Claude Code Agent Harness: Arsitektur dan Penjelasannya
Bagaimana Claude Code menghubungkan alat, mengelola izin, dan mengatur sesi agen — penjelasan teknis untuk para pengembang.

Saya terus menghadapi pertanyaan yang sama saat membangun setup tool-calling saya sendiri: mengapa proses penyambungan terasa jauh lebih sulit daripada prompting?
Bagian modelnya cepat dipahami. Tapi begitu saya perlu agar model melakukan sesuatu — membaca file, menjalankan perintah shell, berkomunikasi dengan layanan eksternal — setiap keputusan terasa seperti bisa merusak sesuatu. Batas izin. Batas konteks. Dispatching tool.
Lalu, pada akhir Maret 2026, source code Claude Code secara tidak sengaja terekspos melalui source map npm di versi 2.1.88. Lebih dari 500.000 baris TypeScript, dicerminkan dalam hitungan jam. Anthropic mengonfirmasi bahwa itu adalah kesalahan packaging — tidak ada data pelanggan yang terlibat — dan mulai mengeluarkan takedown DMCA.
Namun arsitekturnya menjadi pengetahuan publik. Dan yang terungkap bukan modelnya. Melainkan harness-nya.
Catatan tentang sumber: Detail di sini berasal dari analisis komunitas, reproduksi open-source, serta dokumentasi publik dan blog rekayasa Anthropic — bukan dari kode yang bocor itu sendiri. Detail yang tidak pasti ditandai.
Apa Itu Agent Harness?
Definisi dan peran dalam sistem agentik
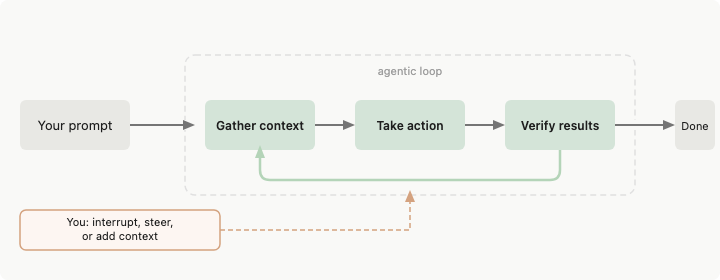
Agent harness adalah segala sesuatu antara language model dan dunia nyata. Model menghasilkan teks. Harness memutuskan apa yang bisa disentuh oleh teks tersebut.
Dokumentasi Anthropic untuk Claude Code mendeskripsikannya secara langsung: Claude Code “menyediakan tools, manajemen konteks, dan lingkungan eksekusi yang mengubah language model menjadi agen coding yang mumpuni.” Model melakukan penalaran. Harness melakukan tindakan.
Ketika agen Anda membaca sebuah file, harness memutuskan apakah pembacaan itu diizinkan, apa yang terjadi pada hasilnya, dan berapa banyak dari respons yang muat di prompt berikutnya. Model tidak pernah menyentuh sistem file secara langsung.
Mengapa desain harness penting untuk produksi
Kebanyakan demo agen melewatkan bagian ini. Anda melihat model memanggil fungsi, mendapatkan hasil, memanggil yang lain. Terlihat rapi. Kemudian Anda menjalankannya selama 45 menit pada codebase nyata, dan segalanya perlahan-lahan berantakan — konteks meluap, izin terlalu longgar atau terlalu mengganggu, hasil tool terpotong tanpa sepengetahuan model.
Tim rekayasa Anthropic telah menulis tentang hal ini: bahkan model frontier yang berjalan dalam loop di beberapa context window akan berkinerja buruk tanpa harness yang dirancang dengan baik. Agen mencoba melakukan terlalu banyak sekaligus, atau mendeklarasikan pekerjaan selesai sebelum waktunya. Harness memaksakan struktur pada kecenderungan tersebut.

Permukaan Tool Claude Code
Kategori tool utama
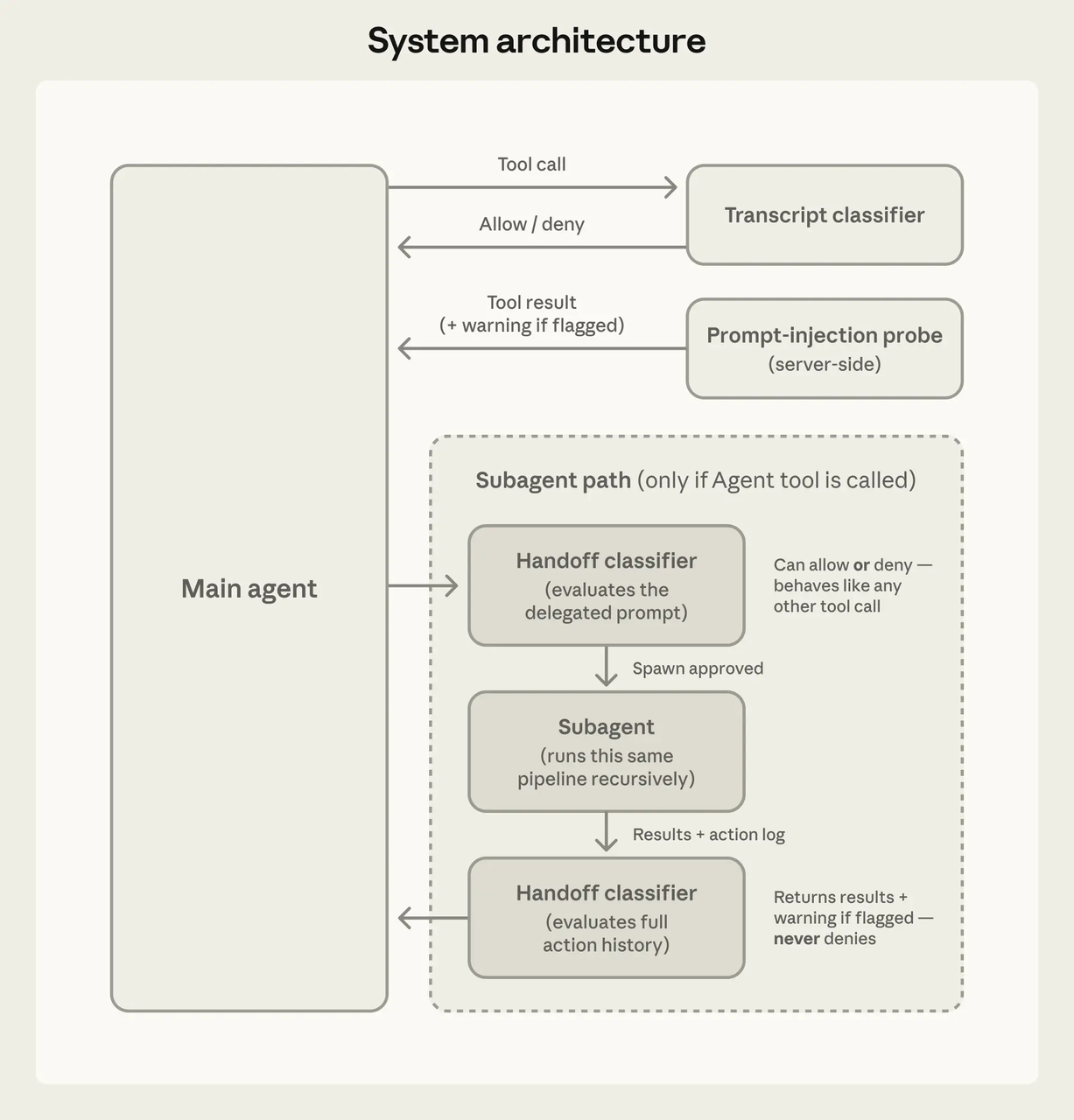
Berdasarkan dokumentasi resmi Claude Code dan analisis publik, Claude Code mengekspos sekitar 19 tool yang dibatasi izin. Kategori utamanya: pembacaan dan pengeditan file, eksekusi shell (Bash), operasi Git, pengambilan web, pengeditan notebook, dan pemanggilan MCP tool. Analisis komunitas menyarankan jumlahnya mungkin mendekati 40 ketika Anda menyertakan integrasi LSP, spawning subagent, dan tool koordinasi internal.
Setiap tool disandbox secara independen. Bukan “agen memiliki akses filesystem” — melainkan “agen dapat menggunakan tool Read, dan Read memiliki gerbang izinnya sendiri yang memeriksa pipeline aturan sebelum apapun dieksekusi.”
Cara tool didaftarkan dan di-dispatch
Model memutuskan apa yang ingin dicoba. Sistem tool memutuskan apa yang diizinkan. Secara arsitektur terpisah.
Setiap pemanggilan tool melalui pemeriksaan izin sebelum eksekusi. Penyelidikan mendalam komunitas mendeskripsikan fungsi inti yang mengevaluasi aturan deny/ask/allow dalam urutan tersebut — deny selalu menang. Tiga kemungkinan hasil: lanjutkan secara diam-diam, prompt pengguna, atau blokir.
Model yang dikompromikan tidak dapat melewati pemeriksaan keamanan dengan cara yang persuasif. Harness tidak peduli dengan argumen model. Aturan tetaplah aturan.
Tingkatan izin
Model izin Claude Code telah dideskripsikan oleh beberapa analis komunitas sebagai kira-kira tiga tingkatan:
Tingkat 1 — Disetujui otomatis: Tindakan read-only atau yang pada dasarnya aman. Pembacaan file, pencarian teks, navigasi kode. Tindakan ini tidak mengubah state, sehingga berjalan tanpa interupsi.
Tingkat 2 — Prompt untuk konfirmasi: Tindakan yang memodifikasi state dengan cara yang terkontrol. Pengeditan file, perintah shell tertentu. Dalam mode auto (diperkenalkan Maret 2026), sebuah classifier latar belakang yang berjalan di Sonnet 4.6 mengevaluasi apakah tindakan ini dapat dilanjutkan tanpa bertanya. Classifier melihat permintaan pengguna dan pemanggilan tool, tetapi tidak melihat prosa model — sebuah pilihan desain yang disengaja untuk mencegah model merayu jalan keluarnya melewati gerbang.
 Tingkat 3 — Memerlukan persetujuan eksplisit atau diblokir: Operasi berisiko tinggi. Perintah shell yang dapat memodifikasi state sistem secara tak terduga, operasi di luar direktori kerja, apapun yang terlihat seperti eksfiltrasi data.
Tingkat 3 — Memerlukan persetujuan eksplisit atau diblokir: Operasi berisiko tinggi. Perintah shell yang dapat memodifikasi state sistem secara tak terduga, operasi di luar direktori kerja, apapun yang terlihat seperti eksfiltrasi data.
Satu catatan: framing tiga tingkatan berasal dari analisis komunitas, bukan dari dokumentasi resmi Anthropic. Sistem resmi menggunakan aturan allow/ask/deny dan enam mode izin (default, acceptEdits, plan, auto, dontAsk, bypassPermissions). “Tiga tingkatan” adalah model mental yang berguna, tapi merupakan penyederhanaan.
Manajemen Sesi dan Konteks
Cara Claude Code melacak state sesi
Claude Code mengakumulasi konteks sepanjang sesi — file yang dibaca, perintah yang dijalankan, hasil grep, diff, output error. Semuanya bertumpuk menjadi satu prompt yang terus berkembang. Tidak seperti antarmuka chat di mana setiap pesan agak independen, sesi Claude Code adalah working memory yang berkelanjutan.
Sesi disimpan secara lokal. Setiap pesan, penggunaan tool, dan hasil disimpan, yang memungkinkan rewind, resume, dan forking. Sebelum perubahan kode, harness membuat snapshot file yang terpengaruh sehingga Anda dapat melakukan revert.
Pemotongan output dan penanganan biaya token
Output tool yang besar adalah masalah nyata. Claude Code menetapkan maksimum default 25.000 token untuk output MCP tool, dengan peringatan di 10.000 token. Penulis server dapat memberi anotasi pada tool untuk mengizinkan hasil yang lebih besar (hingga 500.000 karakter), yang disimpan ke disk daripada disimpan dalam konteks.
Inilah jenis hal yang tidak Anda pikirkan sampai agen Anda diam-diam kehilangan jejak informasi karena hasil tool terpotong. Batas yang eksplisit dan dapat dikonfigurasi dengan fallback berbasis disk — layak untuk ditiru.
Perilaku kompaksi
Hal ini pernah mengganggu saya sebelum saya memahaminya. Ketika penggunaan token mencapai sekitar 98% dari context window, Claude Code melakukan kompaksi otomatis: merangkum riwayat sebelumnya untuk membebaskan ruang. Metadata kritis dipertahankan. Gambar dan PDF dihapus.
Bagian yang tricky: kompaksi dapat kehilangan detail penting. Perbaikan praktisnya: masukkan semua yang kritis ke CLAUDE.md, yang dibaca ulang oleh harness di setiap giliran.
Penelitian Anthropic tentang desain harness menemukan bahwa reset konteks penuh — di mana instance agen baru mengambil alih dari artefak handoff — terkadang bekerja lebih baik daripada kompaksi untuk sesi yang diperpanjang. Kompleksitas orkestrasi lebih besar, tetapi fidelitas konteks lebih baik.
Lapisan Integrasi MCP
Cara Claude Code terhubung ke server MCP
 MCP (Model Context Protocol) adalah standar terbuka untuk menghubungkan AI tool ke layanan eksternal. Claude Code mendukung tiga mode transport: HTTP (direkomendasikan untuk server jarak jauh), stdio (untuk proses lokal), dan SSE.
MCP (Model Context Protocol) adalah standar terbuka untuk menghubungkan AI tool ke layanan eksternal. Claude Code mendukung tiga mode transport: HTTP (direkomendasikan untuk server jarak jauh), stdio (untuk proses lokal), dan SSE.
Menambahkan server hanya satu perintah: claude mcp add server-name --transport http "URL". Setelah itu, tool server muncul sebagai tool yang dapat dipanggil dalam sesi, tunduk pada pipeline izin yang sama seperti tool bawaan.
Penemuan tool dan alur autentikasi
Satu detail yang mengesankan saya: pencarian tool. Ketika Anda menghubungkan server MCP, Claude Code tidak memuat semua skema tool mereka ke dalam konteks di awal. Ia hanya memuat nama tool saat sesi dimulai, kemudian menggunakan mekanisme pencarian untuk menemukan tool yang relevan ketika tugas benar-benar membutuhkannya. Hanya tool yang digunakan Claude yang masuk ke konteks.
Ini menjaga overhead MCP tetap rendah. Alur autentikasi bergantung pada server — OAuth, kunci API, header. Claude Code memerlukan persetujuan eksplisit pengguna untuk server MCP baru.
Apa yang siap produksi vs. masih berkembang
Integrasi MCP fungsional dan aktif digunakan. Namun ada beberapa batasan praktis yang perlu diketahui:
Batas yang direkomendasikan adalah sekitar 5–6 server MCP aktif, karena setiap server memulai subprocess. Pencarian tool membantu overhead konteks, tetapi latensi tetap meningkat melewati batas tersebut.
 Respons MCP yang besar memerlukan penanganan yang hati-hati. Batas default 25K token berfungsi untuk sebagian besar kasus penggunaan tetapi menjadi ketat untuk skema database. Fallback persist-to-disk membantu, meskipun model hanya mendapatkan referensi daripada hasil penuh dalam konteks.
Respons MCP yang besar memerlukan penanganan yang hati-hati. Batas default 25K token berfungsi untuk sebagian besar kasus penggunaan tetapi menjadi ketat untuk skema database. Fallback persist-to-disk membantu, meskipun model hanya mendapatkan referensi daripada hasil penuh dalam konteks.
Dan server MCP yang dibangun komunitas bervariasi dalam kualitasnya. Dokumen Anthropic secara eksplisit mencatat bahwa server pihak ketiga dapat menjadi vektor prompt injection. Sistem izin membantu, tetapi kepercayaan tetap ada pada Anda.
Pelajaran untuk Para Pembuat
Apa yang diungkapkan arsitektur ini tentang sistem agentik tingkat produksi
Beberapa pola dari desain Claude Code yang saya pikir dapat digeneralisasi:
Pisahkan penalaran dari penegakan izin. Model memutuskan apa yang ingin dilakukannya. Sistem yang berbeda memutuskan apakah itu diizinkan. Model yang di-jailbreak tidak dapat mengesampingkan pemeriksaan keamanan karena secara harfiah merupakan jalur kode yang berbeda.
Buat manajemen konteks menjadi eksplisit. Kompaksi, batas pemotongan, pencarian tool, persistensi disk — ini semua adalah mekanisme untuk secara aktif mengelola apa yang dilihat model. Kebanyakan build agen hobi memperlakukan konteks sebagai kantong tak berdasar. Itu tidak benar.
Rancang untuk kesinambungan sesi. Snapshot, perubahan file yang dapat di-revert, CLAUDE.md sebagai jangkar persisten. Agen yang berjalan lama membutuhkan memori yang bertahan dari kompresi konteks.
Granularitas izin terbayar. Aturan per-tool, per-pola, per-direktori dengan evaluasi deny-first. Lebih banyak pekerjaan daripada flag “izinkan segalanya”, tetapi itulah perbedaan antara demo dan sistem yang dapat di-deploy.
Kapan membangun harness sendiri vs. menggunakan lapisan yang dikelola
Tugas yang sempit dan terdefinisi dengan baik — bot CI yang menjalankan tes dan memposting hasilnya — Anda dapat menyambungkan harness minimal sendiri. Beberapa tool, pemeriksaan izin sederhana, context window tetap.
Sesi yang diperpanjang, state di seluruh reset konteks, output tool yang tidak tepercaya, lusinan tool — bangun di atas harness yang sudah ada atau pelajari satu dengan saksama. Claude Agent SDK, arsitektur Codex OpenAI, LangGraph semuanya telah memecahkan masalah yang pada akhirnya akan Anda hadapi.
Sebagian besar tim meremehkan kompleksitas harness. Saya tentu saja demikian. Modelnya adalah bagian yang mudah.
FAQ
Apa itu agent harness Claude Code?
Lapisan infrastruktur antara model Claude dan dunia nyata — dispatching tool, izin, manajemen konteks, state sesi, koneksi MCP. Anthropic mendeskripsikannya sebagai apa yang “mengubah language model menjadi agen coding yang mumpuni.”
Bagaimana Claude Code menangani izin tool?
Pipeline berbasis aturan mengevaluasi setiap pemanggilan tool: allow, ask, atau deny, dengan deny selalu menang. Dalam mode auto, classifier latar belakang pada instance model terpisah mengevaluasi kasus yang ambigu — dan dengan sengaja tidak melihat output prosa agen untuk mencegah prompt injection.
Apakah integrasi MCP Claude Code siap untuk produksi?
Fungsional dan aktif digunakan, tetapi dengan batasan praktis seputar jumlah server, ukuran respons, dan kepercayaan pihak ketiga. Ini berkembang dengan cepat.
Bisakah saya membangun harness sendiri menggunakan pola yang sama?
Ya. Claude Agent SDK mengekspos mode izin, hook, dan manajemen konteks yang sama. Proyek komunitas seperti Everything Claude Code juga telah mendokumentasikan pola yang dapat digunakan kembali.
Apa perbedaan antara spec parity dan behavioral parity?
Spec parity berarti mendukung tool dan konfigurasi yang sama. Behavioral parity berarti menangani kasus edge dengan cara yang sama — kompaksi yang menghilangkan aturan kritis, tool yang mengembalikan 100K token, model yang mencoba melewati izin. Mencocokkan spesifikasi itu mudah. Mencocokkan perilaku membutuhkan berbulan-bulan.
Sesuatu yang tetap ada dalam pikiran saya: harness adalah bagian yang sulit. Semua orang berasumsi model adalah keunggulan kompetitif. Dan memang begitu — sampai Anda mencoba membuatnya melakukan sesuatu secara andal selama lebih dari lima menit. Di sanalah rekayasanya berada.
Posting sebelumnya:
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8

API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi

Harga GPT-5.4 Mini: Biaya Input, Cache & Output

API MAI-Image-2.5: Yang Perlu Diketahui Para Developer
