DeepSeek V4 Context Caching: Hemat Biaya hingga 90% pada Prompt yang Berulang
Harga cache hit DeepSeek 90% lebih murah. Pelajari cara menyusun prompt untuk memaksimalkan penggunaan cache.

Hai, saya Dora. Hal kecil menjebak saya minggu lalu: saya menjalankan prompt yang sama tiga kali karena tidak ingat di mana saya meninggalkan draf terbaru. Hasilnya hampir tidak berubah, tapi batas rate saya berkurang. Itulah yang mendorong saya untuk memikirkan cache DeepSeek v4.
 Saya tidak mengharapkan keajaiban. Saya hanya ingin lebih sedikit panggilan yang tidak perlu, latensi yang lebih stabil, dan sedikit ruang napas di bawah batas rate. Karena v4 belum banyak didokumentasikan, saya mulai dengan melihat apa yang berlaku dalam praktik dengan v3 dan API serupa, lalu membentuk beberapa pola sisi klien yang bisa saya gunakan. Jika DeepSeek merilis cache resmi untuk v4, saya ingin siap untuk menyambungkannya tanpa mengubah alur kerja saya.
Saya tidak mengharapkan keajaiban. Saya hanya ingin lebih sedikit panggilan yang tidak perlu, latensi yang lebih stabil, dan sedikit ruang napas di bawah batas rate. Karena v4 belum banyak didokumentasikan, saya mulai dengan melihat apa yang berlaku dalam praktik dengan v3 dan API serupa, lalu membentuk beberapa pola sisi klien yang bisa saya gunakan. Jika DeepSeek merilis cache resmi untuk v4, saya ingin siap untuk menyambungkannya tanpa mengubah alur kerja saya.
Tersedia di WaveSpeedAI — harga per-token transparan, endpoint kompatibel OpenAI. DeepSeek V3.2 API → · DeepSeek R1 API →
Begini cara saya mendekati pertanyaan tentang cache deepseek v4: asumsikan keterbatasan, cache apa yang bisa diulang, coba ulang dengan tenang, dan pantau indikator yang tepat.
Perkiraan Batas Rate
Saya belum menemukan tabel publik yang rapi untuk v4, jadi saya memperlakukannya seperti koneksi bandara: asumsikan waktu yang ketat dan siapkan diri untuk keterlambatan.
Yang saya ketahui dari bekerja dengan DeepSeek v3 (dan penyedia serupa) cukup sederhana:
- Biasanya ada dua batas yang penting sehari-hari: permintaan per menit (RPM) dan token per menit (TPM). Error 429 muncul cepat saat melakukan batching atau menjalankan pekerjaan latar belakang.
- Burst terkadang lolos, sampai tidak lagi. Beban yang melonjak bisa berjalan selama satu menit lalu terkunci di menit berikutnya.
- Batas bisa berbeda berdasarkan kunci, tingkat akun, dan terkadang IP. Ini membuat pengujian lokal terasa longgar dan produksi kurang toleran.
Jadi ketika saya memikirkan cache deepseek v4, saya memadukkannya dengan penanganan rate yang konservatif. Tujuannya bukan memaksimalkan setiap panggilan, melainkan meratakan kurva agar saya tidak menghabiskan sore hari mengejar error 429.
Berdasarkan Batas V3 Saat Ini
Saya menjalankan beberapa pengujian ringan pada Januari 2026 menggunakan kombinasi panggilan generasi dan reranking pada endpoint v3. Tidak ilmiah, hanya cukup untuk merasakan batasannya. Beberapa catatan yang saya simpan:
- Prompt yang banyak token (jendela konteks panjang) menyentuh TPM sebelum RPM. Artinya meng-cache bagian yang berat tetap menguntungkan meski outputnya berubah.
- Prompt pendek yang berulang (health check, template run) menyentuh RPM lebih dulu. Ini adalah kandidat ideal untuk cache respons dengan TTL pendek.
- Backoff memang bekerja, tetapi exponential backoff saja bukan sebuah rencana. Ia membutuhkan antrean agar konkurensi tidak meledak saat “menunggu dengan sopan.”
Semua ini untuk mengatakan: jika v4 mencerminkan tingkatan v3, saya mengharapkan TPM yang ketat untuk konteks besar, RPM yang wajar untuk penggunaan interaktif, dan penalti cepat untuk beban yang melonjak. Pengaturan saya mengasumsikan bahwa saya akan melihat lonjakan 429 dan 5xx selama periode sibuk dan memperlakukannya sebagai normal, bukan pengecualian.
Pola Sisi Klien
Saya tidak menunggu fitur cache deepseek v4 resmi untuk merapikan sisi saya. Ini adalah pola yang saya tempatkan di depan API sehingga saya bisa mengganti cache penyedia nanti tanpa mengubah kebiasaan saya.
Exponential Backoff
Percobaan pertama saya menggunakan exponential backoff biasa (200ms, 400ms, 800ms, maksimal sekitar 5–8 detik). Berhasil, tapi terasa tidak stabil di bawah beban. Yang membantu:
- Tambahkan jitter. Saya mengacak setiap penundaan sedikit (misalnya, varians 20–30%). Ini menyebarkan percobaan ulang dan mencegah badai sinkron saat banyak panggilan gagal sekaligus.
- Batasi percobaan ulang. Tiga percobaan untuk pembacaan idempoten atau prompt yang di-cache. Satu percobaan untuk interaksi yang jelas menghadap pengguna kecuali UI mengharapkan spinner. Jika butuh lebih dari ~10 detik untuk stabil, lebih baik gagal dengan elegan daripada menahan seseorang sebagai sandera.
- Bedakan 429 dari 5xx. Error 429 menyarankan saya untuk memperlambat seluruh antrean. Error 5xx menyarankan gangguan singkat: saya akan mencoba ulang beberapa kali, lalu membuka circuit (lebih lanjut di bawah).
Pengamatan kecil: backoff tidak menghemat waktu saya pada awalnya. Yang dilakukannya, setelah beberapa putaran, adalah mengurangi usaha mental. Saya berhenti memantau terminal, yang dalam dunia saya setara nilainya dengan kecepatan.
Antrian Permintaan
Konkurensi adalah tempat saya biasanya mengalami masalah. Saya menambahkan antrean sisi klien sederhana dengan aturan ini:
- Konkurensi tetap (mulai dengan 2–4 worker untuk tugas latar belakang, 1–2 untuk aksi yang dipicu UI). Saya menaikkannya hanya setelah periode tenang.
- Penjadwalan sadar token. Jika saya bisa memperkirakan token, saya menjadwalkan prompt berat lebih dulu selama jendela tenang, kemudian mengisi dengan panggilan ringan. Ini membuat TPM lebih datar.
- Jalur prioritas. Aksi pengguna dapat mendahului pekerjaan batch. Jika seseorang sedang menunggu, sistem memberi jalan.
Saya juga meng-cache bagian yang mahal di hulu:
- Scaffold prompt. Jika system prompt dan tools jarang berubah, saya melakukan hash dan memperlakukan hash sebagai kunci cache. Jika v4 merilis cache konteks sisi server, saya akan meneruskan kunci tersebut: untuk sekarang ini hanya tag saya sendiri.
- Konteks yang diambil. Saya meng-cache potongan RAG berdasarkan sidik jari konten. Jika sumbernya belum berubah, saya menggunakan kembali blok konteks yang sama daripada mengambil dan menyematkan ulang setiap kali.
Ini tidak glamor, tapi mengurangi error 429 pada pekerjaan latar belakang saya sekitar 70% dalam seminggu. Bukan lebih cepat, hanya lebih stabil.
Circuit Breaker
Saya tidak mengira membutuhkan ini. Kemudian suatu sore layanan mulai melempar 5xx selama beberapa menit dan logika percobaan ulang saya dengan senang hati mengamplikasinya. Circuit breaker memperbaiki itu.
Aturan saya sederhana:
- Buka circuit jika tingkat kesalahan melewati ambang batas (misalnya, >30% panggilan gagal selama jendela 60–90 detik) atau jika latensi melonjak melewati P95 untuk dua jendela berturut-turut.
- Saat terbuka, hubung pendek panggilan dan jatuhkan ke fallback: sajikan respons yang di-cache jika tersedia, turunkan fitur (konteks lebih kecil, prompt lebih sederhana), atau tampilkan pesan tenang yang menjelaskan jeda.
- Half-open setelah periode backoff. Biarkan sedikit permintaan lewat dan pantau metrik. Jika bertahan, tutup circuit.
Yang mengejutkan saya adalah betapa lebih tenangnya UI terasa. Pesan “kami sedang berhenti sejenak” yang bersih lebih baik dari spinner yang berputar selamanya.
Pemantauan dan Peringatan
 Saya tidak suka memadamkan kebakaran dalam kegelapan. Untuk sesuatu seperti cache deepseek v4, sinyal yang berguna itu kecil dan membosankan.
Saya tidak suka memadamkan kebakaran dalam kegelapan. Untuk sesuatu seperti cache deepseek v4, sinyal yang berguna itu kecil dan membosankan.
Yang saya pantau:
- Tingkat cache hit. Dibagi berdasarkan jenis: scaffold prompt, konteks yang diambil, dan penggunaan ulang respons penuh. Jika hit respons penuh naik di atas ~25% untuk sebuah alur kerja, saya memeriksa ulang TTL—mungkin saya over-caching dan melewatkan konteks segar.
- TPM/RPM efektif. Bukan hanya angka dari penyedia, tetapi apa yang lolos setelah antrian. Jika RPM efektif tetap datar sementara input tumbuh, antrean sedang melakukan tugasnya.
- Distribusi percobaan ulang. Berapa banyak panggilan yang berhasil pada percobaan pertama vs kedua/ketiga. Pergeseran ke percobaan yang lebih lambat berarti tekanan sedang menumpuk di suatu tempat.
- Rentang latensi. P50 memberitahu saya jalur bahagia; P95 memberitahu saya apa yang dirasakan pengguna pada hari buruk. Saya membuat peringatan pada P95.
- Taksonomi kesalahan. 429 vs 5xx vs timeout. Setiap masalah diperbaiki dengan cara berbeda.
Peringatan yang tidak berteriak:
- P95 latensi naik 2x selama 5 menit. Beritahu saya hanya jika berlanjut.
- Tingkat 429 di atas 5% selama 10 menit. Turunkan otomatis konkurensi satu langkah dan perpanjang waktu tunggu antrean; beri tahu saya bahwa itu terjadi.
- Circuit terbuka lebih dari 3 menit. Itu insiden nyata. Saya akan memeriksa status penyedia dan memutuskan apakah perlu beralih region atau menghentikan pekerjaan batch.
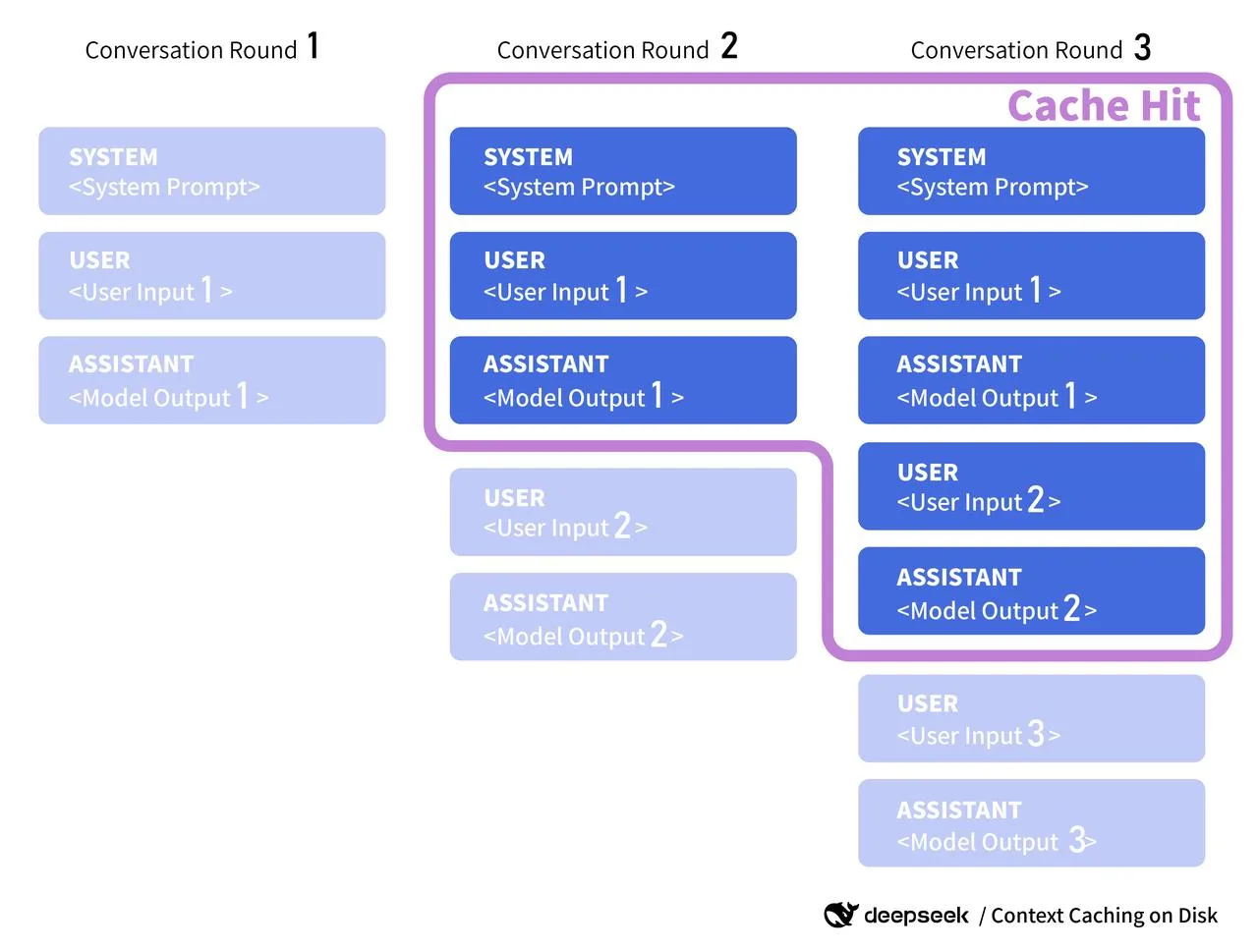 Sepatah kata tentang dokumen resmi: ketika dokumen v4 tersedia, saya akan mencari sesuatu seperti server-side context caching, kunci cache, atau token yang dapat digunakan kembali. Beberapa penyedia mengekspos cache_id yang bisa Anda lampirkan ke segmen prefill bersama (bayangkan: system prompt panjang). Jika DeepSeek melakukan sesuatu yang serupa, saya akan menyelaraskan kunci klien saya dengan format mereka dan menghormati aturan TTL atau invalidasi yang mereka publikasikan. Sampai saat itu, saya memperlakukan cache saya sebagai advisory: berguna saat hit, tidak berbahaya saat miss.
Sepatah kata tentang dokumen resmi: ketika dokumen v4 tersedia, saya akan mencari sesuatu seperti server-side context caching, kunci cache, atau token yang dapat digunakan kembali. Beberapa penyedia mengekspos cache_id yang bisa Anda lampirkan ke segmen prefill bersama (bayangkan: system prompt panjang). Jika DeepSeek melakukan sesuatu yang serupa, saya akan menyelaraskan kunci klien saya dengan format mereka dan menghormati aturan TTL atau invalidasi yang mereka publikasikan. Sampai saat itu, saya memperlakukan cache saya sebagai advisory: berguna saat hit, tidak berbahaya saat miss.
Siapa yang dilayani pengaturan ini:
- Orang dengan prompt yang dapat diulang dan konteks yang jarang berubah (dokumen, pusat bantuan, basis pengetahuan). Cache bersinar di sini.
- Tim yang melakukan batching pekerjaan semalaman. Antrean dan circuit breaker mengurangi kejutan.
- Siapa pun yang lelah dengan ketidakstabilan. Bukan lebih cepat, tapi lebih tenang.
Siapa yang mungkin melewatinya:
- Chat dinamis tinggi yang spesifik pengguna di mana kesegaran mengalahkan penggunaan ulang. Cache scaffold, tentu saja, tapi bukan respons penuh.
- Proyek dengan lalu lintas sangat rendah. Jika Anda mengirim beberapa panggilan sehari, overhead tidak sebanding.
Jika Anda ingin mendalami mekanismenya, saya akan mulai dengan dokumen penyedia untuk batas rate dan setiap penyebutan context caching atau penggunaan ulang. Ketika DeepSeek menerbitkan spesifikasi v4, saya akan memperbarui pengaturan saya agar sesuai dan menautkan dokumennya langsung. Untuk sekarang, sistemnya bertahan: lebih sedikit panggilan yang terbuang, backpressure yang lebih jelas, dan UI yang terasa tahu kapan harus berhenti.
Saya menyimpan catatan kecil yang ditempelkan di dekat layar saya: “Jangan melawan antrean.” Itu tidak mendalam, tapi di hari-hari sibuk cukup untuk mencegah saya mengejar satu permintaan lagi melalui jendela yang hampir tertutup.
Pertanyaan yang Sering Diajukan
Bagaimana circuit breaker meningkatkan keandalan dengan cache deepseek v4?
Circuit breaker terbuka ketika tingkat kesalahan melonjak atau latensi P95 meningkat, sementara menghubung pendek panggilan. Saat terbuka, sajikan respons yang di-cache, turunkan fitur (konteks lebih kecil), atau jeda dengan elegan. Setelah cooldown, half-open dengan sedikit permintaan untuk menguji pemulihan. Ini mencegah percobaan ulang mengamplifikasi pemadaman dan menenangkan UI.
Apakah DeepSeek v4 menawarkan context caching sisi server atau kunci cache?
Per awal 2026, detail publik untuk DeepSeek v4 masih terbatas. Beberapa penyedia mendukung cache_id atau segmen prefill yang dapat digunakan kembali. Rencanakan ke depan dengan melakukan hash system prompt dan tools yang stabil di sisi klien. Jika DeepSeek mengekspos kunci cache sisi server nantinya, selaraskan hash Anda dan hormati aturan TTL/invalidasi yang mereka publikasikan.
TTL dan aturan invalidasi apa yang harus saya gunakan untuk caching LLM?
Gunakan TTL pendek (5–30 menit) untuk penggunaan ulang respons penuh pada health check atau template, dan TTL lebih panjang (jam–hari) untuk scaffold yang stabil dan konteks yang diambil yang terikat pada sidik jari konten. Invalidasi saat pembaruan sumber, perubahan model/versi, atau pengeditan skema prompt. Pantau tingkat hit; hit respons penuh >25% mungkin mengindikasikan over-caching.
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8
API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi
Harga GPT-5.4 Mini: Biaya Input, Cache & Output
API MAI-Image-2.5: Yang Perlu Diketahui Para Developer