Gemini 3.1 Flash-Lite: Fitur, Kasus Penggunaan, dan Perbandingannya dengan Flash
Gemini 3.1 Flash-Lite adalah model inferensi berbiaya terendah dari Google. Fitur, kasus penggunaan nyata, dan perbandingan langsung dengan Gemini Flash.

Saya memperhatikan sesuatu yang ganjil ketika Google merilis Gemini 3.1 Flash-Lite pada 3 Maret. Biasanya, mereka meluncurkan model Flash yang lebih canggih terlebih dahulu — atau melewati tingkat Lite sama sekali. Kali ini, mereka langsung ke opsi yang lebih hemat. Pergeseran itu membuat saya memperhatikan.
Tersedia di WaveSpeedAI — harga per-token transparan, endpoint kompatibel OpenAI. Gemini 2.5 Pro API → · Gemini 2.5 Flash Lite API → · Buka Playground →
Saya Dora. Saya telah mengujinya selama sehari terakhir, dan yang mengejutkan saya bukan hanya kecepatannya. Melainkan bagaimana struktur harganya tiba-tiba membuat alur kerja tertentu terasa… terjangkau dengan cara yang sebelumnya tidak.

Apa Itu Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite berada di posisi terbawah dalam jajaran model terbaru Google, namun “terbawah” tidak lagi berarti seperti dulu. Menurut dokumentasi resmi Google, ini adalah model Gemini yang paling hemat biaya, dioptimalkan untuk kasus penggunaan dengan latensi rendah dan lalu lintas bervolume tinggi. Model ini bertujuan untuk menyamai performa Gemini 2.5 Flash di berbagai area kemampuan utama, sekaligus jauh lebih cepat dan murah.
Posisinya dalam jajaran Gemini 3.1
Keluarga Gemini 3 kini memiliki tiga tingkatan yang jelas. Di posisi teratas ada Gemini 3.1 Pro — andalan untuk tugas penalaran yang kompleks. Di tengah ada Gemini 3 Flash, yang memadukan kecerdasan setara Pro dengan kecepatan Flash. Dan sekarang, Flash-Lite menempati slot bervolume tinggi yang sensitif terhadap biaya.
Yang menarik adalah Flash-Lite bukan versi Flash yang dipangkas. Sebenarnya, ia didasarkan pada arsitektur Gemini 3 Pro, kemudian dioptimalkan khusus untuk throughput dan latensi. Pilihan arsitektur itu terlihat dalam benchmark — ia tidak hanya lebih cepat, tetapi juga lebih cerdas dari yang Anda harapkan untuk harganya.
Cara kerja logika tingkatan Pro / Flash / Flash-Lite
Pendekatan bertingkat ini bukan tentang fitur — ini tentang alokasi komputasi. Pro menghabiskan lebih banyak token untuk memikirkan masalah yang kompleks. Flash menyeimbangkan penalaran dengan kecepatan. Flash-Lite meminimalkan penalaran internal secara default, tetapi Anda dapat menyesuaikannya.
Bagian terakhir itu adalah hal baru. Google menambahkan apa yang mereka sebut “tingkat berpikir” — minimal, rendah, sedang, atau tinggi. Untuk tugas terjemahan sederhana, Anda atur ke minimal dan dapatkan hasil instan. Untuk sesuatu yang membutuhkan lebih banyak akurasi, Anda naikkan dan menerima latensi serta biaya yang sedikit lebih tinggi.
Saya mencoba ini dengan sekelompok tiket dukungan pelanggan. Pada pemikiran minimal, respons kembali dalam waktu kurang dari dua detik. Pada sedang, membutuhkan lima detik tetapi menangkap nuansa yang terlewat pada pemrosesan cepat. Kontrol ini terasa praktis.
Fitur Utama Gemini 3.1 Flash-Lite
Biaya inferensi ultra-rendah
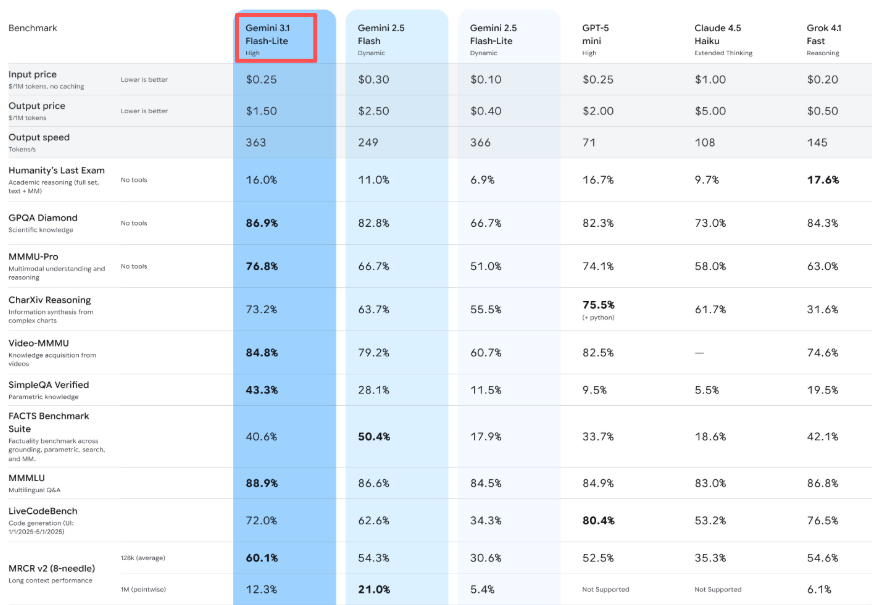
Harganya adalah $0,25 per juta token input dan $1,50 per juta token output. Sebagai perbandingan: Gemini 3.1 Pro mulai dari $2,00 per juta token input dan $18 per juta token output untuk beban kerja yang berat. Flash-Lite sekitar seperdelapan biaya Pro untuk tugas-tugas dasar.
Namun inilah yang mengejutkan saya — ia juga lebih murah dari Gemini 2.5 Flash (yang seharga $0,30/$2,50), meski lebih mumpuni. Itu tidak biasa. Biasanya Anda membayar lebih untuk peningkatan.
Throughput tinggi dan latensi rendah
Google mengklaim Flash-Lite menghasilkan output sebesar 363 token per detik, dan dalam pengujian saya, itu terasa akurat. Yang lebih penting, waktu untuk token pertama — momen Anda berhenti menunggu dan mulai melihat output — 2,5 kali lebih cepat dari Gemini 2.5 Flash, menurut benchmark internal mereka.
Saya paling merasakan ini saat membangun pipeline moderasi konten sederhana. Perbedaan antara menunggu tiga detik dan satu detik tidak terdengar signifikan. Tetapi ketika Anda memproses ratusan item, penundaan itu menumpuk. Dengan Flash-Lite, pipeline terasa responsif alih-alih lambat.
Dukungan input multimodal
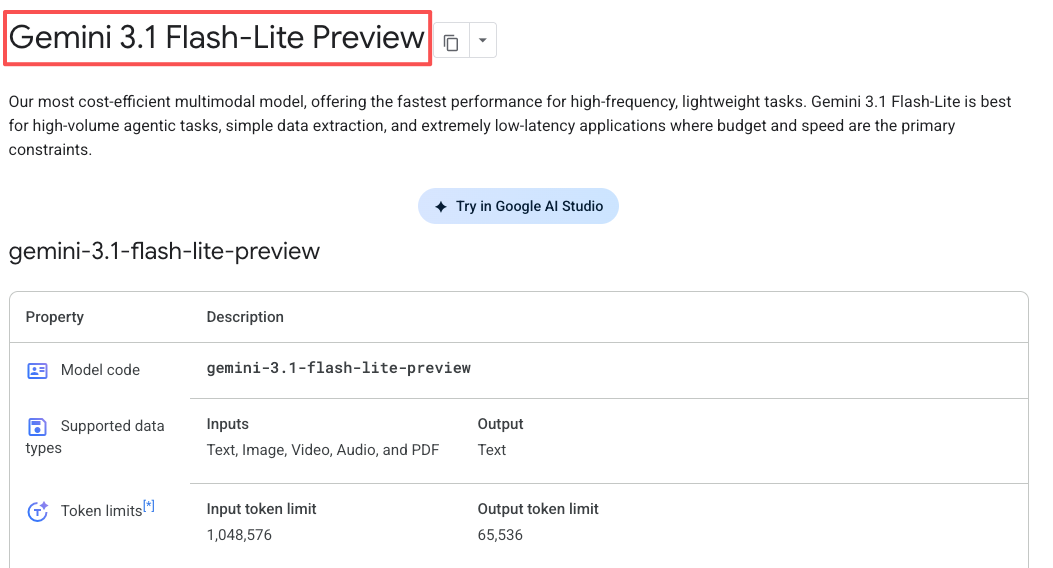
Flash-Lite menangani teks, gambar, audio, dan video. Jendela konteks mencapai 1 juta token, dan dapat menghasilkan hingga 64.000 token output teks.
Saya mengujinya dengan campuran gambar produk dan deskripsi untuk prototipe e-commerce. Model ini memberi tag secara konsisten dan cepat — pengguna awal seperti Whering melaporkan konsistensi 100% dalam pemberian tag item untuk kategori fashion yang kompleks. Keandalan semacam itu penting ketika Anda membangun sistem yang tidak boleh melenceng.
Jendela konteks panjang
Jendela konteks 1 juta token berarti Anda dapat memasukkan seluruh dokumen, rangkaian percakapan panjang, atau kumpulan data besar tanpa perlu memecahnya menjadi bagian-bagian yang lebih kecil terlebih dahulu. Saya tidak sering menggunakan jendela penuh, tetapi ketika saya melakukannya — seperti saat menganalisis PDF multi-halaman — itu menjadi perbedaan antara alur kerja yang lancar dan yang menyebalkan.
Gemini 3.1 Flash-Lite vs Flash: Perbandingan Langsung
Kapan menggunakan Flash-Lite
Gunakan Flash-Lite ketika Anda menjalankan ribuan atau jutaan tugas serupa. Pipeline terjemahan, antrean moderasi konten, analisis sentimen dalam skala besar, ekstraksi data dasar — apa pun di mana tugasnya terdefinisi dengan baik dan biaya per token lebih penting daripada penalaran mendalam.
Saya juga menemukan bahwa model ini bekerja dengan baik sebagai router. Anda dapat menggunakan Flash-Lite untuk mengklasifikasikan permintaan masuk sebagai “sederhana” atau “kompleks,” lalu merutekan yang kompleks ke Flash atau Pro. Ini menghemat biaya tanpa mengorbankan kualitas di tempat yang penting.
Kapan menggunakan Flash sebagai gantinya
Jika tugas memerlukan penalaran multi-langkah, pemecahan masalah kreatif, atau menangani instruksi yang ambigu, Flash adalah pilihan yang lebih baik. Harganya dua kali lipat, tetapi juga lebih cerdas — terutama untuk tugas coding, di mana ia menyamai atau melampaui Pro pada beberapa benchmark.
Saya menguji keduanya pada tugas yang melibatkan pembuatan komponen UI dari prompt bahasa alami. Flash-Lite dapat menangani permintaan langsung (“buat formulir login”), tetapi kesulitan dengan yang samar (“rancang sesuatu yang modern dan bersih”). Flash menangani keduanya.
Kasus Penggunaan Gemini 3.1 Flash-Lite
Perutean agen AI dan klasifikasi tugas
Salah satu kasus penggunaan terbersih yang saya lihat adalah menggunakan Flash-Lite sebagai pengontrol lalu lintas. Ketika pengguna mengirimkan permintaan, Flash-Lite membacanya, menentukan kompleksitasnya, dan merutekannya ke model yang sesuai — Flash untuk tugas menengah, Pro untuk yang berat.
Pola ini sudah digunakan dalam alat produksi. Gemini CLI open-source menggunakan Flash-Lite untuk persis ini, dan berhasil karena model ini cukup cepat dan murah untuk menambahkan langkah perutean tersebut tanpa meningkatkan latensi atau biaya secara nyata.
Chat bervolume tinggi dan otomasi dukungan
Dukungan pelanggan adalah tempat di mana penghematan biaya benar-benar terlihat. Jika Anda menangani puluhan ribu tiket dukungan setiap hari, perbedaan antara $0,25 dan $2,00 per juta token input berkembang dengan cepat.
Flash-Lite dapat menangani pertanyaan langsung, mengekstrak maksud, dan merutekan tiket yang membutuhkan perhatian manusia. Ia tidak akan memecahkan masalah teknis yang kompleks, tetapi memang tidak perlu. Ia hanya perlu andal dan cepat.
Moderasi konten dan pemberian tag
Saya membangun pipeline pengujian cepat untuk memoderasi konten yang dibuat pengguna — menandai spam, bahasa yang tidak pantas, dan posting di luar topik. Flash-Lite memproses sekitar 500 item dalam waktu kurang dari satu menit, dengan akurasi yang konsisten.
Kuncinya di sini adalah konsistensi. Beberapa model menyimpang seiring waktu atau memberikan jawaban berbeda untuk input yang serupa. Flash-Lite tetap dapat diprediksi di seluruh pengujian berulang, yang penting ketika Anda membangun sistem yang perlu berperilaku sama setiap saat.
Pipeline pra-pemrosesan dokumen
Flash-Lite unggul dalam ekstraksi data terstruktur. Diberikan sekumpulan faktur atau tanda terima, ia dapat menarik bidang-bidang kunci — tanggal, jumlah, nama vendor — dan mengeluarkannya sebagai JSON.
Saya menguji ini dengan campuran faktur PDF, dan model ini menangani sebagian besar dengan bersih. Yang kesulitan adalah pemindaian berkualitas rendah dengan teks yang buruk, tetapi itu adalah keterbatasan input, bukan model.
Apa Arti Flash-Lite bagi Desain Infrastruktur AI

Pola arsitektur model bertingkat
Perilisan Flash-Lite melengkapi apa yang mulai terasa seperti pola standar industri: tumpukan model tiga tingkat. Anda memiliki model berat untuk masalah yang sulit, opsi seimbang untuk penggunaan sehari-hari, dan model ringan untuk pekerjaan berulang bervolume tinggi.
Ini bukan hal baru — OpenAI memiliki GPT-5 / GPT-5 mini, Anthropic memiliki Claude Opus / Sonnet / Haiku — tetapi implementasi Google menarik karena kesenjangan harganya lebih lebar. Flash-Lite benar-benar murah dibandingkan Pro, yang membuat alur kerja tertentu menjadi layak secara ekonomi yang sebelumnya tidak.
Router murah + pemikir kuat — mengapa ini penting
Pola yang terus saya lihat adalah: gunakan model murah untuk menentukan jenis tugas yang Anda hadapi, lalu rutekan ke model yang lebih mahal hanya bila diperlukan. Ini bukan hanya tentang menghemat uang. Ini juga meningkatkan latensi untuk tugas sederhana, karena Anda tidak menunggu model berat untuk berputar.
Saya mencoba ini dengan batch campuran 100 tugas — setengah sederhana, setengah kompleks. Menggunakan Flash-Lite sebagai router, tugas-tugas sederhana selesai dalam hitungan detik, dan yang kompleks diarahkan ke Flash. Total biaya sekitar 40% lebih rendah daripada menjalankan semuanya melalui Flash, tanpa kehilangan kualitas pada tugas-tugas kompleks.
Arsitektur ini hanya berfungsi jika router cukup cepat dan murah sehingga tidak menjadi bottleneck. Flash-Lite memenuhi syarat itu.
Ketersediaan Saat Ini dan Status API
Gemini 3.1 Flash-Lite tersedia sekarang dalam preview melalui Gemini API di Google AI Studio dan Vertex AI. Model ini tidak ada di aplikasi Gemini untuk konsumen — ini berfokus pada pengembang.
Model preview dapat berubah sebelum menjadi stabil, dan memiliki batas laju yang lebih ketat. Dalam praktiknya, saya belum mencapai batas tersebut dalam pengujian normal, tetapi jika Anda merencanakan penerapan produksi dalam skala serius, itu adalah sesuatu yang perlu diperhatikan.
Model ini juga sedang diperbarui secara aktif. Catatan rilis Google menunjukkan peningkatan berkelanjutan pada mengikuti instruksi, kualitas input audio, dan kemampuan penalaran. Ini masih tahap awal — kemungkinan akan semakin baik dalam beberapa bulan ke depan.
Sebuah Pemikiran yang Tersisa
Yang terus saya pikirkan bukan kecepatan atau biayanya. Melainkan fakta bahwa Flash-Lite membuat alur kerja tertentu terasa lebih seperti utilitas daripada eksperimen. Ketika biaya turun cukup rendah, Anda berhenti bertanya “haruskah saya menggunakan AI untuk ini?” dan mulai bertanya “bagaimana saya membangun ini agar bisa diskalakan?”
Pergeseran itu — dari kebaruan menjadi infrastruktur — adalah saat alat mulai bertahan lama.
Artikel Terkait

Claude Fable 5 Telah Dirilis: 80,3% di SWE-Bench Pro, Harga 2× Opus 4.8, Gratis Hingga 22 Juni

Cara Memilih API Media AI untuk Aplikasi Codex (2026)

Hunyuan 3D API: Yang Perlu Diketahui para Developer

Hunyuan 3D vs Hyper3D vs Pixal3D

Membangun Aplikasi Video AI dengan Coding Agent
