WAN 2.7 Contrôle des Images Clés : Guide du Développeur
Comment utiliser le contrôle des images de début et de fin de WAN 2.7 pour une génération vidéo prévisible — préparation des entrées, paramètres API et conseils de workflow en production.

Hé, tout le monde, Dora arrive. Je voyais sans cesse des équipes décrire le contrôle première/dernière image comme “vous uploadez juste deux images.” C’est comme décrire les files d’attente de jobs asynchrones comme “vous attendez juste.” La mécanique n’est pas difficile — mais les décisions de conception des entrées sont là où la plupart des workflows de production s’effondrent silencieusement.
Ce guide est destiné aux développeurs qui ont besoin d’une sortie reproductible, pas juste d’une démo qui a fonctionné une fois.
Ce que fait réellement le contrôle Première et Dernière Image
Le problème qu’il résout par rapport à l’I2V standard
L’image-to-video (I2V) standard ancre le plan d’ouverture, puis le modèle improvise. Le résultat est ce que la communauté appelle souvent la “dérive” — le sujet, la position de la caméra ou l’éclairage divergent progressivement de tout état cible que vous aviez en tête. Pour les démonstrations de produits ou les séquences narratives avec un point final requis, cela coûte cher à corriger en post-production.
L’approche FLF2V de WAN utilise un mécanisme de réglage de contrôle supplémentaire : les premières et dernières images sont traitées comme des conditions de contrôle, et les caractéristiques sémantiques des deux images sont injectées dans le processus de génération. Cela maintient la cohérence du style, du contenu et de la structure tandis que le modèle se transforme dynamiquement entre elles.
Comment les deux images sont utilisées pendant la génération
Le modèle n’interpole pas simplement les valeurs de pixels. Il utilise les caractéristiques sémantiques CLIP et les mécanismes d’attention croisée pour maintenir la vidéo stable — cette conception a montré qu’elle réduit les saccades vidéo par rapport aux approches à ancrage unique. Votre première image définit l’état initial ; votre dernière image contraint la destination. Le chemin de mouvement entre elles est inféré, pas spécifié, ce qui constitue à la fois la puissance et le principal mode d’échec.
Ce que le modèle infère sur le chemin entre elles
Votre invite textuelle guide comment la transition se produit — pas seulement qu’elle se produit. Si votre invite dit “le produit tourne lentement et révèle sa face avant”, cette description de mouvement façonne le chemin inféré. Sans invite, le modèle tentera quand même une transition plausible, mais vous aurez beaucoup moins de contrôle sur les changements de direction, les mouvements de caméra ou le rythme.
Préparation des entrées
Exigences de spécification des images
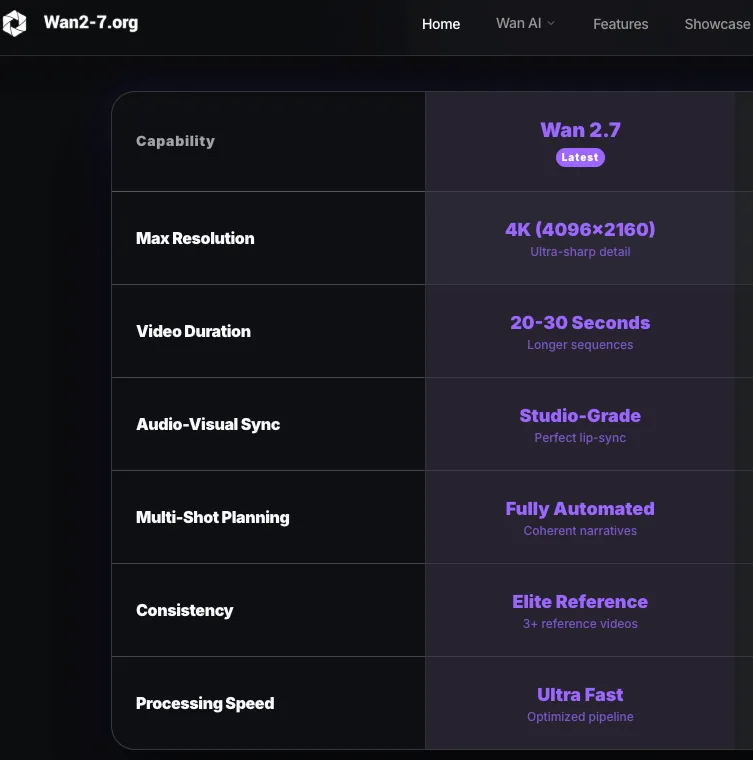
Le modèle utilise le ratio d’aspect de votre première image aussi proche que possible de votre sortie cible. Pour une entrée 3:4 (750×1000), un paramètre de sortie 720P produira quelque chose autour de 816×1104 — pas exactement 3:4. Si vous avez besoin de ratios exacts, prévoyez de recadrer ou d’ajouter des barres noires en post-production. Pour la série WAN en général, 720p (1280×720 ou équivalent portrait) est la résolution recommandée pour une sortie de qualité ; utiliser des résolutions plus petites est une stratégie valide pour les itérations de test mais pas pour les versions finales.
Format : PNG ou JPEG de haute qualité. Évitez les vignettes compressées comme premières/dernières images — les artefacts de compression introduisent du bruit que le modèle doit interpréter comme des informations visuelles intentionnelles.
Stratégies d’appariement d’images qui fonctionnent
Les paires les plus solides partagent trois choses : direction cohérente de la source lumineuse, caractéristiques de profondeur de champ correspondantes, et un sujet spatialement plausible dans les deux positions. Une photo de produit en lumière diffuse de studio associée à une image finale montrant le même produit sous un angle légèrement différent fonctionne bien. Un packshot vers une photo héro lifestyle fonctionne si la configuration d’éclairage est similaire.
Pour les séquences narratives, pensez à la paire comme définissant un verbe : ouvert → fermé, avant → après, en cours d’assemblage → complet. Plus la relation sémantique est claire, plus le chemin inféré est cohérent.
Ce qui constitue une mauvaise paire d’images
Trois coupables courants :
Direction d’éclairage incohérente. Si votre première image a la lumière principale à 45° gauche et que votre dernière image a été prise avec une lumière zénithale, le modèle tentera de faire une transition entre deux environnements d’ombres différents. Le résultat est généralement un saut de source lumineuse au milieu du clip qui ressemble à une erreur de rendu.
Inadéquation spatiale. Un plan large d’établissement associé à un gros plan serré oblige le modèle à inventer un mouvement de caméra. Parfois c’est intentionnel ; généralement ce n’est pas le cas. Gardez la distance focale approximativement cohérente à moins que vous ne demandiez explicitement un zoom avant ou arrière.
Indices de profondeur conflictuels. Bokeh dans la première image, tout net dans la dernière — le modèle interprétera cela comme un changement de profondeur de champ et essaiera de l’animer. Ce n’est pas toujours faux, mais c’est rarement ce que vous aviez l’intention.
Implémentation API
Ce qui suit reflète le modèle FLF2V documenté pour la série WAN. Vérifiez les noms de paramètres actuels et les chemins d’endpoint dans la documentation Alibaba Cloud Model Studio avant utilisation en production. Les spécificités de l’API WAN 2.7 doivent être confirmées au lancement.
Structure du payload
Le modèle de base implique deux entrées d’images — l’une via URL publique ou chemin de fichier local — passées comme first_frame_url et last_frame_url, accompagnées d’une invite textuelle et d’un paramètre de résolution.
Modèle de requête Python (Pseudocode)
# Vérifiez le nom du modèle et l'endpoint au lancement — les noms changent selon les versions
import os
from dashscope import VideoSynthesis
response = VideoSynthesis.async_call(
model="wan2.x-flf2v-<vérifier-au-lancement>", # confirmez la chaîne exacte du modèle
first_frame_url="https://your-cdn.com/start.png",
last_frame_url="https://your-cdn.com/end.png",
prompt="Caméra fixe. Commencer à partir de la première image, terminer à la dernière image. [décrire le mouvement]",
negative_prompt="scintillement, déformation, flou",
resolution="720P", # vérifiez les valeurs acceptées
# paramètre seed : verrouillez-le une fois que vous avez un bon résultat
)
task_id = response.output.task_idGestion asynchrone pour les jobs plus longs
Les tâches de génération image-to-video prennent généralement 1 à 5 minutes. L’API utilise un modèle asynchrone en deux étapes : soumettez la tâche, obtenez un ID de tâche, puis interrogez pour le résultat. Intégrez l’interrogation dans votre pipeline dès le début. Ne supposez pas un comportement synchrone même pour les appels de test — les délais d’attente supprimeront silencieusement les résultats dans les implémentations naïves.
Workflow de production : méthode brouillon-vers-final
Étape 1 — Construire une paire de référence et effectuer un test
Commencez avec une seule paire. Ne traitez pas en lot jusqu’à ce que vous ayez vu une sortie de bout en bout. Utilisez votre contenu cible — pas des images de stock de substitution — car les caractéristiques spatiales et d’éclairage doivent représenter votre bibliothèque d’assets réelle.
Étape 2 — Valider le chemin de mouvement avant le traitement par lot
Regardez le clip complet une fois à vitesse 0,5x. Cherchez : les saccades en milieu de clip, la dérive d’identité du sujet autour des images 50 à 70% dans le clip (c’est là que se concentrent la plupart des artefacts), et les discontinuités d’éclairage. Si vous en voyez, corrigez la paire d’entrée avant de toucher à l’invite.
Étape 3 — Verrouiller votre meilleure seed pour la cohérence
Une fois que vous avez une sortie propre, enregistrez la valeur de la seed. Le modèle FLF2V accepte une invite optionnelle pour guider la logique d’action intermédiaire et de transformation. Une seed verrouillée plus une invite verrouillée vous donne une unité de génération reproductible que vous pouvez appliquer à travers des paires d’entrée similaires. C’est ce qui rend la production par lot prévisible plutôt que probabiliste.
Étape 4 — Passer à la génération par lot
Structurez votre lot comme suit : une “paire de test” canonique qui sert d’ancre de qualité, puis des paires de variantes générées à partir du même setup de prise de vue contrôlé. La page du modèle Hugging Face pour WAN FLF2V documente la version open-weight pour les équipes exécutant une inférence locale en parallèle des appels API.
Où cette fonctionnalité s’applique (et où elle ne s’applique pas)
Idéal pour : les séquences de démonstration de produits où le point final est important (packshot → révélation de caractéristique), les plans de continuité narrative avec un avant/après défini, les chemins de caméra contrôlés où vous avez besoin de stabilité spatiale à travers plusieurs clips d’une série.
Pas idéal pour : les mouvements très dynamiques avec des changements de direction brusques (le modèle les lissera, perdant souvent le dramatisme), les transitions spatiales ambiguës où les premières et dernières images ne partagent pas une relation sémantique claire, ou les scénarios nécessitant un timing précis à la frame — le modèle contrôle le rythme, pas vous.
Modèles d’échec courants et correctifs
Artefact de mouvement en milieu de clip. Causé généralement par une inadéquation spatiale dans la paire d’entrée. Le modèle “s’engage” dans un chemin d’interpolation tôt, et l’incohérence se manifeste autour du point médian. Correctif : resserrez la relation entre les images avant de changer l’invite.
Incohérence de style entre les images. Si votre première image est un rendu stylisé et que votre dernière est une photographie, le modèle essaiera de mélanger les styles visuels. Cela produit rarement une sortie propre. Faites correspondre le traitement des images — les deux en rendu, les deux en photo, les deux en illustration.
Le modèle ignore la dernière image. Cela se produit lorsque l’invite décrit un mouvement qui ne peut pas logiquement se terminer à votre dernière image. Le modèle priorise la cohérence de l’invite par rapport à la conformité aux images lorsqu’elles sont en conflit. Rédigez votre invite pour arriver à la dernière image, pas seulement pour partir de la première.
FAQ
- Puis-je utiliser la première/dernière image avec le texte-to-video ou seulement l’I2V ? Le mode FLF2V est une extension de l’I2V. Les deux entrées d’images sont requises. Le T2V standard n’accepte pas les contraintes d’image finale par conception.
- Quel format d’image fonctionne le mieux pour les entrées d’images ? PNG pour tout ce qui nécessite des bords nets ou une gestion de la transparence. Le JPEG de haute qualité (>90 qualité) convient pour la photographie. Évitez le WebP si votre plateforme n’a pas confirmé la prise en charge.
- Est-ce que cela coûte plus cher que l’I2V standard ? La tarification dépend de la résolution — le 720p coûte environ deux fois plus que le 480p par génération. Le FLF2V lui-même ne porte pas de prime séparée dans la tarification documentée, mais confirmez avec votre plateforme spécifique.
- Comment gérer les mouvements nécessitant des changements de direction brusques ? Divisez la séquence en plusieurs clips avec des images intermédiaires comme points finaux. Chaînez-les en post-production plutôt que d’essayer d’obtenir une seule génération pour gérer un mouvement discontinu.
- Puis-je combiner cela avec le mode d’entrée en grille 9 ? Ce sont des modes d’entrée séparés. WAN 2.7 prend en charge le contrôle première/dernière image et l’image-to-video en grille 9 comme fonctionnalités distinctes. Ils ne sont actuellement pas combinés dans un seul appel — vérifiez au lancement si cela change.
Conclusion
L’espace de conception intéressant avec le contrôle première/dernière image n’est pas l’appel API — c’est la paire d’entrée. C’est là que se trouve le véritable levier de production, et c’est là que la plupart des équipes sous-investissent. Une paire d’images bien conçue avec une relation sémantique claire surpassera systématiquement une invite parfaite associée à une entrée mal assortie.
Pour les équipes construisant des pipelines par lot : traitez votre bibliothèque de paires d’entrée comme un asset de premier ordre, pas comme une réflexion après coup. Une fois que vous avez une seed verrouillée et un format de paire validé, le côté génération devient routinier. La communauté ComfyUI a documenté les configurations de workflow WAN FLF2V en détail si vous exécutez également une inférence locale en parallèle des appels API — vaut la peine d’être lu pour l’insight au niveau des nœuds sur la façon dont le conditionnement par image fonctionne réellement.
Je reviens sans cesse à quelque chose de discret ici : la contrainte est la fonctionnalité. Donner au modèle une destination vous oblige à être précis sur ce que vous voulez réellement. Ce n’est pas une limitation — c’est une discipline qui tend à produire de meilleures sorties que la génération ouverte ne le fait jamais.
Continuez à explorer les workflows vidéo IA :
- Voyez comment le contrôle première/dernière image se compare à d’autres modèles de génération vidéo
- Comprenez comment maintenir la cohérence des personnages à travers les clips vidéo générés
- Explorez les cas d’utilisation réels pour la génération vidéo IA dans les workflows de production
- Apprenez comment les entrées de référence multi-images améliorent le contrôle de génération
- Voyez comment les pipelines image-to-video sont utilisés à travers différents outils
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir