Kemampuan Keamanan Siber Claude Mythos: Yang Perlu Diketahui Developer dan Tim Keamanan
Claude Mythos telah menimbulkan kekhawatiran serius di bidang keamanan siber. Inilah arti klaim yang bocor bagi developer dan tim keamanan yang mengevaluasi model ini.

“Apakah kita perlu khawatir tentang ini?” Pesan dari tim keamanan klien mendarat di Slack sementara saya sedang meninjau opsi tooling AI internal dan berita kebocoran Anthropic muncul di feed saya.
Tersedia di WaveSpeedAI — harga per-token transparan, endpoint kompatibel OpenAI. Claude Opus 4.7 API → · Buka Playground →
Pertanyaan itu terus muncul dalam 48 jam berikutnya. Bukan dari para penggemar AI, melainkan dari CISO, pemimpin keamanan, dan pengembang yang membangun di atas infrastruktur AI dan tiba-tiba mendapati diri mereka dalam percakapan yang tidak mereka siapkan.
Kisah Mythos bukan sekadar pengumuman produk AI. Ini adalah sinyal tentang ke mana lingkungan ancaman menuju, dan memahami apa yang benar-benar terkonfirmasi versus apa yang hanya spekulasi jauh lebih penting dari biasanya ketika model baru diluncurkan. Dan dalam tulisan ini, kita akan menyelidiki jawaban atas pertanyaan ini bersama-sama.
Apa yang Diungkapkan Draft yang Bocor tentang Kemampuan Keamanan Siber Mythos
Draft posting blog yang bocor — bagian dari hampir 3.000 aset internal yang terekspos — berisi dua klaim mencolok tentang keamanan siber yang telah banyak dikutip. Kata-kata Anthropic sendiri, yang ditulis secara internal sebelum pengumuman publik apa pun, menggambarkan model yang belum dirilis (secara internal terkait dengan tingkatan “Capybara” dan disebut sebagai Claude Mythos) sebagai “saat ini jauh melampaui model AI lainnya dalam kemampuan siber.” Lebih lanjut diperingatkan bahwa model tersebut “menjadi pertanda gelombang model yang akan datang yang dapat mengeksploitasi kerentanan dengan cara yang jauh melampaui upaya para pembela.”
Bagian kunci kedua menunjukkan kehati-hatian yang tidak biasa: “Dalam mempersiapkan perilisan Claude Mythos, kami ingin bertindak dengan sangat hati-hati dan memahami risiko yang ditimbulkannya — bahkan melampaui apa yang kami pelajari dalam pengujian kami sendiri. Secara khusus, kami ingin memahami potensi risiko jangka pendek model ini di ranah keamanan siber — dan berbagi hasilnya untuk membantu para pembela siber mempersiapkan diri.”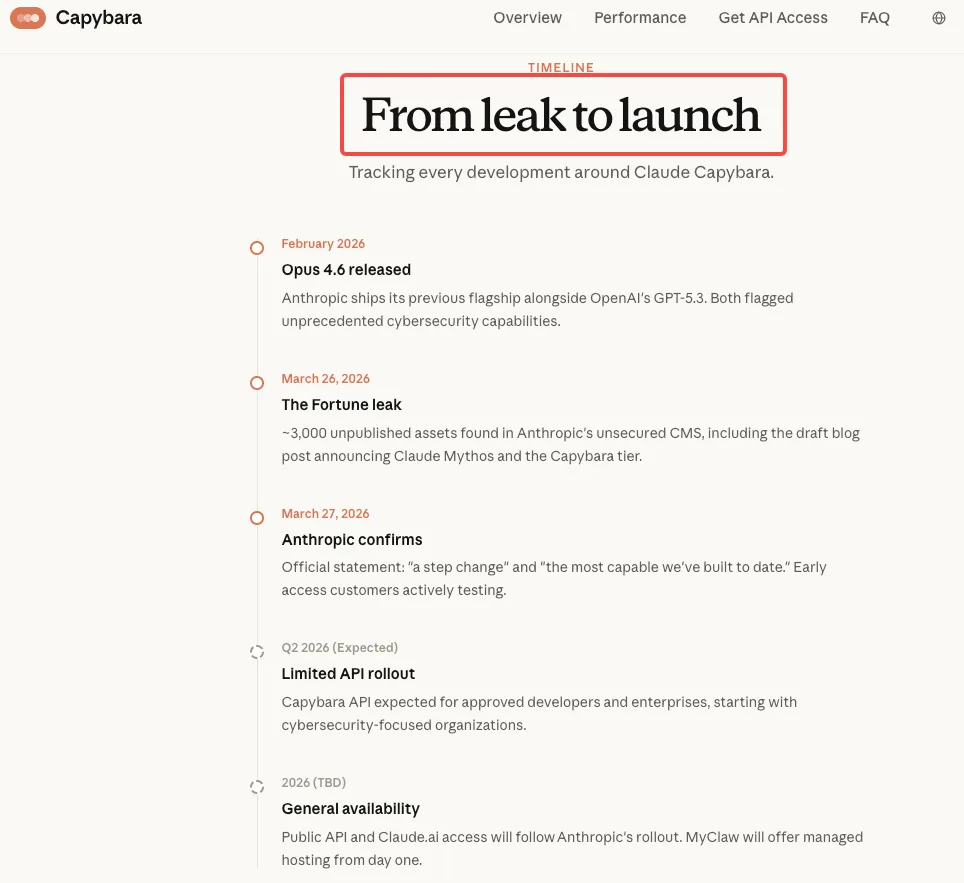
Framing ini memperlakukan risiko keamanan siber bukan sebagai keterbatasan yang dapat dikelola, melainkan sebagai eksternalitas signifikan yang memerlukan berbagi proaktif dengan para pembela. Ini adalah sikap yang sangat berbeda dari rilis Anthropic sebelumnya.
Apa yang hilang dari kebocoran tersebut? Angka benchmark spesifik, kategori eksploit, atau metodologi terperinci. Klaim “skor yang jauh lebih tinggi dalam tes keamanan siber” mewakili sejauh mana kemampuan yang diungkapkan. Apa pun yang lebih spesifik yang beredar online adalah ekstrapolasi.
Mengapa Anthropic Memperlakukan Ini sebagai Risiko yang Belum Pernah Ada Sebelumnya
Apa yang Sebenarnya Dimaksud dengan “Jauh Melampaui Model AI Lain dalam Kemampuan Siber”
Klaim ini terasa berbeda jika Anda memahami apa yang sudah mampu dilakukan oleh Opus 4.6 — baseline saat ini. Ini bukan Mythos mengungguli standar yang rendah.
Menggunakan Claude Opus 4.6, Tim Red Frontier Anthropic menemukan dan memvalidasi lebih dari 500 kerentanan berkepatutan tinggi dalam codebase open-source produksi — bug yang tidak terdeteksi selama beberapa dekade, meskipun telah ditinjau oleh para ahli selama bertahun-tahun. Tim ini tidak menggunakan instruksi khusus atau harness kustom, hanya mengandalkan kemampuan bawaan model.
Satu kasus yang patut dicatat: Opus 4.6 mengidentifikasi blind SQL injection di Ghost CMS (platform dengan 50.000+ bintang GitHub dan reputasi keamanan yang sebelumnya bersih) dalam waktu sekitar 90 menit.
Perbedaan struktural antara penemuan kerentanan berbasis AI dan fuzzing tradisional adalah konteks penting di sini. Fuzzer memasukkan input ke dalam kode hingga sesuatu rusak. Claude bernalar tentang kode: melacak logika di berbagai komponen, membaca riwayat commit untuk menemukan varian yang belum ditambal dari bug yang telah diperbaiki, dan mengevaluasi jalur kode mana yang secara inheren berisiko daripada mempelajari setiap kemungkinan input. Mythos, menurut penilaian internal Anthropic sendiri, melakukan ini lebih baik dari apa pun yang tersedia saat ini — dengan margin yang signifikan.
Masalah Kesenjangan Pembela: Mengapa Ofensif Bisa Melampaui Defensif
Wawasan terpenting dari draft tersebut bukan mengkatalogkan jenis serangan baru. Melainkan mengartikulasikan mengapa asimetri penyerang-pembela ada sejak awal. Penyerang hanya perlu menemukan satu kelemahan. Pembela harus mencakup segalanya. Model AI yang dapat bernalar tentang kode, mengidentifikasi pola kerentanan potensial, dan membantu penyempurnaan eksploit mempersingkat waktu dari “ide” menjadi “serangan yang berhasil.”
Anthropic dilaporkan telah memperingatkan pejabat pemerintah senior bahwa Mythos dapat membuat serangan siber skala besar lebih mungkin terjadi pada tahun 2026 dengan memungkinkan agen otonom yang sangat canggih. Polling Dark Reading dari awal 2026 menemukan bahwa 48% profesional keamanan siber kini menempatkan AI agentik sebagai vektor serangan teratas untuk tahun ini — melampaui deepfake dan rekayasa sosial.
Ini bukan masalah yang diciptakan Mythos dari nol; ini adalah akselerator. Musuh sudah menggunakan AI tanpa keraguan atau hambatan kepatuhan. Pembela yang membatasi akses ke model frontier berisiko menyerahkan posisi penting.
Aplikasi Defensif vs Ofensif: Di Mana Batasnya
Kasus Penggunaan Legitim: Pemindaian Kerentanan, Red Teaming, Penguatan Kode
Aplikasi defensif dari kemampuan Mythos benar-benar signifikan — dan itulah alasan utama Anthropic membangun dan merilis ini sama sekali.
Claude Code Security, kemampuan baru yang dibangun ke dalam Claude Code, memindai codebase untuk kerentanan keamanan dan menyarankan patch perangkat lunak yang ditargetkan untuk ditinjau manusia, memungkinkan tim menemukan dan memperbaiki masalah keamanan yang sering terlewat oleh metode tradisional. Tidak ada yang diterapkan tanpa persetujuan manusia: Claude Code Security mengidentifikasi masalah dan menyarankan solusi, tetapi pengembang selalu yang membuat keputusan.
Kemampuan tingkat Mythos yang diterapkan pada alur kerja ini berarti menemukan kelas kerentanan yang bahkan Opus 4.6 lewatkan — cacat yang bergantung pada konteks dalam logika bisnis, pola interaksi multi-komponen, bypass autentikasi yang memerlukan pemahaman arsitektur sistem daripada pola kode. Bagi tim keamanan yang saat ini membayar pengujian penetrasi manual dalam siklus triwulanan, pemindaian berkelanjutan berbasis AI dengan kualitas penalaran tingkat Mythos mewakili pergeseran berarti dalam apa yang dapat dicapai secara operasional.
Untuk red team, kekuatan yang sama memerlukan scoping dan otorisasi yang ketat. Model itu sendiri tidak membedakan antara pengujian yang diotorisasi dan penggunaan berbahaya — tanggung jawab itu tetap ada pada proses dan guardrail Anda.
Apa yang Dilakukan Anthropic untuk Membatasi Penyalahgunaan
Bersama Opus 4.6, Anthropic menerapkan probe tingkat aktivasi untuk mendeteksi dan memblokir penyalahgunaan siber secara real time, mengakui potensi gesekan bagi penelitian keamanan yang legitim. “Ini akan menciptakan gesekan bagi penelitian legitim dan beberapa pekerjaan defensif, dan kami ingin bekerja sama dengan komunitas penelitian keamanan untuk menemukan cara mengatasinya seiring munculnya masalah,” peringatkan perusahaan.
Untuk Mythos secara khusus, kontrolnya bersifat struktural daripada sekadar teknis. Berdasarkan dokumen yang bocor dan pernyataan publik Anthropic, akses awal dibatasi untuk peneliti keamanan dan pembela yang telah diverifikasi — tujuannya adalah membangun tooling defensif sebelum kemampuan ofensif tersedia secara luas. Ini mencerminkan penanganan Anthropic terhadap rilis berisiko tinggi sebelumnya dan selaras dengan praktik yang direkomendasikan oleh Kerangka Manajemen Risiko AI NIST, yang menganjurkan penerapan bertahap dengan pemantauan berkelanjutan untuk sistem AI penggunaan ganda.
Bagian taktik AI adversarial dari kerangka MITRE ATT&CK layak ditinjau oleh tim keamanan mana pun yang mencoba memodelkan permukaan ancaman di sini. Taktik yang didokumentasikan di sana mengasumsikan model yang jauh kurang mampu dari apa yang Mythos mewakili.
Apa yang Dievaluasi Pelanggan Akses Awal Keamanan
Draft yang bocor eksplisit tentang prioritas peluncuran Anthropic: “Kami akan perlahan-lahan memperluas akses ke Claude Mythos ke lebih banyak pelanggan yang menggunakan Claude API selama beberapa minggu ke depan. Karena kami sangat tertarik pada penggunaan keamanan siber, di situlah kami bertujuan untuk memperluas EAP pada awalnya.”
Kelompok akses awal mengevaluasi Mythos terhadap masalah spesifik yang dirancang untuk diatasi oleh model: menemukan kerentanan dalam codebase produksi yang diperkuat lebih cepat dan lebih komprehensif daripada alat yang ada. Para analis mencatat bahwa ini bisa mempersingkat kesenjangan ofensif-defensif dari kedua arah — memungkinkan penemuan kerentanan yang lebih cepat, red teaming berkelanjutan, dan perburuan ancaman, sekaligus menurunkan hambatan untuk serangan canggih jika disalahgunakan.
Bagi pelanggan keamanan yang saat ini dalam periode evaluasi, pertanyaan praktis berpusat pada tiga area: bagaimana Mythos berintegrasi dengan alur kerja SIEM dan manajemen kerentanan yang ada, apakah temuan model dapat ditampilkan dalam format yang kompatibel dengan sistem tiket yang ada, dan seperti apa persyaratan tinjauan manusia pada skala besar.
Dalam wawancara dengan lebih dari 40 CISO di berbagai industri, VentureBeat menemukan bahwa kerangka tata kelola formal untuk alat pemindaian berbasis penalaran adalah pengecualian, bukan norma. Respons paling umum adalah bahwa area tersebut dianggap begitu baru sehingga banyak CISO tidak berpikir kemampuan ini akan tiba lebih awal pada tahun 2026. Tim di dalam program akses awal, dalam arti nyata, sedang menulis buku panduan tata kelola yang akan diikuti oleh seluruh industri.
Implikasi bagi Tim Pengembang yang Membangun di Atas Infrastruktur AI
Jika tim Anda membangun produk di atas Claude atau model AI frontier mana pun, situasi Mythos menciptakan dua kategori kekhawatiran yang berbeda.
Yang pertama bersifat langsung: Anda adalah target potensial untuk serangan berbantuan AI, dan serangan-serangan tersebut semakin mampu.
Kekhawatiran kedua bersifat arsitektural: bagaimana infrastruktur AI Anda diamankan terhadap injeksi prompt, akses tool yang tidak sah, dan penyalahgunaan agen. Organisasi perlu memperlakukan setiap agen, bot, dan layanan AI sebagai identitas, membawa tingkat kontrol, izin, dan pengawasan yang sama kepada identitas non-manusia seperti yang mereka lakukan kepada pengguna manusia — memerlukan inventaris akses, dan menghilangkan kredensial yang di-hardcode yang menciptakan bot tidak aman.
Secara praktis, ini berarti beberapa hal bagi tim yang membangun di atas Claude saat ini:
Batasi akses server MCP dengan ketat. Setiap server MCP yang Anda hubungkan ke agen Claude adalah permukaan serangan potensial. Kemampuan agentik yang diperluas yang membuat Claude Code kuat juga menjadikan izin agen yang cakupannya buruk sebagai vektor risiko yang berarti.
Perlakukan CLAUDE.md sebagai dokumen keamanan. Instruksi dalam CLAUDE.md yang mendefinisikan alat apa yang dapat digunakan agen, file mana yang dapat dibaca, dan operasi apa yang dapat dilakukan adalah kontrol keamanan, bukan sekadar pembantu produktivitas. CLAUDE.md yang ditulis dengan buruk yang memberikan akses file atau izin alat yang luas memperbesar risiko.
Terapkan tinjauan manusia pada patch yang dihasilkan AI, bukan hanya kode yang dihasilkan AI. Kode yang dihasilkan AI 2,74x lebih mungkin memperkenalkan kerentanan XSS dan 1,91x lebih mungkin memperkenalkan referensi objek yang tidak aman dibandingkan kode yang ditulis manusia. Kemampuan penalaran yang sama yang menemukan kerentanan dapat memperkenalkannya. Tinjauan manusia terhadap perubahan yang relevan dengan keamanan bukanlah opsional.
FAQ
Bisakah tim keamanan mengakses Claude Mythos sekarang?
Tidak melalui saluran publik mana pun. Rencana peluncuran model ini mencerminkan kekhawatiran keamanan siber: Akses awal dibatasi untuk organisasi keamanan siber defensif yang telah diverifikasi. Bagi tim keamanan yang ingin mempersiapkan diri, Claude Code Security — dibangun di atas Opus 4.6, tersedia sekarang dalam pratinjau penelitian terbatas untuk pelanggan Enterprise dan Team — adalah alat yang paling dekat tersedia secara publik, dan baseline yang berguna untuk memahami apa yang akan diperluas oleh kemampuan tingkat Mythos.
Perlindungan apa yang dibangun Anthropic?
Langkah-langkah yang dikonfirmasi mencakup probe deteksi penyalahgunaan real time, peluncuran bertahap yang memprioritaskan pembela, dan persyaratan human-in-the-loop untuk patch. Untuk Mythos, penekanannya ada pada tata kelola penerapan, batas alat, dan jejak audit.
Apakah Claude Mythos akan tersedia untuk red teaming komersial?
Belum dikonfirmasi. Kelompok akses awal berfokus pada kasus penggunaan keamanan defensif. Red teaming komersial — di mana organisasi mempekerjakan perusahaan keamanan untuk secara aktif menyelidiki sistem mereka — berada di zona yang ambigu: itu adalah ofensif yang diotorisasi. Mengingat kekhawatiran yang dinyatakan perusahaan tentang penyalahgunaan ofensif, perkirakan kontrol akses yang bermakna daripada akses API terbuka untuk kasus penggunaan red teaming.
Posting Sebelumnya:
- Claude Mythos vs Claude Opus 4.6: What the Leak Reveals for Developers
- Claude Mythos (Opus 5) Leaked: What We Know So Far
- What Is Claude Mythos? Leak, Capybara Tier & What Anthropic Confirmed
- Claude Sonnet 4.6: A “Non-Hogging the Spotlight” Work Model
- Claude Opus 4.6 and Sonnet 4.6: Everything You Need to Know
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8
API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi
Harga GPT-5.4 Mini: Biaya Input, Cache & Output
API MAI-Image-2.5: Yang Perlu Diketahui Para Developer