Qu'est-ce que SkyReels V4 ? Le premier modèle IA vidéo-audio unifié expliqué
SkyReels V4 est le premier IA open-source qui génère vidéo et audio ensemble — en 1080p/32FPS. Voici ce qu'il fait, comment il fonctionne et pourquoi c'est important.

Bonjour, je m’appelle Dora. Ce jour-là, j’ai généré ma première vidéo **SkyReels V4**. Quinze secondes d’un chat marchant dans une ruelle détrempée par la pluie au crépuscule. La vidéo était réussie — 1080p, mouvement fluide, bel éclairage. Mais ce qui m’a fait marquer une pause, c’était l’audio. Des pas éclaboussant dans les flaques. La circulation au loin. Le léger écho des murs de la ruelle. Tout cela généré ensemble, synchronisé parfaitement, sans que je touche à un seul outil d’édition audio.
C’est ce détail qui semblait différent.
Le Problème que Chaque Outil de Vidéo IA Avait Avant V4
Pourquoi la génération vidéo seule a toujours semblé incomplète
La plupart des outils de vidéo IA génèrent des clips silencieux. Runway, Pika, même les versions précédentes de SkyReels — ils produisent des visuels et s’arrêtent là. Vous obtenez un magnifique plan de dix secondes de vagues se brisant sur une plage, mais il est complètement silencieux. Les vagues ne déferlent pas. Le vent ne souffle pas. Il n’y a aucun son ambiant.
Ce n’est pas un oubli technique. Générer de l’audio synchronisé avec la vidéo est véritablement difficile. L’audio doit correspondre non seulement à la scène générale, mais aussi à des événements visuels spécifiques — des pas qui retentissent quand les pieds touchent le sol, des portes qui claquent quand elles se ferment, des voix qui se synchronisent avec les mouvements des lèvres.
Le goulot d’étranglement du “ajout audio en post-production”
Le flux de travail standard était devenu : générer la vidéo, l’exporter, ouvrir un éditeur audio, ajouter des effets sonores ou de la musique manuellement, tout synchroniser à la main, puis exporter à nouveau. Pour un clip de 15 secondes, cela pouvait prendre 20 à 30 minutes.
J’ai essayé cela avec des sorties Pika le mois dernier. La vidéo avait l’air professionnelle. Mais trouver les bons sons ambiants, les synchroniser avec les repères visuels et éviter cette sensation d‘“ajout évident après coup” a consommé plus de temps que la génération de la vidéo elle-même. Le flux de travail semblait cassé — comme acheter une voiture mais devoir installer le moteur séparément.
Ce qu’est Réellement SkyReels V4
Développé par SkyworkAI (la lignée V1/V2/V3 expliquée)
SkyworkAI a publié SkyReels V1 début 2025 comme modèle basique de texte en vidéo. V2 a suivi avec une architecture de diffusion forcée permettant une génération de longueur infinie via des séquences autorégressives. V3 a été lancé en janvier 2026 avec un apprentissage en contexte multimodal — il était possible de lui fournir des images de référence, des clips audio ou des vidéos existantes, et il générait des continuations cohérentes.

V4, mis en ligne le 25 février 2026, représente un type de bond différent. Là où V3 ajoutait des fonctionnalités, V4 a restructuré l’ensemble de l’architecture autour d’un système à double flux qui génère simultanément vidéo et audio.
Ce que signifie vraiment “modèle de fondation vidéo-audio unifié”
Le document technique décrit V4 comme utilisant un Multimodal Diffusion Transformer (MMDiT) avec deux branches parallèles. Une branche synthétise les images vidéo. L’autre génère de l’audio temporellement aligné. Les deux branches partagent un encodeur de texte basé sur des grands modèles de langage multimodaux, ce qui signifie qu’ils traitent la même compréhension sémantique de votre prompt et maintiennent la synchronisation tout au long de la génération.
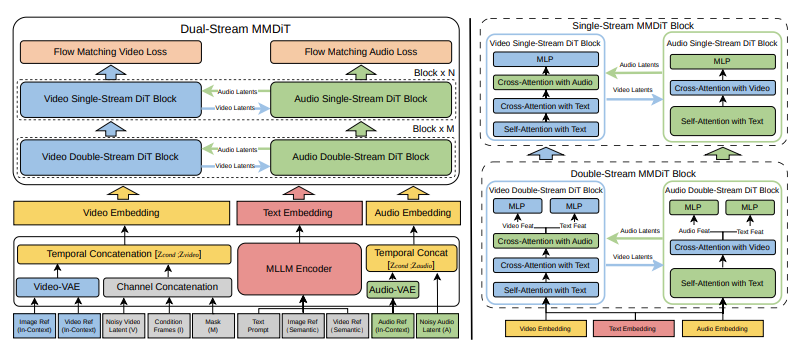
Ce n’est pas une génération vidéo avec de l’audio greffé dessus. C’est un modèle unique qui traite la vue et le son comme des sorties d’égale importance, générées ensemble à partir de la même compréhension latente de la scène.
En pratique, cela signifie que lorsque vous promptez “une femme qui parle à un podium”, le modèle génère à la fois le visuel de ses lèvres en mouvement et l’audio de la parole réelle, synchronisés au niveau de l’image. Lorsque vous générez “pluie forte sur un toit en métal”, vous obtenez à la fois le visuel de la pluie qui ruisselle et le son caractéristique de tambourinage métallique — pas approximativement assortis, mais générés comme un événement audiovisuel unifié.
Principales Capacités en un Coup d’Œil
Génération vidéo + audio conjointe à partir d’un seul prompt
La génération à partir d’un seul prompt est la capacité principale. Vous écrivez “tonnerre roulant sur un paysage désertique” et V4 produit 15 secondes de nuages qui se rassemblent, d’éclairs qui illuminent et de tonnerre synchronisé qui gronde en correspondant au timing visuel. Aucune étape de génération audio séparée. Aucun travail de synchronisation manuelle.
J’ai testé cela avec des scènes de dialogue. J’ai prompté “deux personnes se disputant dans un café animé” et j’ai obtenu non seulement le visuel de la conversation, mais aussi les bavardages en arrière-plan, le tintement des assiettes et les voix des interlocuteurs qui montaient et descendaient avec l’intensité de leurs gestes. La synchronisation labiale n’était pas parfaite — j’ai remarqué quelques instants où le timing déviait légèrement — mais c’était mieux que tout ce que j’avais synchronisé manuellement.
Sortie 1080p / 32 FPS / 15 secondes
Spécifications techniques : jusqu’à 1080p de résolution, 32 images par seconde, durée maximale de 15 secondes. Pour le contexte, la plupart des outils concurrents plafonnent à 720p ou nécessitent des temps de génération nettement plus longs pour une sortie HD.
La limite de 15 secondes importe plus qu’il n’y paraît. La plupart des contenus pour les réseaux sociaux se situent dans des tranches de 10 à 15 secondes. YouTube Shorts plafonne à 60 secondes. Instagram Reels à 90. Pour cet usage, 15 secondes avec audio synchronisé est plus utile que 30 secondes de vidéo silencieuse nécessitant une post-production.
Entrées multimodales : texte, image, vidéo, masque, référence audio
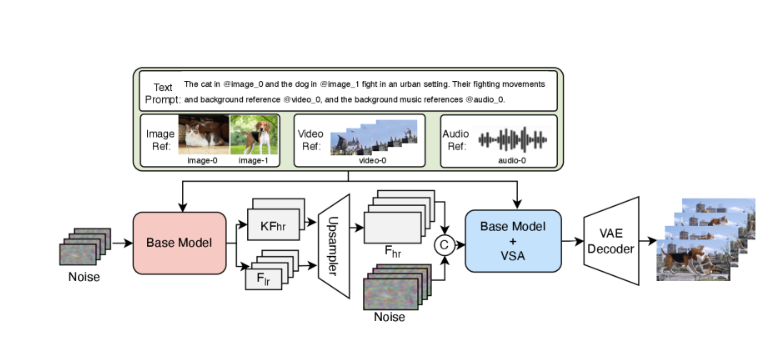
V4 accepte cinq types d’entrées : prompts textuels, images de référence, clips vidéo, masques binaires pour l’inpainting et références audio. Vous pouvez les combiner — télécharger une image d’une personne spécifique, fournir un échantillon audio de pas sur du gravier, et prompter “marchant dans une forêt à l’aube”. Le modèle utilise les trois entrées pour guider la génération.
J’ai testé le prompting multimodal avec une image de référence d’un style architectural spécifique et un clip audio d’ambiance de rue. La vidéo générée a conservé les détails architecturaux de l’image tout en intégrant les sons ambiants de la référence audio. Pas parfaitement — certains éléments audio semblaient génériques — mais la capacité a fonctionné.
Trois tâches en une : générer, inpeindre, modifier
Au-delà de la génération, V4 gère l’inpainting et l’édition via la concaténation de canaux. Fournissez une vidéo et un masque indiquant les régions à modifier, et le modèle régénère uniquement ces zones tout en préservant le reste. Cela permet des tâches comme supprimer des objets, changer les arrière-plans ou remplacer des éléments spécifiques sans régénérer l’intégralité du clip.
Comment V4 se Compare à ce qui Existait Avant
Évolution V4 vs SkyReels V1/V2/V3
V1 était uniquement texte en vidéo. V2 a ajouté la longueur via la diffusion forcée. V3 a introduit les entrées multimodales mais générait toujours de la vidéo sans audio natif. V4 est le premier à traiter l’audio comme une sortie de première classe générée simultanément avec la vidéo.
Qui Devrait S’intéresser à SkyReels V4 ?

Créateurs de contenu et cinéastes
Toute personne produisant du contenu court pour les plateformes sociales en bénéficie immédiatement. La compression du flux de travail — du prompt au clip audiovisuel fini — supprime le goulot d’étranglement qui donnait l’impression que les outils de vidéo IA créaient plus de travail qu’ils n’en épargnaient.
J’ai regardé un ami cinéaste utiliser V4 pour générer des plans de coupe pour un documentaire. Des prompts comme “time-lapse des lumières de la ville qui s’allument au crépuscule” ou “gros plan de pluie sur une vitre” avec des sons ambiants appropriés. Les sorties n’étaient pas indiscernables de vraies images, mais elles étaient suffisamment bonnes pour des plans de fond, et elles étaient prêtes en moins de 60 secondes chacune au lieu de nécessiter des tournages en extérieur ou des licences de vidéos de stock.
Développeurs construisant des pipelines vidéo
Si vous développez des applications qui génèrent ou manipulent de la vidéo, l’interface unifiée de V4 pour la génération, l’inpainting et l’édition simplifie la pile technologique. Au lieu d’enchaîner des modèles séparés pour la génération vidéo, la synthèse audio et la correction de synchronisation, un seul appel API gère l’ensemble du flux.
L’architecture du modèle est documentée en détail, et SkyworkAI a un historique de publication en open source de ses versions précédentes, ce qui suggère que l’accès pour les développeurs s’étendra. Les poids V3 sont déjà disponibles sur Hugging Face et GitHub.
Statut d’Accès Actuel et Ce qui Arrive
Au 2 mars 2026, V4 est en aperçu limité. Le site officiel propose un niveau gratuit avec des limites de génération quotidiennes, mais pas encore d’accès API. Sur la base du calendrier de V3 — qui est passé de la publication du document à l’API publique en environ deux semaines — je m’attendrais à une disponibilité plus large d’ici mi-mars.
Le document technique note que les travaux futurs incluent l’extension au-delà de 15 secondes et l’amélioration du contrôle audio fin. Ces limitations semblent importantes pour l’instant, en particulier le plafond de durée. Mais pour le problème spécifique que V4 résout — générer des clips audiovisuels courts et synchronisés sans post-production — il fonctionne mieux que tout ce que j’ai testé.
J’ai conservé V4 dans mon flux de travail depuis ce premier test. Pas pour tout — il y a encore des tâches où des images filmées ou des vidéos de stock sont plus appropriées. Mais pour des plans de coupe rapides, des scènes ambiantes ou des extraits pour les réseaux sociaux où l’audio synchronisé importe, V4 a suffisamment réduit les frictions pour que je l’utilise en premier maintenant.
L’architecture unifiée ressemble moins à une fonctionnalité incrémentale et davantage à la correction de quelque chose qui aurait dû fonctionner ainsi dès le début.
Articles associés

Claude Fable 5 vient de sortir : 80,3 % sur SWE-Bench Pro, prix 2× Opus 4.8, gratuit jusqu'au 22 juin

Comment choisir une API de médias IA pour les applications Codex (2026)

API Hunyuan 3D : Ce que les développeurs doivent savoir

Hunyuan 3D vs Hyper3D vs Pixal3D

Créer des applications vidéo IA avec des agents de codage
