Pengkabelan Alat pada Agentic Workflow: Pola dan Jebakan
Sedang membangun alur kerja agentik? Mode kegagalan jarang berasal dari model. Inilah bagaimana pengkabelan alat, izin, dan orkestrasi benar-benar rusak di lingkungan produksi.

Saya menghitung jam minggu lalu. Dalam sprint lima hari menyambungkan pipeline agentik — tujuh alat, tiga API eksternal, sandbox kode, satu lapisan otomasi browser — saya menghabiskan sekitar 14 jam untuk debugging. Sebelas di antaranya untuk penyambungan. Bukan modelnya. Bukan prompt-nya. Ruang antara model yang memutuskan untuk memanggil alat dan alat itu benar-benar melakukan hal yang tepat.
Tersedia di WaveSpeedAI — harga per-token transparan, endpoint kompatibel OpenAI. Lihat semua LLM → · Buka Playground →
Seseorang di Slack tim kami bertanya, “Dora, bukankah bagian yang sulitnya seharusnya adalah rekayasa prompt?” Memang begitu, sekitar delapan bulan lalu. Sekarang prompt-nya hanya butuh satu sore. Membuat pengiriman alat, pelingkupan autentikasi, dan pemulihan kegagalan berperilaku benar di bawah beban nyata memakan sisa minggu tersebut.
Jika Anda berada di tahap di mana sistem agentik Anda bekerja dalam demo tetapi rusak di produksi — alat yang habis waktu secara diam-diam, loop percobaan ulang yang menguras anggaran token, kesalahan izin yang tidak bisa diinterpretasikan model — itulah tahap di mana penyambungan menjadi masalah rekayasa yang sebenarnya. Tulisan ini mendokumentasikan pola dan mode kegagalan yang saya temui di lapisan tersebut, serta keputusan desain yang menentukan apakah sistem saya pulih atau semakin kacau.
Mengapa Penyambungan Alat Adalah Bagian yang Sulit
Model jarang menjadi hambatan. Sebagian besar kegagalan produksi yang saya lacak tidak berasal dari penalaran LLM. Kegagalan tersebut berasal dari apa yang terjadi setelah model memutuskan untuk memanggil alat — pengiriman, handshake autentikasi, penguraian respons, penanganan kesalahan. Panduan rekayasa Anthropic sendiri tentang membangun agen yang efektif menyatakan hal ini dengan jelas: LLM yang diperlengkapi hanyalah sebuah blok bangunan. Kerja kerasnya ada di segala sesuatu di sekelilingnya.
Apa yang dimaksud “penyambungan” dalam sistem agentik. Penyambungan alat bukan sekadar “sambungkan ke API.” Ini mencakup permukaan penuh: bagaimana alat ditemukan, bagaimana alat-alat tersebut dideskripsikan ke model, bagaimana izin dilingkupi per alat, bagaimana respons divalidasi sebelum dimasukkan kembali ke jendela konteks, dan bagaimana kegagalan di titik mana pun ditangani tanpa merusak sesi. Spesifikasi Model Context Protocol dirancang khusus untuk menstandarisasi lapisan ini — penemuan alat, pemanggilan, dan pemformatan hasil — karena setiap tim sedang menciptakan ulang hal tersebut.
Kesalahpahaman umum dari demo ke produksi. Dalam demo, Anda menyambungkan tiga alat, model memanggilnya dengan benar, dan terasa seperti keajaiban. Dalam produksi, Anda menemukan bahwa deskripsi alat bersaing untuk mendapatkan perhatian ketika Anda memiliki lima belas di antaranya. Bahwa skema parameter perlu sangat presisi atau model akan menghalu argumen. Bahwa “happy path” yang didemonstrasikan dalam prototipe Anda hanya mencakup sekitar 40% pemanggilan nyata. Postingan terbaru Anthropic tentang menulis alat yang efektif untuk agen menemukan bahwa bahkan perubahan halus pada deskripsi alat — seperti apakah Claude menambahkan “2025” ke kueri pencarian — dapat menurunkan kinerja secara signifikan. Desain antarmuka sama pentingnya dengan model.
Pola Inti dalam Orkestrasi Alat Produksi
Permukaan alat statis vs. dinamis. Permukaan alat statis berarti model melihat kumpulan alat yang sama untuk setiap pemanggilan. Sederhana, dapat diprediksi, mudah diuji. Permukaan dinamis berarti alat dimuat, disaring, atau dibuat berdasarkan konteks sesi — peran pengguna, langkah alur kerja saat ini, apa yang sudah dipanggil. Permukaan dinamis lebih fleksibel tetapi jauh lebih sulit di-debug. Saya menjalankan gabungan: kumpulan inti yang tetap ditambah alat kondisional yang dikunci berdasarkan status alur kerja.
Pengiriman alat sekuensial vs. paralel. Pengiriman sekuensial sangat mudah — panggil alat A, urai hasil, panggil alat B. Sebagian besar sistem agentik awal bekerja dengan cara ini. Pengiriman paralel, di mana model meminta beberapa pemanggilan alat secara bersamaan, mengurangi latensi tetapi memperkenalkan kompleksitas koordinasi. Kerangka orkestrasi LangGraph mendukung kedua pola melalui manajemen status berbasis grafnya, dan perbedaan latensi di dunia nyata sangat signifikan — saya mengukur percepatan 3-4x pada operasi batch. Tetapi pengiriman paralel juga berarti Anda perlu menangani kegagalan parsial: apa yang terjadi ketika alat A berhasil dan alat B habis waktu?
Pembatasan izin per jenis alat. Tidak semua alat membawa risiko yang sama. Kueri database hanya-baca pada dasarnya berbeda dari alat yang dapat menghapus file atau mengirim email. Saya mengkategorikan alat ke dalam tiga tingkat: hanya-baca (disetujui otomatis), tulis dengan rollback (dicatat, disetujui otomatis dengan audit), dan destruktif/eksternal (memerlukan konfirmasi eksplisit). Tim Red AI NVIDIA menerbitkan panduan sandboxing praktis yang merumuskan ini dengan baik: kontrol wajib adalah pembatasan egress jaringan dan pemblokiran penulisan file di luar workspace. Segalanya adalah sekunder.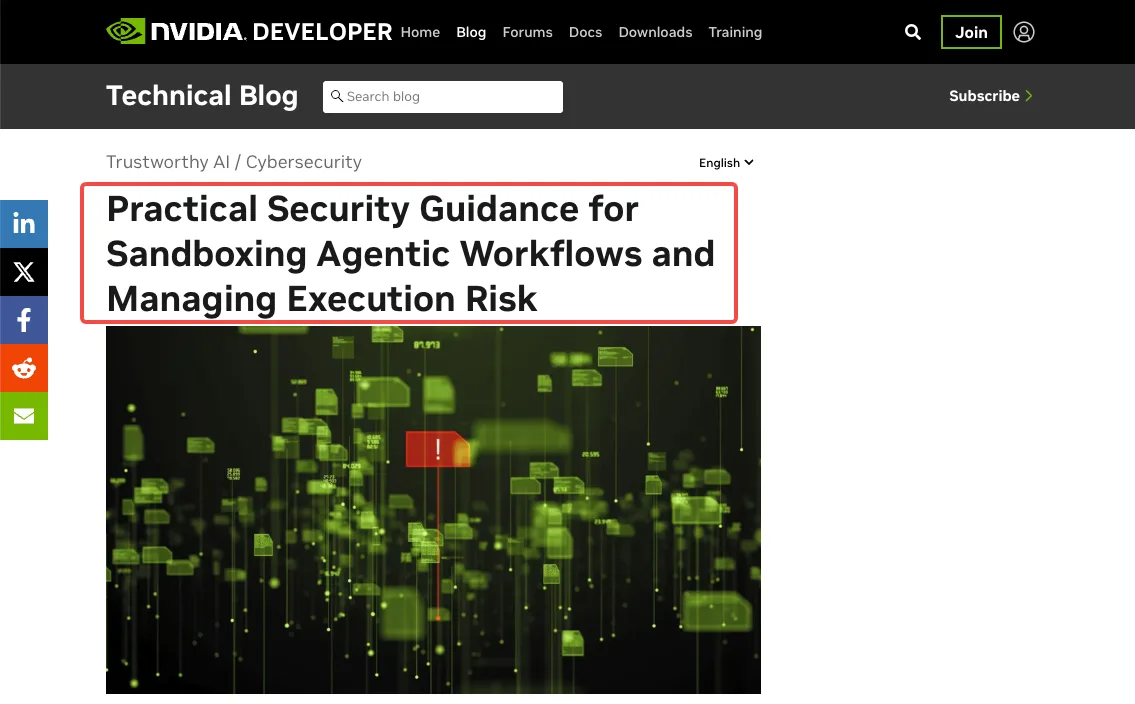
Strategi sandboxing dan isolasi. Jika agen Anda mengeksekusi kode, agen tersebut memerlukan sandbox. Bukan container Docker — container berbagi kernel host dan tidak cukup terisolasi untuk kode yang dibuat LLM yang tidak terpercaya. Opsi produksi adalah microVM (Firecracker, Kata Containers), gVisor untuk intersepsi syscall, atau container yang diperkuat khusus untuk kode hanya-terpercaya. Saya menjalankan gVisor untuk sebagian besar eksekusi alat. Overhead-nya dapat diterima. Alternatifnya — menemukan bahwa perintah bash yang dibuat LLM menjalankan rm -rf pada volume yang di-mount — tidak dapat diterima.
Mode Kegagalan yang Perlu Diantisipasi
Loop pemanggilan alat dan delegasi tak terbatas. Pola kegagalan paling mahal. Model memanggil alat, mendapat kesalahan, mencoba ulang pemanggilan yang sama dengan parameter identik, mendapat kesalahan yang sama, mencoba ulang lagi. Tanpa anggaran percobaan ulang yang dibatasi, ini berlanjut hingga Anda mencapai batas token atau ambang penagihan API. Saya telah melihat ini terjadi terutama dengan kegagalan autentikasi — model terus mencoba sesuatu yang tidak akan pernah berhasil. Jumlah percobaan ulang yang dibatasi 2-3 kali dengan klasifikasi kesalahan yang dapat dicoba ulang vs. yang tidak dapat dicoba ulang adalah minimum.
Pemotongan output yang merusak langkah-langkah berikutnya. Respons alat yang melebihi jendela konteks akan dipotong secara diam-diam. Model kemudian bernalar berdasarkan data yang tidak lengkap tanpa mengetahui bahwa datanya tidak lengkap. Ini sangat buruk dengan kueri database yang mengembalikan set hasil yang besar. Sekarang saya memberlakukan batas token keras pada setiap respons alat — maksimal 25.000 token — dengan sinyal paginasi eksplisit ketika hasil dipotong.
Kedaluwarsa autentikasi di tengah sesi. Sesi agentik yang berjalan lama dapat melampaui masa hidup token OAuth. Alat bekerja dengan baik di menit pertama. Di menit keempat puluh tujuh, token kedaluwarsa, dan setiap pemanggilan alat berikutnya gagal. Model tidak mengerti mengapa. Saya tidak yakin ada solusi yang elegan di sini — pendekatan saya saat ini adalah memeriksa kedaluwarsa token sebelum pengiriman dan memperbarui secara proaktif.
Perintah destruktif tanpa pengaman. Model dengan akses ke eksekusi shell atau alat sistem file dapat dan sesekali akan membuat perintah destruktif. Bukan dengan niat jahat — hanya salah. Panduan preskriptif AWS tentang agen orkestrasi alur kerja merekomendasikan melacak status eksekusi per agen pekerja dan mengimplementasikan gerbang persetujuan untuk apa pun yang memengaruhi sistem produksi. Saya setuju. Alat apa pun yang dapat menulis, menghapus, atau mengirim harus memiliki langkah konfirmasi eksplisit.
Kaskade batas kecepatan di seluruh pemanggilan alat. Ketika satu alat mencapai batas kecepatan, model sering mencoba memanggilnya lagi segera. Atau memanggil alat berbeda yang mencapai API yang mendasarinya sama. Efek kaskade dapat menjenuhkan batas kecepatan Anda di semua alat dalam hitungan detik. Backoff eksponensial dengan jitter per endpoint alat adalah garis dasar — bukan per-model, per-alat.
Pola Pemulihan dan Ketahanan
Logika percobaan ulang dengan backoff eksponensial. Mulai dari 1 detik, gandakan setiap percobaan ulang, batasi di 60 detik, tambahkan jitter acak. Ini bukan opsional. Tanpa jitter, sesi paralel mencoba ulang secara bersamaan dan menciptakan efek thundering herd. Klasifikasikan kesalahan terlebih dahulu: batas kecepatan dan kesalahan 5xx akan dicoba ulang. Kegagalan autentikasi dan kesalahan validasi tidak — tidak ada jumlah percobaan ulang yang dapat memperbaiki kunci API yang salah. Dua hingga tiga percobaan ulang untuk kesalahan sementara. Nol untuk yang tidak dapat dicoba ulang.
Strategi checkpoint dan compaction. Agen yang berjalan lama yang bekerja di beberapa jendela konteks memerlukan cara untuk mempertahankan kemajuan. Tim rekayasa Anthropic mendokumentasikan ini dalam pekerjaan mereka tentang harness yang efektif untuk agen yang berjalan lama — wawasan kuncinya adalah menggunakan file kemajuan di samping riwayat git sehingga jendela konteks baru dapat dengan cepat merekonstruksi apa yang sudah selesai. Saya mengadaptasi pola serupa: sebelum compaction, agen menulis checkpoint terstruktur yang merangkum langkah-langkah yang selesai, langkah-langkah yang tertunda, dan kegagalan yang diketahui. Jendela konteks berikutnya dimulai dengan membaca file tersebut alih-alih menebak.
Degradasi yang anggun ketika alat tidak tersedia. Jika konektor database Anda mati, agen tidak boleh crash. Agen harus mengenali kegagalan, melewati langkah tersebut, dan melanjutkan dengan apa yang bisa dilakukan — atau memberi tahu pengguna apa yang tidak bisa diselesaikan. Ini memerlukan desain permukaan alat Anda sehingga tidak ada alat tunggal yang menjadi ketergantungan keras untuk seluruh alur kerja. Rantai fallback membantu: alat utama gagal, alternatif yang lebih murah atau lebih sederhana berjalan. Instruksi model harus secara eksplisit mencakup apa yang harus dilakukan ketika alat tidak mengembalikan data.
Mengevaluasi Infrastruktur Agentik
Bangun vs. beli: kapan harus membuat harness sendiri. Jika alur kerja Anda adalah rantai linier 3-4 alat dengan input yang dapat diprediksi, harness khusus membutuhkan sehari untuk dibangun dan lebih mudah dipelihara daripada kerangka kerja. Jika Anda memerlukan perutean dinamis, pengiriman paralel, persistensi status di seluruh sesi, dan checkpoint human-in-the-loop, membangun dari awal akan membutuhkan berbulan-bulan. Itulah saat kerangka kerja seperti LangGraph atau platform terkelola mendapatkan tempatnya. Saya mulai dengan kustom. Saya bermigrasi setelah ketiga kalinya saya mengimplementasikan ulang state checkpointing.
Sinyal utama kesiapan produksi. Dapatkah Anda menjawab pertanyaan-pertanyaan ini: Apa yang terjadi ketika pemanggilan alat habis waktu? Di mana log pemanggilan alat disimpan, dan dapatkah Anda mengkuerinya? Bagaimana sistem menangani respons alat yang merupakan JSON valid tetapi secara semantik salah? Dapatkah Anda mengulang sesi yang gagal dari checkpoint? Jika salah satu dari pertanyaan tersebut membuat Anda ragu, sistem belum siap untuk produksi.
Apa yang harus diukur sebelum Anda meningkatkan skala. Latensi per pemanggilan alat di bawah beban. Tingkat kesalahan per jenis alat. Konsumsi token per sesi (respons alat adalah pendorong utama). Ruang batas kecepatan pada 2x lalu lintas Anda saat ini. Saya mengabaikan metrik konsumsi token selama berminggu-minggu dan terkejut ketika saya benar-benar mengukurnya — respons alat menyumbang 60% dari total pengeluaran token saya.
FAQ
Apa itu penyambungan alat dalam sistem AI agentik?
Penyambungan alat mengacu pada lapisan integrasi penuh antara LLM dan alat-alat eksternal yang dapat dipanggilnya — termasuk penemuan alat, definisi skema, pelingkupan izin, logika pengiriman, penguraian respons, dan penanganan kesalahan. Ini adalah infrastruktur yang menentukan apakah keputusan model untuk “memanggil fungsi” benar-benar menghasilkan fungsi yang tepat dipanggil dengan benar. Model Context Protocol dibuat untuk menstandarisasi lapisan ini di berbagai aplikasi LLM.
Bagaimana cara mencegah perintah destruktif dalam alur kerja agentik?
Tingkatkan alat Anda berdasarkan tingkat risiko. Operasi hanya-baca dapat disetujui otomatis. Operasi tulis harus dicatat dengan kemampuan rollback. Operasi destruktif — apa pun yang menghapus data, mengirim komunikasi eksternal, atau memodifikasi status produksi — harus memerlukan konfirmasi manusia yang eksplisit. Gabungkan ini dengan sandboxing (gVisor atau microVM untuk eksekusi kode) dan kontrol egress jaringan yang memblokir koneksi keluar sembarang secara default.
Apa cara terbaik untuk menangani kegagalan pemanggilan alat dalam produksi?
Klasifikasikan kesalahan menjadi yang dapat dicoba ulang (batas kecepatan, habis waktu, 5xx) dan yang tidak dapat dicoba ulang (kegagalan autentikasi, kesalahan validasi, izin ditolak). Terapkan backoff eksponensial dengan jitter untuk kesalahan yang dapat dicoba ulang, dibatasi pada 2-3 percobaan. Untuk kesalahan yang tidak dapat dicoba ulang, kembalikan pesan kesalahan yang jelas ke model sehingga dapat menyesuaikan pendekatannya — atau eskalasi ke pengguna. Lapisi ini dengan circuit breaker yang mendeteksi ketika alat terus-menerus gagal dan merutekan di sekitarnya.
Bagaimana manajemen izin bekerja dalam agen multi-alat?
Setiap alat harus memiliki lingkup izin yang ditentukan: apa yang dapat diaksesnya, tindakan apa yang dapat dilakukannya, dan data apa yang dapat dikembalikannya. Dalam produksi, ini berarti kredensial berumur pendek per sesi (bukan kunci layanan bersama), pemeriksaan kemampuan eksplisit sebelum pengiriman, dan logging audit untuk setiap pemanggilan alat. Prinsipnya adalah hak istimewa terkecil — agen yang melakukan analisis teks tidak memerlukan akses tulis ke sistem file Anda.
Kapan saya harus menggunakan lapisan agentik terkelola vs. membangun sendiri?
Jika kasus penggunaan Anda melibatkan kurang dari lima alat dengan eksekusi sekuensial yang dapat diprediksi, bangun sendiri — lebih cepat di-debug dan dipelihara. Setelah Anda memerlukan perutean dinamis, eksekusi paralel, persistensi status, gerbang human-in-the-loop, atau koordinasi multi-agen, biaya rekayasa untuk membangun dan memelihara infrastruktur kustom melebihi kurva pembelajaran sebuah kerangka kerja. Faktor penentu biasanya adalah manajemen status: setelah sesi Anda perlu bertahan melalui restart proses, Anda memerlukan infrastruktur, bukan skrip.
Saya masih menyempurnakan model pembatasan izin. Tiga tingkat mungkin tidak cukup granular — beberapa operasi tulis terasa seperti seharusnya disetujui otomatis (menambahkan ke file log) sementara yang lain jelas tidak boleh (memperbarui catatan pelanggan). Batas tersebut terus bergeser seiring alur kerja menjadi lebih kompleks. Akan ada lebih banyak hal ke depannya.
Postingan sebelumnya:
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8
API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi
Harga GPT-5.4 Mini: Biaya Input, Cache & Output
API MAI-Image-2.5: Yang Perlu Diketahui Para Developer