuat untuk beban kerja tersebut. Simpan evaluasi Mythos Anda untuk tugas-tugas di mana Anda saat ini mencapai batas atas Opus.
FAQ
T: Bisakah saya menggunakan Claude Mythos hari ini?
Tidak. Pada akhir Maret 2026, Claude Mythos (Capybara) hanya tersedia untuk sekelompok kecil pelanggan akses awal, khususnya mereka yang bekerja pada aplikasi pertahanan siber. Tidak ada API publik, tidak ada dokumentasi, dan tidak ada tanggal peluncuran yang diumumkan. Claude Opus 4.6, yang dapat diakses melalui claude-opus-4-6 di Anthropic API, tetap menjadi model publik terkuat yang tersedia.
T: Apakah Opus 4.6 masih model Claude publik terbaik?
Ya. Claude Opus 4.6 dan Sonnet 4.6 tetap menjadi model Claude publik yang paling mampu — dan keduanya sudah sangat powerful untuk coding, penalaran, dan tugas kompleks. Opus 4.6 memimpin papan peringkat publik untuk coding agentik dan sepenuhnya terdokumentasi dengan akses API stabil di seluruh platform Anthropic, AWS Bedrock, Google Vertex AI, dan Microsoft Foundry.
T: Seberapa lebih mahal Claude Mythos nantinya?
Tidak diketahui. Draf yang bocor mengonfirmasi model ini “mahal untuk dijalankan,” dan tingkat Capybara baru yang berada di atas Opus secara struktural mengimplikasikan premium harga di atas $5/$25 per juta token saat ini untuk Opus 4.6. Tidak ada harga resmi yang telah dipublikasikan. Preseden historis menunjukkan Anthropic memang mengurangi harga unggulan antar generasi model, sehingga harga peluncuran awal mungkin tidak mencerminkan biaya jangka panjang.
Postingan Sebelumnya:
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8

API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi

Harga GPT-5.4 Mini: Biaya Input, Cache & Output

API MAI-Image-2.5: Yang Perlu Diketahui Para Developer
